Poradniki
·
10 min czytania
·
25 czerwca 2026
Jak zbudować model regresji w Scikit-learn - 4 praktyczne metody

Źródło: Link
Źródło: Link
118 lekcji bez kodowania. ChatGPT, Claude, Gemini, automatyzacje. Notatnik AI i AI Coach w cenie.
Słyszałeś, że AI potrafi przewidywać przyszłość? Nie potrafi. Potrafi za to analizować wzorce z przeszłości i na ich podstawie szacować, co się stanie dalej. To właśnie robi regresja ML - jeden z najczęściej używanych narzędzi w machine learning. Nie musisz być programistą, żeby zrozumieć jak to działa.
Regresja to metoda przewidywania wartości liczbowych. Nie kategorii ("to jest pies" albo "to jest kot"), ale konkretnych liczb. Ile będzie kosztować mieszkanie o powierzchni 50 m²? Jaka będzie temperatura jutro o 14:00? Ile sprzedaży wygeneruje kampania reklamowa z budżetem 10 000 zł?
W praktyce regresja analizuje dane historyczne, szuka zależności między zmiennymi (np. "powierzchnia mieszkania" a "cena") i buduje model matematyczny tej zależności. Potem używasz tego modelu do przewidywania wartości dla nowych danych.
Scikit-learn to biblioteka Pythona, która robi większość ciężkiej pracy za Ciebie. Zamiast pisać równania od zera, importujesz gotowy algorytm, wrzucasz dane i dostajesz działający model. Brzmi prosto? Bo jest - pod warunkiem, że rozumiesz podstawy.
Żeby budować modele regresji w Scikit-learn, potrzebujesz:
python --version)pip install scikit-learn pandas numpy matplotlibJeśli nie masz własnych danych, Scikit-learn ma wbudowane zestawy testowe (np. load_boston dla cen mieszkań). Możesz też pobrać dane z Kaggle - tam znajdziesz tysiące gotowych zbiorów.
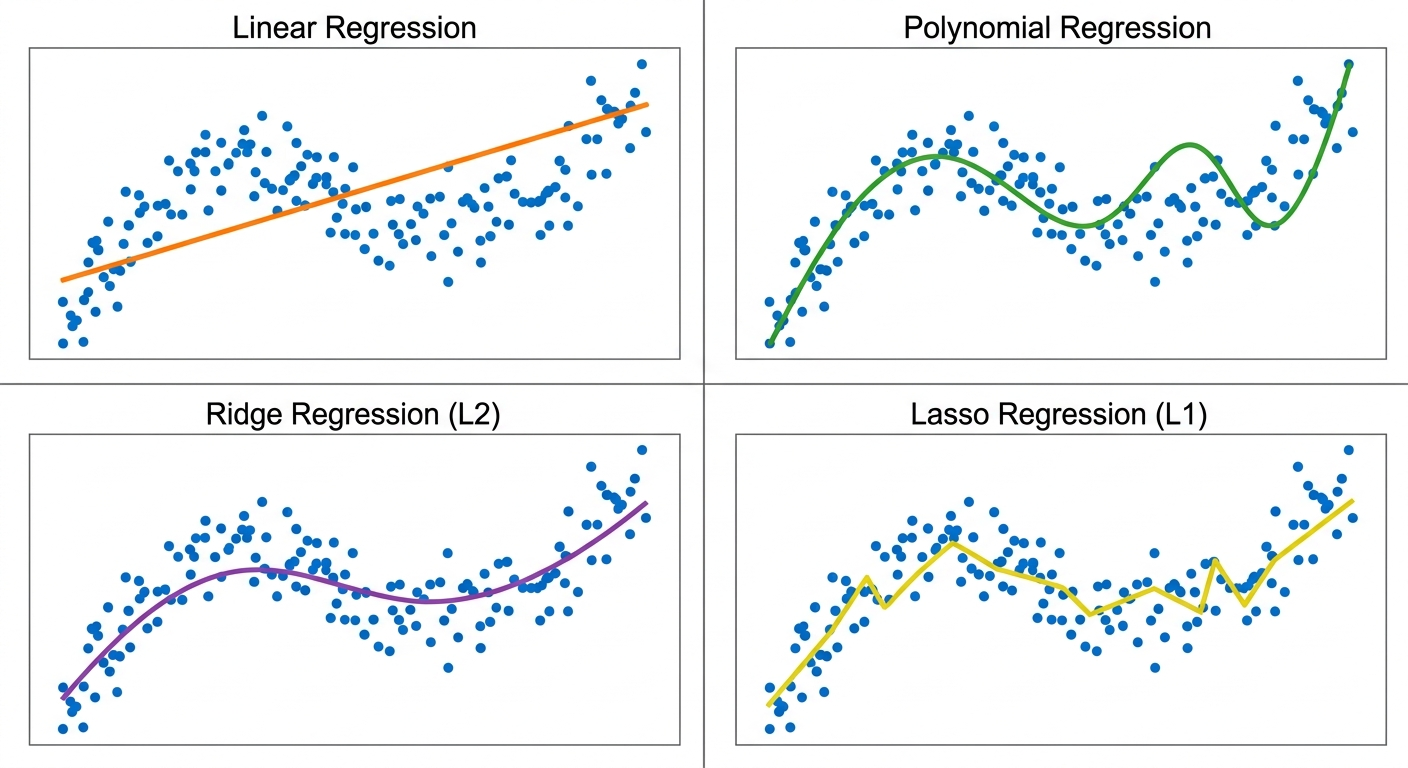
Regresja liniowa zakłada, że zależność między zmiennymi jest... liniowa. Jeśli powierzchnia mieszkania rośnie, cena rośnie proporcjonalnie. Prosta linia na wykresie.
Sprawdza się, gdy zależność między danymi jest prosta i przewidywalna. Przykłady: przewidywanie zużycia energii na podstawie temperatury, szacowanie czasu dostawy na podstawie odległości, prognozowanie sprzedaży na podstawie wydatków na reklamę.
