Poradniki
·
10 min czytania
·
8 czerwca 2026
Jak ocenić, czy fine-tuning AI ma sens w Twojej firmie

Źródło: Link
Źródło: Link
Audyty, wdrożenia, szkolenia sprzedażowe i AI. Dopasowane do zespołu i procesów.
Największy mit? Że gdy model nie działa idealnie, trzeba go od razu douczyć. Nie. Często problem leży w danych, instrukcji albo w tym, że próbujesz wkręcić śrubę młotkiem.
Ten poradnik jest dla Ciebie, jeśli używasz AI w pracy i zastanawiasz się, czy iść w fine-tuning, czy zostać przy prostszym rozwiązaniu. Rozbijmy to na czynniki pierwsze: kiedy wystarczy RAG, kiedy ma sens fine-tuning, ile to kosztuje organizacyjnie i jak podejść do tego przez OpenAI fine-tuning API bez chaosu.
Zanim wejdziesz w fine-tuning, przygotuj kilka rzeczy. Bez tego łatwo przepalić czas, budżet i cierpliwość.
Jeśli dopiero układasz sobie podstawy pracy z modelami, zacznij od AI dla początkujących: planu 7 dni. Fine-tuning to etap później, nie pierwszy krok.
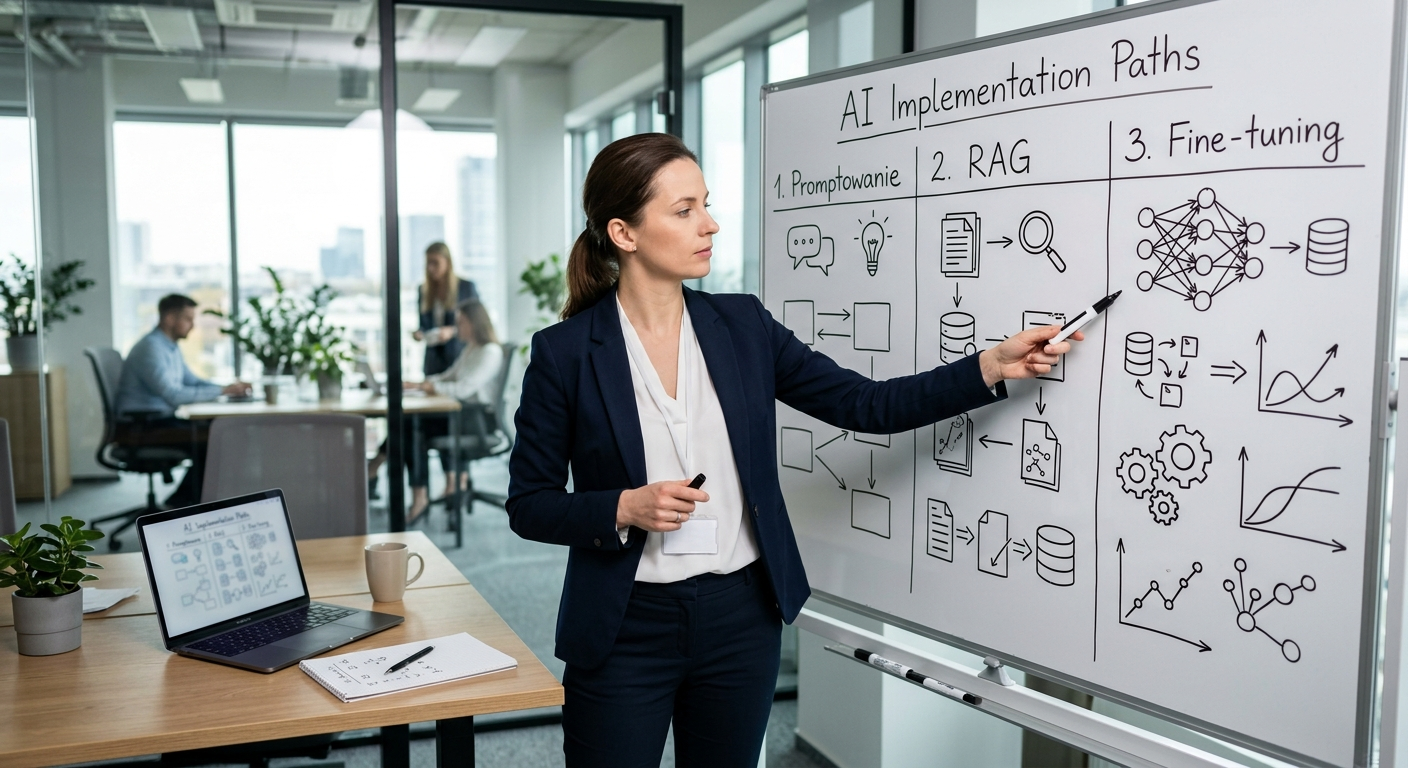
Fine-tuning to nie magiczny przycisk „napraw model”. To sposób na dostrojenie zachowania modelu do konkretnego zadania na bazie przykładów. Ma sens wtedy, gdy model ma wykonywać powtarzalną pracę w określony sposób i zwykły prompt nie daje stabilnych wyników.
Jeśli Twoim celem jest głównie podawanie modelowi aktualnej wiedzy z dokumentów, procedur, ofert albo bazy wiedzy, częściej wygrywa RAG. Model nie uczy się tych danych na stałe, tylko dostaje je w momencie odpowiedzi. To prostsze, bezpieczniejsze i zwykle szybsze do wdrożenia.
