Poradniki
·
10 min czytania
·
5 kwietnia 2026
Jak wybrać funkcję straty dla modelu ML – przewodnik po 5 typach

Źródło: Link
Źródło: Link
90 minut praktyki. Co tydzień na żywo.
Trenowanie modelu uczenia maszynowego to proces prób i błędów. Model przewiduje wynik, porównuje go z rzeczywistością, oblicza błąd i koryguje parametry. Ale kto decyduje, jak bardzo ten błąd boli? Funkcja straty.
To ona tłumaczy różnicę między przewidywaniem a prawdą na sygnał, który model rozumie — i na którym może się uczyć. Różne funkcje straty zachowują się zupełnie inaczej. Jedna karze duże błędy jak młotem, inna pozostaje spokojna nawet przy szumie w danych. Wybór niewłaściwej funkcji? Model może się uczyć w złym kierunku.
Poniżej znajdziesz praktyczny przewodnik po pięciu najważniejszych typach funkcji straty — kiedy ich używać, jak działają i dlaczego wybór ma znaczenie.
Ten przewodnik zakłada, że masz podstawową wiedzę o uczeniu maszynowym — wiesz, czym jest model, trening i predykcja. Nie musisz znać matematyki na poziomie akademickim, ale pomoże Ci zrozumienie, że:
Jeśli dopiero zaczynasz przygodę z ML, zerknij na nasz przewodnik dla początkujących w Data Science — tam znajdziesz podstawy.
MSE to najpopularniejsza funkcja straty w zadaniach regresji. Działa prosto: bierze różnicę między przewidywaniem a rzeczywistą wartością, podnosi ją do kwadratu i uśrednia po wszystkich przykładach.
Jak to wygląda w praktyce?
Załóżmy, że Twój model przewiduje ceny mieszkań. Jeśli pomyli się o 10 000 zł, błąd wynosi 100 000 000 (10 000²). Jeśli pomyli się o 100 000 zł, błąd to 10 000 000 000. Różnica? Stukrotna. MSE karze duże błędy nieproporcjonalnie mocno.
Kiedy używać MSE:
Kiedy NIE używać MSE:
W bibliotece Keras MSE to domyślna funkcja dla regresji:
model.compile(optimizer='adam', loss='mean_squared_error')W PyTorch:
import torch.nn as nn
criterion = nn.MSELoss()MAE to bardziej wyrozumiała wersja MSE. Zamiast podnosić błąd do kwadratu, po prostu bierze jego wartość bezwzględną. Błąd o 10 000 zł to błąd o 10 000 zł — nie 100 000 000.
Dlaczego to ma znaczenie?
Jeśli w Twoich danych pojawi się wartość odstająca (np. mieszkanie sprzedane za 10 mln zł w dzielnicy, gdzie średnia to 500 tys.), MSE wpadnie w panikę. MAE wzruszy ramionami i potraktuje to jak kolejny błąd.