NIE sprawdza się, gdy zależność jest nieliniowa (np. wzrost bakterii - najpierw powolny, potem eksploduje, potem znów zwalnia).
import pandas as pd; data = pd.read_csv('dane.csv')X = data[['powierzchnia', 'liczba_pokoi']]; y = data['cena']from sklearn.model_selection import train_test_split; X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2)from sklearn.linear_model import LinearRegression; model = LinearRegression(); model.fit(X_train, y_train)predictions = model.predict(X_test); print(predictions)from sklearn.metrics import mean_squared_error; mse = mean_squared_error(y_test, predictions); print(f'Błąd: {mse}')Mean Squared Error (MSE) to średni kwadrat błędu przewidywań. Im niższy, tym lepiej. Jeśli MSE wynosi 10 000, a przewidujesz ceny mieszkań w tysiącach złotych - model jest OK. Jeśli przewidujesz temperatury w stopniach Celsjusza - coś poszło nie tak.
Czasem zależność nie jest prostą linią. Przykład: zależność między wiekiem samochodu a jego wartością. Pierwszy rok - duży spadek ceny. Potem wolniejszy. Po 10 latach - prawie płasko. To krzywa, nie linia.
Regresja wielomianowa dopasowuje krzywą (wielomian stopnia 2, 3 lub wyższego) zamiast prostej linii.
from sklearn.preprocessing import PolynomialFeatures; poly = PolynomialFeatures(degree=2); X_poly = poly.fit_transform(X_train)model = LinearRegression(); model.fit(X_poly, y_train)X_test_poly = poly.transform(X_test); predictions = model.predict(X_test_poly)Parametr degree to stopień wielomianu. degree=2 to parabola (krzywa w kształcie U). degree=3 to bardziej skomplikowana krzywa. Nie przesadzaj - degree=10 dopasuje się idealnie do danych treningowych, ale będzie beznadziejny na nowych danych (overfitting).
Jeśli model ma za dużo stopni swobody (np. wielomian stopnia 10), zacznie "zapamiętywać" dane treningowe zamiast uczyć się wzorców. Na danych testowych wyniki będą fatalne. Sprawdzaj MSE na danych testowych - jeśli rośnie, zmniejsz degree.
