Poradniki
·
9 min czytania
·
30 marca 2026
Aplikacja webowa z ML. Przewodnik krok po kroku

Źródło: Link
Źródło: Link
118 lekcji bez kodowania. ChatGPT, Claude, Gemini, automatyzacje. Notatnik AI i AI Coach w cenie.
Kolega z działu IT pochwalił się wczoraj, że "wrzucił model na produkcję". Skinąłeś głową, jakbyś wiedział, o co chodzi. Prawda jest inna: masz gotowy model ML, który działa na Twoim laptopie - i nie masz pojęcia, jak sprawić, żeby ktokolwiek mógł z niego korzystać.
Znam to. Sam stałem przed tym samym problemem. Model działa pięknie w Jupyter Notebook. Ale to nie jest aplikacja, którą możesz pokazać klientowi czy wdrożyć w firmie.
Aplikacja webowa to strona internetowa, która pozwala użytkownikowi wpisać dane, wysłać je do Twojego modelu uczenia maszynowego i dostać wynik z powrotem. Wszystko dzieje się w przeglądarce - użytkownik nie musi instalować Pythona, bibliotek ani niczego innego.
Przykłady z życia:
Różnica między modelem a aplikacją? Model to silnik samochodu. Aplikacja to cały samochód z kierownicą, pedałami i deską rozdzielczą. Użytkownik nie musi znać się na silnikach - po prostu siada i jedzie.
Każda aplikacja ML składa się z trzech elementów. Nie musisz być ekspertem od każdego z nich - musisz wiedzieć, jak ze sobą współpracują.
To interfejs graficzny. Pola tekstowe, przyciski, wykresy. Użytkownik klika "Prześlij", Ty pokazujesz mu wynik. Nie musisz pisać tego w czystym HTML/CSS/JavaScript - są narzędzia, które robią to za Ciebie.
Gradio to biblioteka Pythonowa, która tworzy interfejs automatycznie. Piszesz 5 linijek kodu, dostajesz działającą stronę. Idealny start dla osób nietechnicznych.
Streamlit to krok dalej - bardziej elastyczny, pozwala na budowanie bardziej złożonych dashboardów. Wciąż nie wymaga znajomości JavaScript.
To serce Twojej aplikacji. Tutaj dzieje się magia: użytkownik wysyła dane, backend przetwarza je, przekazuje do modelu, odbiera predykcję i odsyła z powrotem do użytkownika.
W praktyce to skrypt Pythonowy, który:
Jeśli używasz Gradio czy Streamlit, backend piszesz w tym samym pliku co frontend. Wszystko w jednym miejscu.
To Twój wytrenowany model. Może być zapisany jako plik (np. model.pkl dla scikit-learn, model.h5 dla Keras, model.pt dla PyTorch). Aplikacja ładuje ten plik do pamięci i używa go do robienia predykcji.
Ważne: model musi być wyeksportowany w formacie, który można łatwo załadować. Nie wystarczy mieć kod treningowy - musisz zapisać wagi modelu do pliku.
Dobra, teoria za nami. Czas na konkret. Załóżmy, że masz wytrenowany model klasyfikacji tekstu (np. spam vs nie-spam). Pokażę Ci, jak zbudować dla niego aplikację webową.
Potrzebujesz:
python --version w terminalu)spam_classifier.pkl)Otwórz terminal i wpisz:
pip install gradio
Gradio to najprostsza biblioteka do budowania interfejsów ML. Stworzona przez zespół Hugging Face, używana przez tysiące projektów open-source.
Stwórz plik app.py i napisz funkcję, która ładuje Twój model i robi predykcję:
import pickle
import gradio as gr
# Załaduj model
with open('spam_classifier.pkl', 'rb') as f:
model = pickle.load(f)
def classify_text(text):
prediction = model.predict([text])[0]
return "Spam" if prediction == 1 else "Nie spam"
To wszystko. Funkcja classify_text przyjmuje tekst, przekazuje go do modelu, zwraca wynik.