Kiedy używać MAE:
Kiedy NIE używać MAE:
Keras:
model.compile(optimizer='adam', loss='mean_absolute_error')PyTorch:
criterion = nn.L1Loss()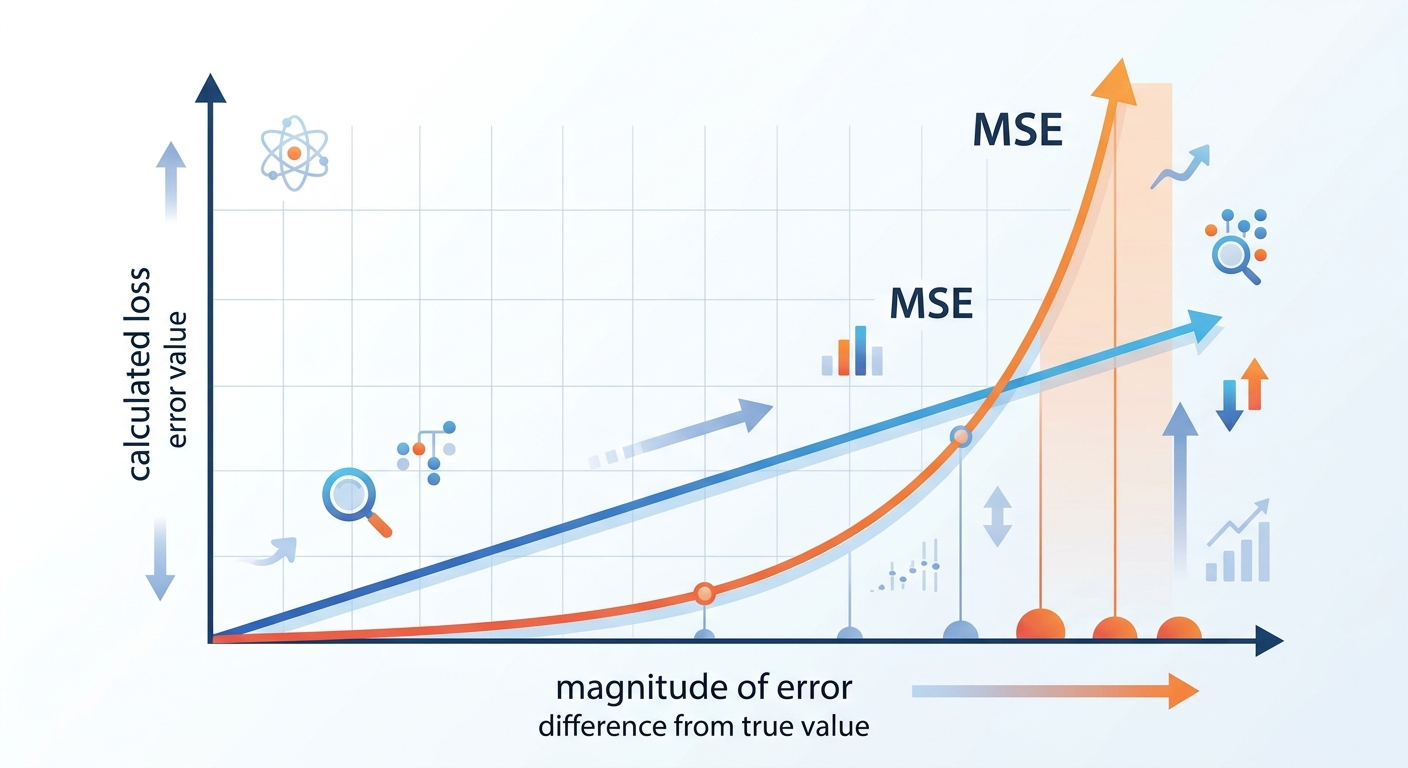
Kiedy Twój model ma odpowiedzieć "tak" lub "nie" (spam/nie-spam, chory/zdrowy, kliknie/nie-kliknie), potrzebujesz funkcji, która mierzy, jak bardzo pewny jest model swojej odpowiedzi.
Binary Cross-Entropy (BCE) robi dokładnie to. Karze model nie tylko za błędną odpowiedź, ale też za brak pewności przy poprawnej.
Jak to działa?
Model nie mówi "to spam" — mówi "jestem w 87% pewien, że to spam". BCE porównuje tę pewność z rzeczywistością (0 lub 1) i karze za rozbieżność. Im bardziej model się myli, tym większa strata.
Kiedy używać BCE:
Pułapka dla początkujących:
BCE wymaga, żeby ostatnia warstwa modelu miała funkcję aktywacji sigmoid (która zwraca wartości 0-1). Jeśli zapomnisz o sigmoid, model zwróci dowolne liczby i strata będzie bez sensu.
Keras:
model.compile(optimizer='adam', loss='binary_crossentropy')PyTorch:
criterion = nn.BCELoss() # wymaga sigmoid w ostatniej warstwie
# lub
criterion = nn.BCEWithLogitsLoss() # sigmoid wbudowanyMasz więcej niż dwie kategorie? (np. rozpoznawanie cyfr 0-9, klasyfikacja gatunków zwierząt, sentiment analysis z 3 opcjami). Categorical Cross-Entropy to rozszerzenie BCE na wiele klas.
