Poradniki
·
12 min czytania
·
23 maja 2026
Jak zrozumieć regresję lokalnie ważoną i logistyczną - przewodnik

Źródło: Link
Źródło: Link
118 lekcji bez kodowania. ChatGPT, Claude, Gemini, automatyzacje. Notatnik AI i AI Coach w cenie.
Regresja liniowa to fundament uczenia maszynowego. Dopasowujesz prostą do danych, minimalizujesz błąd, gotowe. Tylko że większość prawdziwych problemów nie układa się w linię prostą. Ceny domów nie rosną proporcjonalnie do metrażu. Prawdopodobieństwo, że klient kliknie w reklamę, nie zmienia się liniowo z czasem spędzonym na stronie.
Wtedy potrzebujesz czegoś więcej. Andrew Ng w trzecim wykładzie kursu CS229 na Stanfordzie omawia dwa rozszerzenia: regresję lokalnie ważoną (która pozwala dopasować krzywą zamiast linii) i regresję logistyczną (która pozwala przewidywać kategorie, nie liczby).
Ten przewodnik przeprowadzi Cię przez obie metody krok po kroku - bez zaawansowanej matematyki, za to z konkretnymi przykładami.
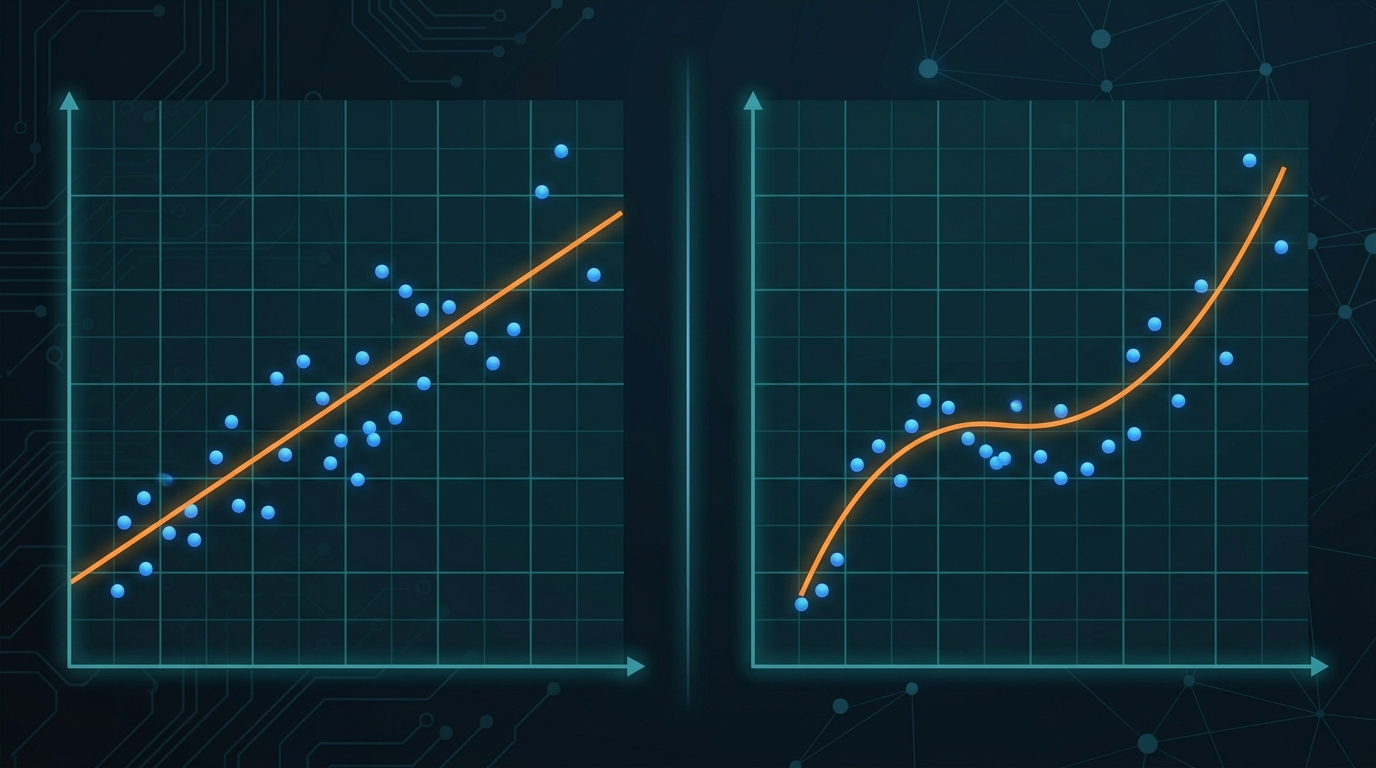
Ten przewodnik zakłada, że rozumiesz podstawy regresji liniowej. Jeśli nie - najpierw przejdź przez materiał o gradiencie prostym i równaniach normalnych. Potrzebujesz wiedzieć:
Jeśli te pojęcia brzmią obco, wróć do podstaw uczenia maszynowego i dopiero potem wracaj tutaj.