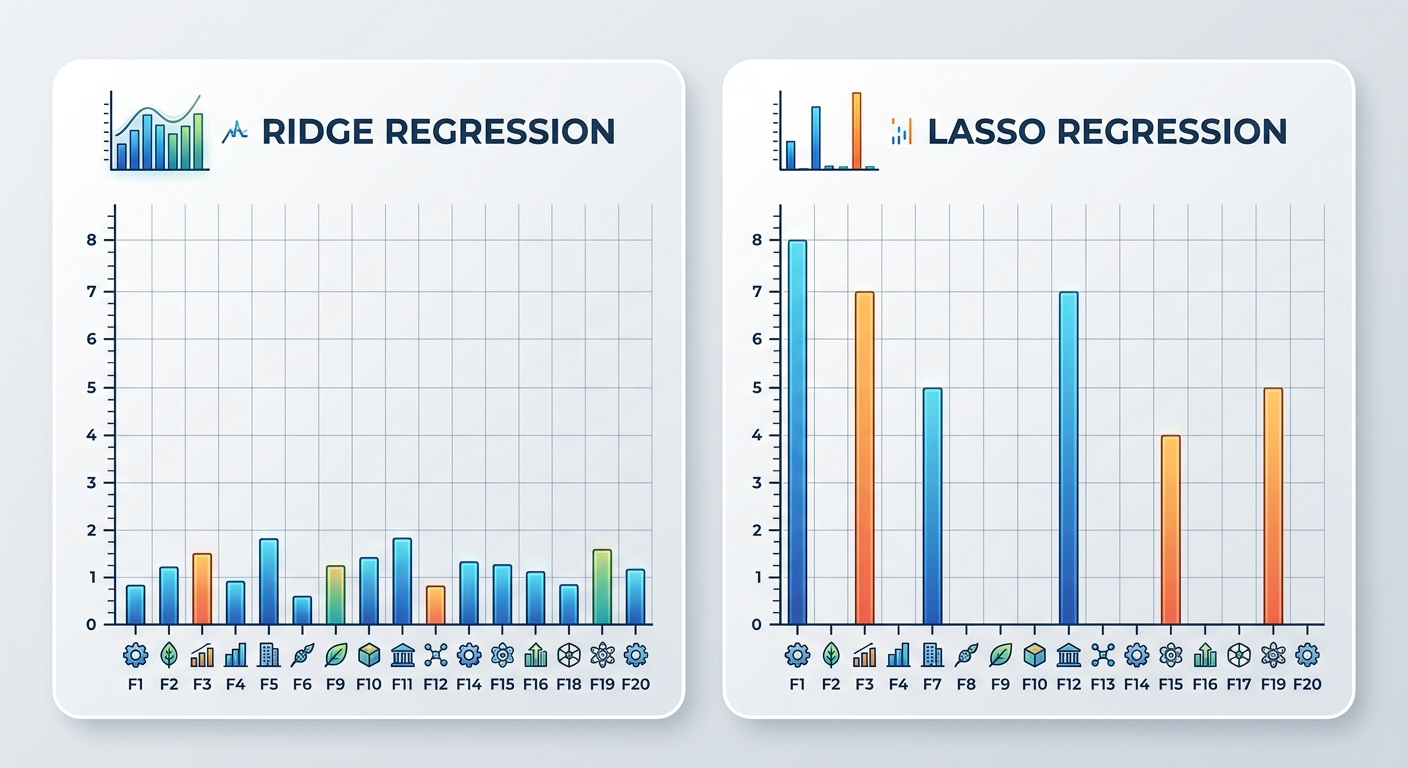
Ridge to regresja liniowa z "hamulcem". Dodaje karę za zbyt duże współczynniki w modelu. Po co? Żeby zapobiec overfittingowi, gdy masz dużo zmiennych wejściowych.
Przykład: przewidujesz cenę mieszkania na podstawie 50 cech (powierzchnia, liczba pokoi, piętro, odległość od metra, rok budowy, stan, balkon, winda...). Część z nich to szum. Ridge "tłumi" mniej ważne zmienne, żeby nie zakłócały modelu.
from sklearn.linear_model import Ridgemodel = Ridge(alpha=1.0); model.fit(X_train, y_train)Parametr alpha to siła "hamulca". alpha=0 to zwykła regresja liniowa. alpha=1.0 to umiarkowana kara. alpha=10.0 to mocna kara (model będzie prostszy, ale może stracić dokładność). Testuj różne wartości i sprawdzaj MSE.