Teraz dodaj interfejs Gradio (w tym samym pliku):
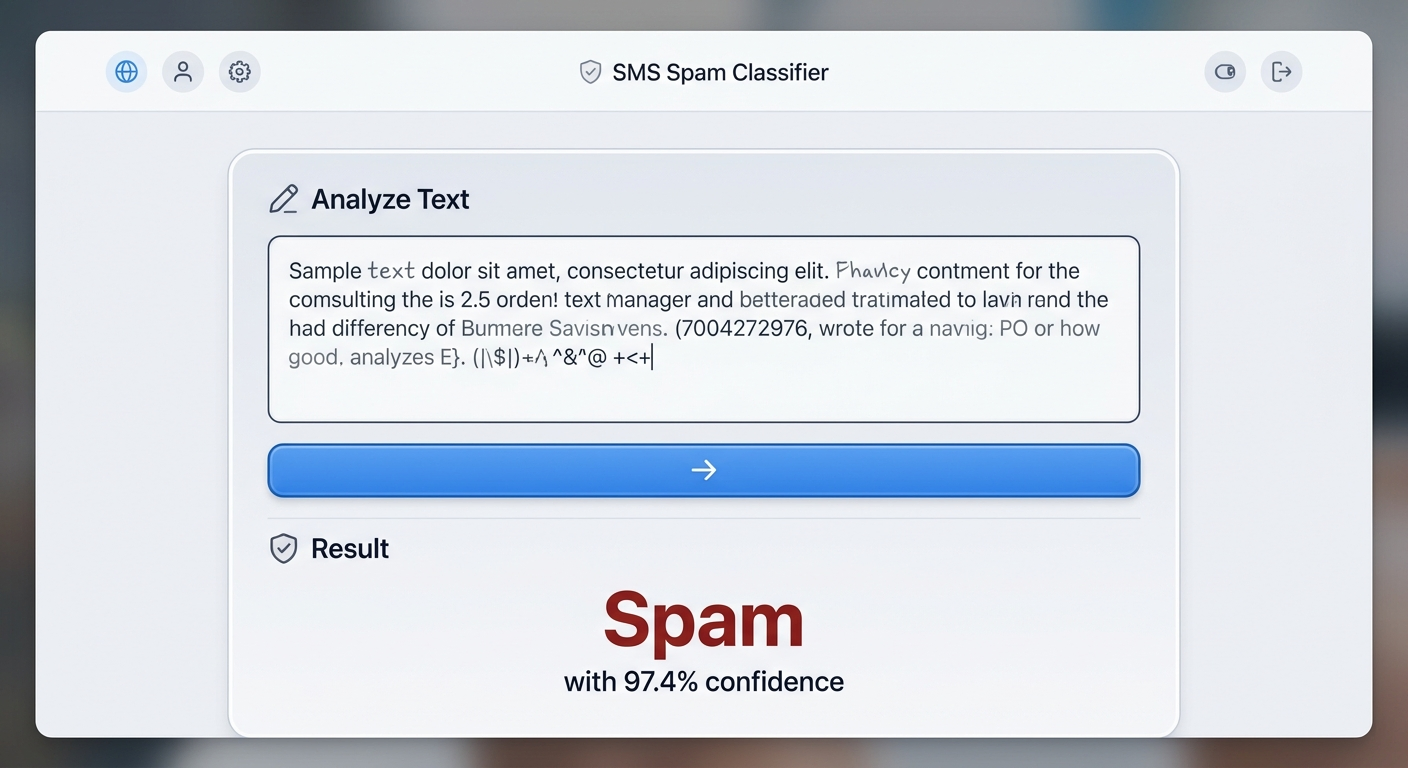
interface = gr.Interface(
fn=classify_text,
inputs=gr.Textbox(lines=5, placeholder="Wklej tekst wiadomości..."),
outputs="text",
title="Klasyfikator spamu",
description="Wpisz tekst, a model oceni, czy to spam."
)
interface.launch()
Zapisz plik. Uruchom w terminalu:
python app.py
Gradio automatycznie otworzy przeglądarkę z działającą aplikacją. Localhost, port 7860. Wpisujesz tekst, klikasz "Submit", dostajesz wynik.