Jak to działa?
Model zwraca wektor prawdopodobieństw dla każdej klasy (np. [0.7, 0.2, 0.1] dla trzech kategorii). CCE porównuje ten wektor z rzeczywistą klasą (zakodowaną jako one-hot: [1, 0, 0]) i karze za rozbieżność.
Kiedy używać CCE:
Wariant: Sparse Categorical Cross-Entropy
Jeśli Twoje etykiety są liczbami (0, 1, 2...) zamiast wektorów one-hot ([1,0,0], [0,1,0]...), użyj sparse CCE. Robi to samo, ale oszczędza pamięć.
Keras (one-hot labels):
model.compile(optimizer='adam', loss='categorical_crossentropy')Keras (integer labels):
model.compile(optimizer='adam', loss='sparse_categorical_crossentropy')PyTorch (integer labels, softmax wbudowany):
criterion = nn.CrossEntropyLoss()Jeśli chcesz lepiej zrozumieć, jak uruchomić gotowy model w aplikacji webowej, mamy osobny przewodnik.
MSE karze duże błędy za mocno. MAE karze je za słabo. Huber Loss to złoty środek — zachowuje się jak MSE przy małych błędach (gładka optymalizacja) i jak MAE przy dużych (odporność na outliery).
Jak to działa?
Huber ma parametr delta (δ), który definiuje próg. Poniżej δ funkcja zachowuje się jak MSE (kwadratowa), powyżej — jak MAE (liniowa). Typowa wartość δ to 1.0, ale możesz ją dostosować do swoich danych.
Kiedy używać Huber Loss:
Kiedy NIE używać Huber Loss:
Keras:
model.compile(optimizer='adam', loss='huber')PyTorch:
criterion = nn.HuberLoss(delta=1.0)Decyzja sprowadza się do trzech pytań:
Przykład: budujesz model przewidujący ceny nieruchomości. Dane zawierają kilka luksusowych apartamentów (outliery), ale duże błędy w przewidywaniu mogą kosztować klienta tysiące. Rozwiązanie? Huber Loss z δ=0.5 — będzie karał duże błędy, ale nie da się zdominować przez pojedyncze ekstremalne wartości.
Teoria to jedno, praktyka drugie. Najlepszy sposób na wybór funkcji straty? Przetestuj kilka i porównaj wyniki na zbiorze walidacyjnym. W Keras możesz łatwo zmienić funkcję straty bez przebudowy modelu:
# Test 1: MSE
model.compile(optimizer='adam', loss='mse', metrics=['mae'])
history_mse = model.fit(X_train, y_train, validation_split=0.2, epochs=50)
# Test 2: MAE
model.compile(optimizer='adam', loss='mae', metrics=['mse'])
history_mae = model.fit(X_train, y_train, validation_split=0.2, epochs=50)
# Porównaj wyniki na validation setJeśli dopiero zaczynasz pracę z modelami, sprawdź nasz przewodnik po ChatGPT">ChatGPT w codziennej pracy — AI może pomóc Ci debugować kod i tłumaczyć błędy.
1. Niezbalansowane klasy w klasyfikacji
Jeśli masz 95% przykładów klasy A i 5% klasy B, standardowa Cross-Entropy pozwoli modelowi nauczyć się "zawsze mów A" i osiągnąć 95% accuracy. Rozwiązanie? Użyj ważonej funkcji straty:
# PyTorch
weights = torch.tensor([0.05, 0.95]) # odwrotność częstości
criterion = nn.CrossEntropyLoss(weight=weights)2. Zapomnienie o normalizacji danych
MSE jest wrażliwa na skalę. Jeśli przewidujesz ceny w złotych (0-1 000 000) bez normalizacji, błędy będą ogromne i model będzie się męczył. Zawsze normalizuj dane wejściowe i wyjściowe do zakresu [0, 1] lub [-1, 1].