Jeśli chcesz systematycznie nauczyć się pracy z modelami regresji i innymi narzędziami AI, sprawdź nasz przewodnik po nauce machine learning od podstaw - tam znajdziesz ścieżkę rozwoju od zera do zaawansowanego poziomu.
Lasso to Ridge na sterydach. Nie tylko tłumi mniej ważne zmienne - zeruje je całkowicie. Jeśli zmienna nie wnosi wartości, Lasso ją wyrzuca.
Po co? Żeby uprościć model i zwiększyć jego interpretowalność. Zamiast 50 zmiennych dostajesz 10 naprawdę ważnych. Łatwiej zrozumieć, co wpływa na wynik.
from sklearn.linear_model import Lassomodel = Lasso(alpha=0.1); model.fit(X_train, y_train)print(model.coef_) (współczynniki równe 0 = zmienne wyrzucone)Parametr alpha działa podobnie jak w Ridge, ale efekt jest silniejszy. Zacznij od małych wartości (np. 0.01) i zwiększaj, aż model zacznie wyrzucać zmienne.
Nie ma jednej uniwersalnej odpowiedzi. Zależy od danych, problemu i tego, co chcesz osiągnąć. Kilka wskazówek:
Najlepszy sposób: przetestuj wszystkie cztery metody na swoich danych i porównaj MSE. Wygrywa ta z najniższym błędem na danych testowych (nie treningowych!).
Nie wystarczy sprawdzić MSE raz. Dane testowe mogły być "łatwe" albo "trudne" przez przypadek. Użyj walidacji krzyżowej (cross-validation):
W Scikit-learn to jedna linia kodu: from sklearn.model_selection import cross_val_score; scores = cross_val_score(model, X, y, cv=5, scoring='neg_mean_squared_error'); print(scores.mean())
Jeśli średni wynik jest stabilny (niewielkie różnice między iteracjami), model jest solidny. Jeśli skacze chaotycznie - masz problem (za mało danych, overfitting, albo zły wybór zmiennych).
Chcesz głębiej zrozumieć, jak AI przetwarza dane i uczy się wzorców? Zobacz nasz przewodnik po transformerach AI - to fundament nowoczesnych modeli językowych i nie tylko.
Jeśli jedna zmienna ma wartości 0-1, a druga 0-10000, model będzie faworyzować tę drugą (bo ma większy wpływ numeryczny). Rozwiązanie: znormalizuj dane przed treningiem.
from sklearn.preprocessing import StandardScaler; scaler = StandardScaler(); X_train_scaled = scaler.fit_transform(X_train); X_test_scaled = scaler.transform(X_test)
Jeśli sprawdzasz MSE na tych samych danych, na których trenowałeś model, wynik będzie sztucznie zawyżony. Model "widział" te dane, więc oczywiście radzi sobie dobrze. Zawsze dziel dane na treningowe i testowe PRZED treningiem.
Jeśli w zbiorze są puste wartości (NaN), Scikit-learn zwróci błąd. Musisz je uzupełnić (np. średnią z kolumny) albo usunąć wiersze z brakami.
data = data.fillna(data.mean()) - uzupełnia braki średnią
data = data.dropna() - usuwa wiersze z brakami
Teoretycznie tak - są narzędzia no-code jak Orange, KNIME czy AutoML w Google Cloud. Żeby naprawdę rozumieć, co robisz i mieć kontrolę nad modelem, podstawy Pythona są niezbędne. Nie musisz być ekspertem - wystarczy umieć uruchomić skrypt i zrozumieć podstawową składnię. Jeśli dopiero zaczynasz, zacznij od podstaw machine learning - tam znajdziesz ścieżkę rozwoju dostosowaną do początkujących.
Regresja liniowa albo Ridge. Lasso i wielomianowa potrzebują więcej danych, żeby nie przeuczyć się (overfitting). Jeśli masz mniej niż 100 próbek, trzymaj się prostych metod i niskich wartości parametrów regularyzacji.