Jeśli budujesz bota na stronę firmową, najpierw przeczytaj jak wdrożyć chatbot AI na stronie firmowej bez chaosu. W wielu takich wdrożeniach RAG daje więcej niż trenowanie modelu.
Sprawdzam: najczęściej firmy mylą dwa problemy. Pierwszy to „model nie zna naszych danych”. Drugi to „model zna zadanie, ale robi je za każdym razem trochę inaczej”. Pierwszy częściej rozwiązuje RAG. Drugi - fine-tuning.
Zamiast pytać „czy fine-tuning jest nowocześniejszy?”, zadaj sobie trzy prostsze pytania. Odpowiedzi szybko ustawiają temat na właściwe tory.
Jeśli model nie zna Twoich dokumentów, potrzebujesz dostępu do danych. Jeśli model zna temat, ale odpowiada niespójnie, gubi format albo nie trzyma tonu, wtedy myślisz o fine-tuningu.
To ważne rozróżnienie. Fine-tuning nie jest magazynem wiedzy firmowej. Jest raczej sposobem uczenia modelu, jak ma odpowiadać, a nie tylko co ma wiedzieć.
Fine-tuning żywi się przykładami. Jeśli Twoje dane są chaotyczne, sprzeczne albo słabe jakościowo, model nauczy się chaosu. AI nie robi tu cudu. Uporządkuje bałagan najwyżej w eleganckie błędy.
Przygotuj mały test. Zbierz przykłady najlepszych odpowiedzi, jakie człowiek stworzyłby w danym zadaniu. Jeśli trudno Ci wskazać, co jest „dobrą odpowiedzią”, to sygnał ostrzegawczy.
Sam trening to tylko fragment kosztu. Dochodzi selekcja danych, czyszczenie, testy, poprawki i porównanie wyników. Często największym wydatkiem nie jest API, tylko czas ludzi w firmie.
Jeśli zadanie zdarza się rzadko albo każda odpowiedź jest bardzo inna, fine-tuning może się nie spiąć. Jeśli zadanie jest powtarzalne i ręcznie poprawiasz to samo codziennie - wtedy robi się ciekawie.