Aplikacja działa na Twoim komputerze. Jak udostępnić ją innym? Gradio ma wbudowaną funkcję share:
interface.launch(share=True)
Uruchom ponownie. Gradio wygeneruje publiczny link (np. https://abc123.gradio.live), który możesz wysłać komukolwiek. Link działa 72 godziny.
To rozwiązanie tymczasowe. Do długoterminowego wdrożenia użyj Hugging Face Spaces (darmowe hostowanie dla projektów Gradio) lub Render (prosty deployment z GitHuba).
Nie. Gradio i Streamlit generują interfejs automatycznie. Piszesz tylko w Pythonie. JavaScript przydaje się, jeśli chcesz customizować wygląd na poziomie zaawansowanym. Na start nie jest potrzebny.
Dwa rozwiązania. Pierwszy: załaduj model raz przy starcie aplikacji (nie przy każdym requeście). Drugi: użyj API zewnętrznego - model działa na osobnym serwerze, aplikacja wysyła do niego zapytania. To podejście stosują firmy z dużymi modelami (np. integracja z API OpenAI).
Podstawy: dodaj rate limiting (limit requestów na użytkownika), autentykację (login/hasło lub klucz API), walidację danych wejściowych (sprawdzaj, czy użytkownik nie wysyła złośliwego kodu). Gradio ma wbudowane opcje autentykacji - wystarczy dodać parametr auth=("user", "password") do launch().
Tak. Hugging Face oferuje tysiące gotowych modeli (klasyfikacja tekstu, analiza sentymentu, rozpoznawanie obrazów). Możesz załadować je bezpośrednio w aplikacji Gradio - zero treningu, zero zapisywania plików. Przykład: pipeline("sentiment-analysis") z biblioteki transformers. Więcej o dostosowywaniu gotowych modeli znajdziesz tutaj.
Zależy od ruchu. Hugging Face Spaces: darmowe do 2 GB RAM (wystarczy na proste modele). Render: darmowy tier do 750 godzin miesięcznie. Google Cloud Run: płacisz za użycie (pierwsze 2 miliony requestów miesięcznie gratis). Dla małych projektów: 0-10 zł miesięcznie. Dla średnich: 50-200 zł.
Widziałem to nie raz. Ludzie budują aplikację, testują na swoim komputerze, wszystko działa. Wdrażają na serwer - i nagle model zwraca błędy albo działa znacznie wolniej.
Pułapka 1: Zależności środowiskowe. Model działa na Twoim laptopie, bo masz zainstalowane konkretne wersje bibliotek. Na serwerze są inne wersje - model się wywala. Rozwiązanie: stwórz plik requirements.txt z dokładnymi wersjami (pip freeze > requirements.txt) i użyj go przy deploymencie.
Pułapka 2: Brak walidacji danych. Użytkownik wpisuje coś niespodziewanego (pusty tekst, emoji, HTML) - aplikacja crashuje. Rozwiązanie: zawsze sprawdzaj dane wejściowe przed przekazaniem do modelu. Przykład: if not text or len(text) < 10: return "Tekst za krótki".
Pułapka 3: Model w pamięci przy każdym requeście. Jeśli ładujesz model za każdym razem, gdy użytkownik coś wysyła, aplikacja będzie wolna jak ślimak. Rozwiązanie: załaduj model raz przy starcie aplikacji (na poziomie globalnym, poza funkcją predykcji).
Pułapka 4: Brak logów. Coś nie działa, nie wiesz dlaczego. Rozwiązanie: dodaj podstawowe logowanie (print() wystarczy na start, potem logging). Zapisuj błędy, czas wykonania, nietypowe requesty.
Gradio to świetny start, ma jednak ograniczenia. Jeśli potrzebujesz bardziej złożonego interfejsu, masz opcje:
Streamlit - bardziej elastyczny niż Gradio, wciąż prosty. Pozwala na budowanie dashboardów z wykresami, tabelami, sliderami. Używany przez data scientistów do prezentacji analiz. Więcej o budowaniu interfejsów AI znajdziesz w tym przewodniku.