W regresji liniowej współczynnik przy zmiennej mówi, o ile zmieni się wynik, gdy zmienna wzrośnie o 1. Przykład: współczynnik 5000 przy zmiennej "powierzchnia" oznacza, że każdy dodatkowy m² zwiększa cenę mieszkania o 5000 zł. Sprawdzasz to przez model.coef_ po wytrenowaniu modelu.
Nie bezpośrednio. Musisz przekształcić kategorie (np. "dzielnica: Śródmieście, Mokotów, Praga") na liczby. Najczęściej używa się one-hot encoding: każda kategoria staje się osobną kolumną z wartościami 0/1. W Scikit-learn: from sklearn.preprocessing import OneHotEncoder; encoder = OneHotEncoder(); X_encoded = encoder.fit_transform(X).
Zależy od tego, jak szybko zmieniają się dane. Jeśli przewidujesz ceny mieszkań - raz na kwartał wystarczy. Jeśli przewidujesz ceny akcji - codziennie albo częściej. Zasada: jeśli MSE na nowych danych zaczyna rosnąć, czas na ponowny trening z nowszymi danymi.
Ten poradnik to dopiero początek. W naszym kursie "Praktyczna AI" nauczysz się korzystać z ChatGPT, Claude i innych narzędzi AI w sposób systematyczny - od zera do zaawansowanego poziomu.
Sprawdź kurs →Regresja ML to narzędzie, które przewiduje wartości liczbowe na podstawie danych historycznych. Scikit-learn daje Ci cztery sprawdzone metody: liniową (prosta, szybka), wielomianową (dla krzywych zależności), Ridge (tłumi szum) i Lasso (automatycznie wybiera zmienne). Każda ma swoje miejsce - testuj, porównuj MSE i wybieraj tę, która działa najlepiej na Twoich danych.
Nie komplikuj na siłę. Zacznij od regresji liniowej. Jeśli nie wystarcza, przejdź do wielomianowej. Jeśli masz dużo zmiennych, spróbuj Ridge albo Lasso. Zawsze dziel dane na treningowe i testowe. Zawsze waliduj krzyżowo. Zawsze normalizuj dane przed treningiem.
Jeden krok na start: Pobierz dowolny zbiór danych z Kaggle (np. "House Prices"), załaduj go do pandas i zbuduj prosty model regresji liniowej według kroków z tego artykułu. Nie czytaj więcej tutoriali - otwórz edytor i napisz te 10 linii kodu. To jedyny sposób, żeby naprawdę zrozumieć, jak to działa.
Na podstawie: materiałów kursu AI Evolution (sukcesai.com)
Podoba Ci się ten artykuł?
Co piątek wysyłam podsumowanie najlepszych artykułów tygodnia. Zapisz się!
90 minut praktycznej wiedzy o AI. Pokaze Ci krok po kroku, jak zaczac oszczedzac 10 godzin tygodniowo dzieki sztucznej inteligencji.
Zapisz sie na webinar
Chcesz zrozumieć, jak naprawdę działają duże modele językowe? Zbuduj swój własny - krok po kroku, bez magii. Przewodnik dla osób bez doświadczenia w programowaniu.

Chcesz nauczyć się uczenia maszynowego, ale nie wiesz od czego zacząć? Sprawdź darmowy kurs Microsoftu z 26 lekcjami i praktycznymi projektami.

Regresja logistyczna brzmi skomplikowanie, ale to podstawa AI, która działa w Twoim telefonie. Sprawdź, jak działa i gdzie ją wykorzystasz - bez matematyki.

Twój model AI działa świetnie... przez miesiąc. Potem zaczyna się sypać. Poznaj konkretne kroki, jak zbudować system, który uczy się na bieżąco - zanim użytkownicy zaczną narzekać.

Regresja liniowa dobrze sprawdza się na prostych danych. Ale co zrobić, gdy zależności nie układają się w linię prostą? Poznaj dwa rozszerzenia: regresję lokalnie ważoną i logistyczną.

Fine-tuning SpeechT5 to sposób, by model mowy rozumiał Twój głos, język czy akcent. Sprawdź, jak to zrobić bez kodowania i kiedy warto zainwestować czas.