3. Użycie złej funkcji aktywacji na wyjściu
Binary Cross-Entropy wymaga sigmoid. Categorical Cross-Entropy wymaga softmax. Jeśli zapomnisz, model zwróci nonsens. Keras czasem dodaje to automatycznie (np. from_logits=True), ale w PyTorch musisz to kontrolować ręcznie.
Tak, to się nazywa multi-task learning. Możesz zdefiniować własną funkcję, która łączy np. MSE dla regresji i BCE dla klasyfikacji. W Keras:
def combined_loss(y_true, y_pred):
mse = tf.keras.losses.MSE(y_true[:, 0], y_pred[:, 0])
bce = tf.keras.losses.BinaryCrossentropy(y_true[:, 1], y_pred[:, 1])
return mse + bce
model.compile(optimizer='adam', loss=combined_loss)Niska strata na zbiorze treningowym ≠ dobry model. Sprawdź stratę na zbiorze walidacyjnym. Jeśli rośnie, masz overfitting. Jeśli obie są niskie, ale model działa słabo, problem leży gdzie indziej (np. złe dane, zła architektura, zły preprocessing).
Niekoniecznie. Funkcja straty musi być różniczkowalna (żeby gradient descent działał). Metryka ewaluacji może być dowolna (np. accuracy, F1-score). Przykład: w klasyfikacji używasz Cross-Entropy jako loss, ale mierzysz sukces przez accuracy.
Focal Loss to wariant Cross-Entropy zaprojektowany dla ekstremalnie niezbalansowanych klas (np. detekcja obiektów, gdzie 99.9% pikseli to tło). Karze mocniej błędy na trudnych przykładach, ignorując łatwe. Używaj, gdy masz bardzo rzadką klasę pozytywną.
Tak. W Keras i PyTorch możesz zdefiniować dowolną funkcję, która przyjmuje y_true i y_pred i zwraca skalar. Upewnij się tylko, że jest różniczkowalna (używa operacji tensorowych, nie pętli Pythona).
Ten poradnik to dopiero początek. W naszym kursie "Praktyczna AI" nauczysz się korzystać z ChatGPT, Claude i innych narzędzi AI w sposób systematyczny — od zera do zaawansowanego poziomu.
Sprawdź kurs →Wybór funkcji straty to nie czarna magia — to decyzja oparta na typie zadania, charakterystyce danych i tym, co chcesz osiągnąć. MSE karze duże błędy, MAE traktuje wszystkie równo, Huber łączy oba podejścia. Cross-Entropy działa dla klasyfikacji, z wariantami dla dwóch lub wielu klas.
Nie ma jednej uniwersalnej odpowiedzi. Najlepszy sposób na naukę? Weź swój dataset, przetestuj trzy funkcje straty i porównaj wyniki. Zobaczysz różnicę w praktyce — nie w teorii.
Otwórz swój ostatni projekt ML. Sprawdź, jakiej funkcji straty używasz. Czy to świadomy wybór, czy domyślna wartość z tutoriala? Jeśli drugie — przetestuj alternatywę. Może właśnie odkryjesz, dlaczego model nie działał tak dobrze, jak chciałeś.
Na podstawie: Analytics Vidhya
90 minut praktycznej wiedzy o AI. Pokaze Ci krok po kroku, jak zaczac oszczedzac 10 godzin tygodniowo dzieki sztucznej inteligencji.
Zapisz sie na webinar
Chunking to podział dokumentów na fragmenty, które AI może przetworzyć. Dowiedz się, jak rozbić dane, by RAG działał skutecznie – z konkretnymi przykładami i technikami.

GPT-OSS-Safeguard to system ochrony modeli AI przed wyciekami i niewłaściwym wykorzystaniem. Sprawdź, jak działa i dlaczego potrzebujesz go w swojej organizacji.

Kompletny poradnik używania ChatGPT do maili, raportów, analizy danych i automatyzacji zadań. Konkretne kroki, gotowe prompty i sprawdzone techniki.