Tu rozgrywa się większość sukcesu albo porażki. Nie w samym API. W danych. Jeśli chcesz zrobić to dobrze, idź tą ścieżką.
Dobry przykład jest konkretny i nie zostawia pola do zgadywania. Jeśli uczysz model odpowiadania na wiadomości klientów, pokaż pełną wiadomość wejściową i gotową odpowiedź, którą naprawdę chcesz otrzymywać.
Jeśli uczysz klasyfikacji, zadbaj o jasne etykiety i spójną logikę. Jeden rekord nie może oznaczać „pilne”, a drugi podobny „standard”, jeśli nie ma czytelnej zasady.
Przydaje się też krótka dokumentacja decyzji. Jedno zdanie obok zbioru typu: „odpowiedzi mają być krótkie, rzeczowe i bez żargonu” potrafi uratować godziny poprawek.
Jeśli pracujesz z promptami i nadal szukasz stabilności odpowiedzi, przyda Ci się też tekst jak wybrać między Claude a ChatGPT. Czasem zmiana narzędzia daje większy efekt niż trenowanie obecnego modelu.
Źródło wskazuje wprost na OpenAI fine-tuning API, więc trzymajmy się praktyki. Nie będę udawał, że to „klik i gotowe”, bo potem przychodzi zderzenie ze ścianą. Da się to ogarnąć, tylko trzeba iść etapami.
Jeśli jesteś bardziej techniczny albo współpracujesz z kimś, kto testuje modele przez terminal, pomocny będzie też poradnik jak zacząć kodować z Claude Code w terminalu. Nawet przy pracy bez kodowania dobrze rozumieć, jak wygląda testowanie modeli od kuchni.
Krok 1: otwierasz panel projektu i tworzysz folder na dane treningowe.
Krok 2: zapisujesz przykłady w jednym formacie i oznaczasz wersję zbioru.
Krok 3: wgrywasz plik do OpenAI i uruchamiasz zadanie fine-tuningu.
Krok 4: po zakończeniu porównujesz odpowiedzi: model bazowy vs model po fine-tuningu.
Krok 5: notujesz różnice w arkuszu: format, poprawność, czas ręcznej poprawy.
Źródło sygnalizuje temat kosztu, ale nie podaje konkretnych stawek, więc uczciwie: największym kosztem bywa przygotowanie danych i testów. Samo API to tylko część układanki.
Policz trzy rzeczy: czas ludzi, koszt błędnych odpowiedzi i częstotliwość użycia zadania. Jeśli poprawiasz wyniki modelu ręcznie przez kilka minut dziennie, fine-tuning może się nie opłacić. Jeśli ten sam błąd wraca setki razy, sytuacja wygląda inaczej.
W polskich firmach ten temat jest szczególnie praktyczny. Często nie brakuje narzędzi, tylko czasu zespołu na uporządkowanie danych i sensowny pilotaż.
RAG wybierasz wtedy, gdy model ma korzystać z dokumentów, procedur albo bazy wiedzy, które się zmieniają. Fine-tuning lepiej sprawdza się wtedy, gdy chcesz ustawić sposób działania modelu, styl odpowiedzi albo stały format wyniku.
Nie w taki sposób, jak wiele osób zakłada. Jeśli chcesz, by model odpowiadał na podstawie aktualnych materiałów firmowych, częściej lepszy będzie RAG i dobrze przygotowane źródła danych.
Potrzebujesz przykładów wejście - wyjście, które pokazują dokładnie, jakiej odpowiedzi oczekujesz. Dane muszą być spójne, oczyszczone i dopasowane do jednego konkretnego zadania.
Tak, ale wygodniej pracuje się wtedy z kimś, kto pomoże przy przygotowaniu formatu danych i testach. Osoba nietechniczna nadal może prowadzić cały proces merytorycznie: wybrać zadanie, zebrać przykłady, ocenić jakość i zdecydować, czy wynik ma sens biznesowo.
Po porównaniu wyników na nowych danych i po realnym efekcie w pracy zespołu. Jeśli odpowiedzi są bardziej spójne, wymagają mniej poprawek i oszczędzają czas przy powtarzalnym zadaniu, wtedy masz twardy argument, a nie tylko dobre wrażenie.
Ten poradnik to dopiero poczatek. W naszym kursie "Praktyczna AI" nauczysz sie korzystac z ChatGPT, Claude i innych narzedzi AI w sposob systematyczny - od zera do zaawansowanego poziomu.
Sprawdz kurs →Fine-tuning ma sens wtedy, gdy rozwiązujesz konkretny, powtarzalny problem i masz dobre dane. Jeśli chcesz tylko „żeby AI było mądrzejsze”, to za mało. Najpierw diagnoza, potem dane, dopiero na końcu trening.
Jeden krok na start: weź jedno zadanie w swojej pracy i zapisz w dwóch kolumnach: „problem z wiedzą” albo „problem z zachowaniem modelu”. Ta prosta decyzja od razu pokaże, czy iść w RAG, czy w fine-tuning.
Na podstawie: SukcesAI Tutorial Generator
Podoba Ci się ten artykuł?
Co piątek wysyłam podsumowanie najlepszych artykułów tygodnia. Zapisz się!
90 minut praktycznej wiedzy o AI. Pokaze Ci krok po kroku, jak zaczac oszczedzac 10 godzin tygodniowo dzieki sztucznej inteligencji.
Zapisz sie na webinar
Fine-tuning brzmi skomplikowanie, ale może być prostszy niż myślisz. Dowiedz się, kiedy ma sens, ile kosztuje i jak to zrobić przez OpenAI API.

Fine-tuning SpeechT5 to sposób, by model mowy rozumiał Twój głos, język czy akcent. Sprawdź, jak to zrobić bez kodowania i kiedy warto zainwestować czas.

Fine-tuning modelu BERT to jak nauczenie go Twojego branżowego żargonu. Pokazuję, jak to zrobić bez kodowania - krok po kroku, z konkretnymi narzędziami.

Podział dokumentów na fragmenty to fundament skutecznego RAG. Dowiedz się, jak to zrobić praktycznie - od wyboru strategii po testowanie wyników.

Regresja logistyczna brzmi skomplikowanie, ale to podstawa AI, która działa w Twoim telefonie. Sprawdź, jak działa i gdzie ją wykorzystasz - bez matematyki.

Struktura promptu, dobór stylu, parametry techniczne i negatywne prompty - wszystko, czego potrzebujesz, by AI narysowało dokładnie to, co masz w głowie.