Flask/FastAPI - frameworki webowe Pythonowe. Dają pełną kontrolę nad backendem, wymagają jednak więcej kodu. Używasz ich, jeśli budujesz produkcyjną aplikację z autentykacją, bazą danych, integracjami zewnętrznymi.
React + API - jeśli masz frontend developera w zespole, możesz zbudować interfejs w React (lub Vue/Angular), a model wystawić jako API (FastAPI/Flask). To podejście dla firm, które chcą pełnej customizacji UI.
Masz działającą aplikację. Użytkownicy klikają, model odpowiada. To dopiero początek. Teraz musisz pomyśleć o:
Monitoringu - czy model działa poprawnie? Czy nie pogorszyła się jego dokładność? Narzędzia jak Weights & Biases czy MLflow pozwalają śledzić performance w czasie rzeczywistym.
Feedbacku użytkowników - dodaj przycisk "Ta predykcja jest błędna". Zbieraj dane, ucz model na nowo. Aplikacja ML to żywy organizm, nie statyczny produkt.
Skalowaniu - co jeśli zamiast 10 użytkowników dziennie będziesz mieć 1000? Musisz pomyśleć o load balancingu, cache'owaniu, optymalizacji modelu. To problemy na później - na start wystarczy działająca aplikacja.
Jeśli interesujesz się bardziej zaawansowanymi zastosowaniami, sprawdź jak wdrożyć chatbota AI na stronie firmowej - to kolejny krok w kierunku praktycznego wykorzystania modeli ML.
Otwórz terminal, zainstaluj Gradio, stwórz plik app.py z prostą funkcją (może nawet bez modelu ML - zwykłe "Hello World"). Uruchom. Zobacz, jak to działa. Masz 15 minut? To wystarczy, żeby przestać się bać i zacząć budować.
Ten poradnik to dopiero początek. W naszym kursie "Praktyczna AI" nauczysz się korzystać z ChatGPT, Claude i innych narzędzi AI w sposób systematyczny - od zera do zaawansowanego poziomu.
Sprawdź kurs →Podsumowanie: Aplikacja webowa z modelem ML to most między kodem a użytkownikiem końcowym. Nie musisz być programistą - narzędzia jak Gradio biorą na siebie większość pracy. Kluczowe elementy to frontend (interfejs), backend (logika) i sam model. Deployment zajmuje 15-30 minut. Największe pułapki to brak walidacji danych i ładowanie modelu przy każdym requeście.
Na podstawie: SukcesAI Course Material, dokumentacja Gradio, Streamlit
Podoba Ci się ten artykuł?
Co piątek wysyłam podsumowanie najlepszych artykułów tygodnia. Zapisz się!
90 minut praktycznej wiedzy o AI. Pokaze Ci krok po kroku, jak zaczac oszczedzac 10 godzin tygodniowo dzieki sztucznej inteligencji.
Zapisz sie na webinar
Chcesz uruchomić chatbota AI bez programowania? Zobacz, jak wybrać narzędzie, dodać wiedzę, ustawić odpowiedzi i wdrożyć bota na stronie.

Transkrypcja, edycja, intro, klonowanie głosu - narzędzia AI, które faktycznie oszczędzają czas. Sprawdzone rozwiązania dla podcastów.

Fine-tuning SpeechT5 to sposób, by model mowy rozumiał Twój głos, język czy akcent. Sprawdź, jak to zrobić bez kodowania i kiedy warto zainwestować czas.

Artifacts to funkcja Claude, która automatycznie tworzy interaktywne dokumenty, kod i wizualizacje w osobnym oknie. Sprawdź, jak z niej korzystać.

CV, list motywacyjny, przygotowanie do rozmowy, research firmy - ChatGPT potrafi Cię w tym wesprzeć. Konkretne kroki, gotowe prompty, zero teorii.

Claude Desktop zmienia ustawienia dostępu w przeglądarkach, które nawet nie są zainstalowane. Sprawdź, jak kontrolować uprawnienia aplikacji AI na swoim komputerze.