Masz dane o cenach domów. Na osi X: metraż. Na osi Y: cena. Klasyczna regresja liniowa dopasuje prostą. I może to zadziała - jeśli zależność faktycznie jest liniowa.
Często dane wyglądają inaczej. Małe domy (50-100m²) drożeją wolno. Średnie (100-150m²) szybciej. Duże (powyżej 150m²) znowu wolniej, bo rynek się zwęża. Prosta linia nie odda tej krzywizny. Będziesz miał duży błąd.
Możesz dodać więcej cech - metraż do kwadratu, do sześcianu. Ale to wymaga ręcznego wyboru, co dodać. I łatwo o overfitting (model dopasuje się idealnie do danych treningowych, ale nie zadziała na nowych).
Regresja lokalnie ważona rozwiązuje ten problem inaczej: zamiast dopasowywać jedną globalną prostą, dopasowuje lokalną prostą dla każdego punktu, który chcesz przewidzieć.
Podstawowa idea: gdy przewidujesz cenę domu o metrażu 120m², nie patrzysz na wszystkie domy równo. Dajesz większą wagę domom o podobnym metrażu (110-130m²), a mniejszą tym odległym (50m² czy 200m²).
Załóżmy, że ktoś pyta: ile kosztuje dom 120m²? To Twój punkt zapytania x.
Dla każdego domu w Twoich danych treningowych obliczasz wagę w⁽ⁱ⁾. Im bliżej metraż tego domu do 120m², tym większa waga. Im dalej - tym mniejsza.
Standardowa formuła wagi to funkcja Gaussa (dzwon):
w⁽ⁱ⁾ = exp(-(x⁽ⁱ⁾ - x)² / (2τ²))
Gdzie τ (tau) to parametr szerokości. Mały τ = tylko najbliżsi sąsiedzi mają wagę. Duży τ = nawet odległe punkty wpływają na predykcję.
Teraz rozwiązujesz standardową regresję liniową, ale zamiast minimalizować sumę kwadratów błędów, minimalizujesz ważoną sumę:
J(θ) = Σ w⁽ⁱ⁾ (h(x⁽ⁱ⁾) - y⁽ⁱ⁾)²
Przykłady bliskie 120m² (duża waga) wpływają mocno na dopasowanie. Odległe (mała waga) prawie wcale.
Obliczasz h(x) dla x = 120m². To Twoja predykcja.
Kluczowa różnica: w regresji liniowej dopasowujesz parametry raz. W lokalnie ważonej - za każdym razem, gdy przewidujesz nowy punkt. To kosztowne obliczeniowo, ale daje elastyczność.
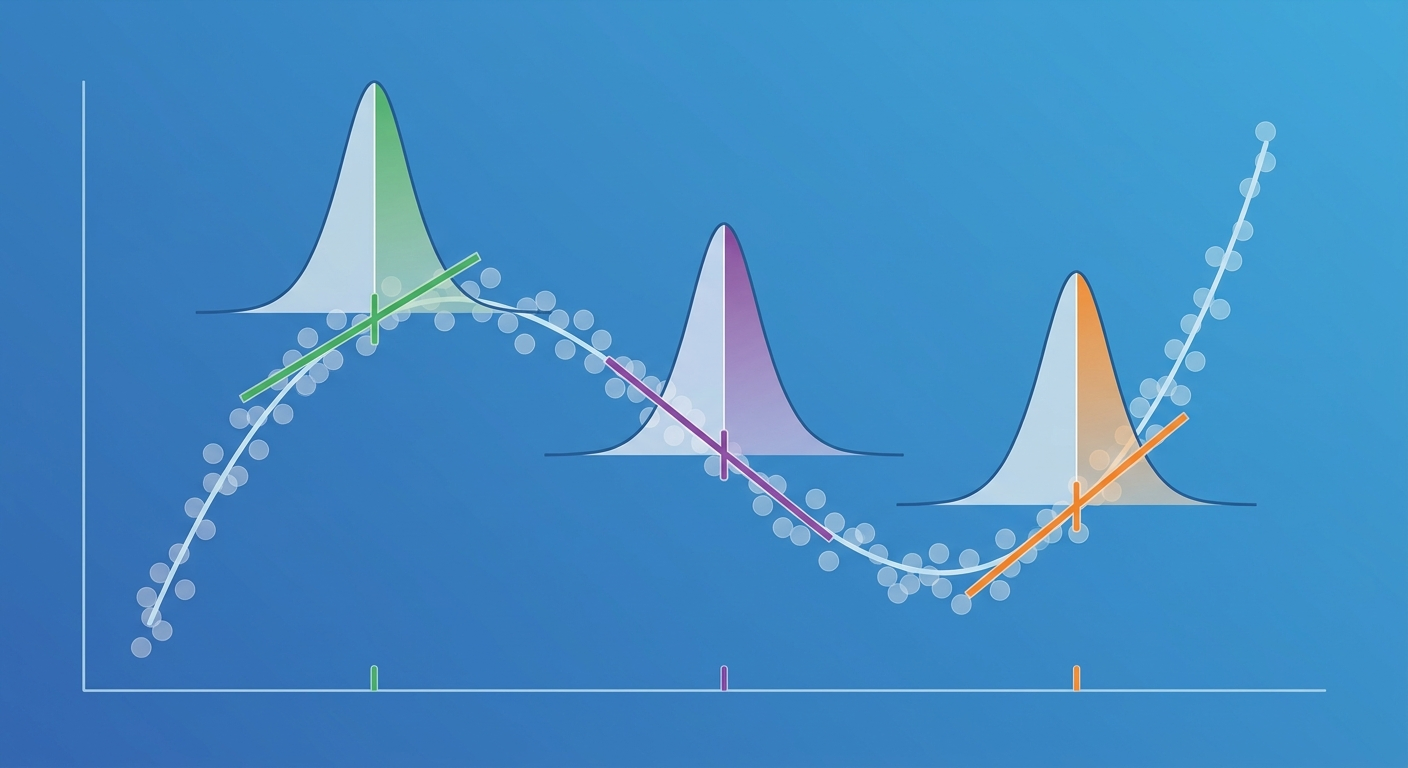
Tau kontroluje, jak "lokalny" jest Twój model:
Jak wybrać? Walidacja krzyżowa. Testujesz różne wartości τ na zbiorze walidacyjnym i wybierasz tę, która daje najmniejszy błąd.
Regresja lokalnie ważona sprawdza się, gdy:
Przykłady z życia: prognozowanie ruchu drogowego (natężenie zmienia się nieliniowo w ciągu dnia), modelowanie cen nieruchomości (lokalna specyfika dzielnic), analiza trendów giełdowych (krótkoterminowe fluktuacje).
Regresja liniowa przewiduje liczby (cena domu: 500 000 zł). Ale co, jeśli chcesz przewidzieć kategorię? Czy klient kliknie w reklamę (tak/nie)? Czy email to spam (tak/nie)?
Możesz spróbować użyć regresji liniowej: 0 = nie, 1 = tak. To nie zadziała dobrze. Regresja liniowa może przewidzieć 1.5 albo -0.3. Co to znaczy? "Trochę tak"? "Mniej niż nie"?
Regresja logistyczna rozwiązuje ten problem, zmieniając wyjście z liczby na prawdopodobieństwo (wartość między 0 a 1).
Obliczasz z = θ₀ + θ₁x₁ + θ₂x₂ + ... (dokładnie jak w regresji liniowej). To Twój "surowy" wynik.
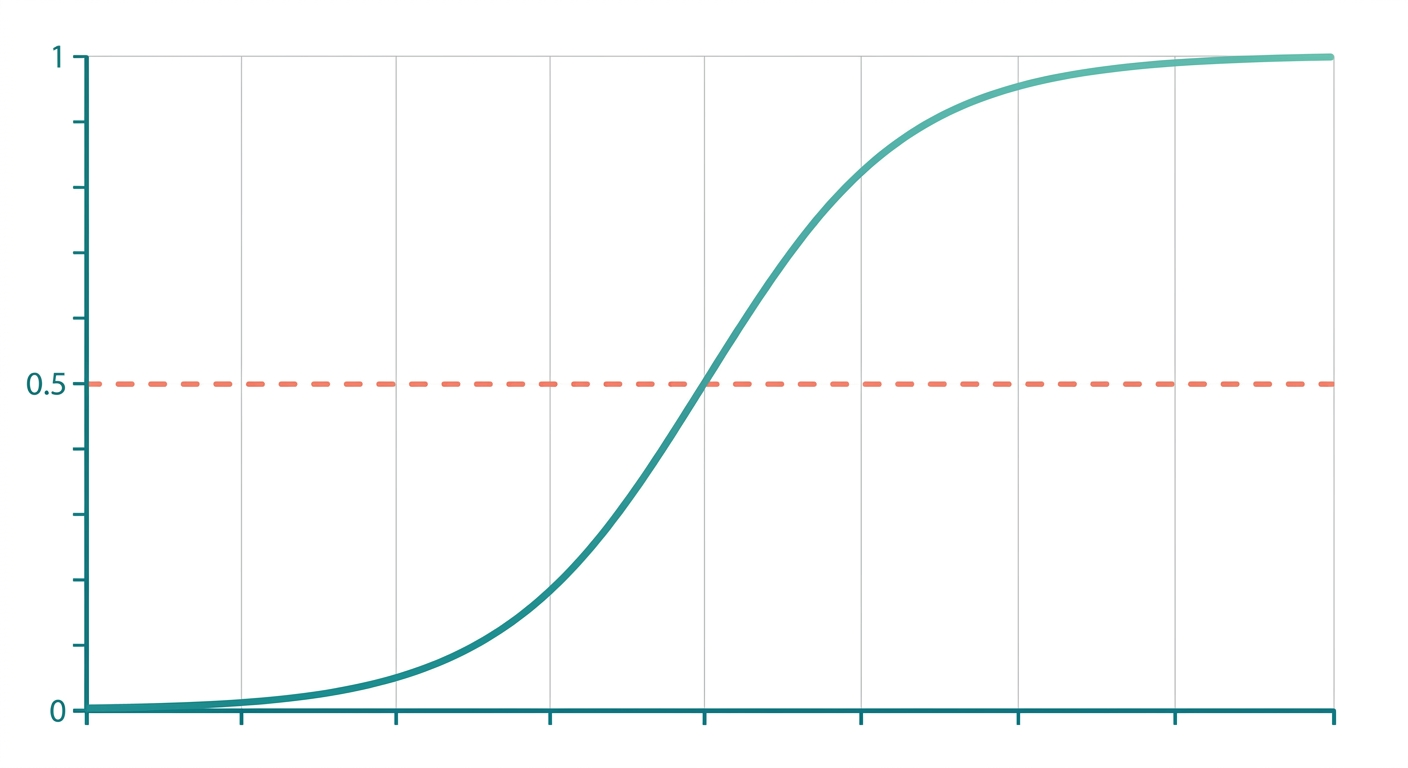
Zamiast zwrócić z, przepuszczasz go przez funkcję sigmoidalną (logistyczną):
h(x) = 1 / (1 + e⁻ᶻ)
Ta funkcja "ściska" dowolną liczbę z do przedziału (0, 1):
Teraz h(x) możesz interpretować jako prawdopodobieństwo: "Model przewiduje 0.8 = 80% szans, że klient kliknie".
Standardowo: jeśli h(x) ≥ 0.5, przewidujesz klasę 1 (tak). Jeśli h(x) < 0.5, przewidujesz klasę 0 (nie). Możesz przesunąć próg w zależności od problemu (np. w diagnostyce medycznej wolisz fałszywe alarmy niż przeoczone przypadki).
W regresji liniowej minimalizowałeś sumę kwadratów błędów. W logistycznej używasz innej funkcji kosztu - cross-entropy (entropia krzyżowa):
J(θ) = -1/m Σ [y⁽ⁱ⁾ log(h(x⁽ⁱ⁾)) + (1 - y⁽ⁱ⁾) log(1 - h(x⁽ⁱ⁾))]
Dlaczego nie suma kwadratów? Bo z sigmoidem tworzy nieliniową, wielomodalną funkcję (wiele lokalnych minimów). Gradient descent może ugrzęznąć. Cross-entropy daje wypukłą funkcję kosztu - jedno globalne minimum, łatwiej optymalizować.
Aktualizacja parametrów wygląda identycznie jak w regresji liniowej:
θⱼ := θⱼ - α (1/m) Σ (h(x⁽ⁱ⁾) - y⁽ⁱ⁾) xⱼ⁽ⁱ⁾
Różnica: h(x) to teraz sigmoid, nie liniowa funkcja. Ale wzór aktualizacji - identyczny. To elegancka matematyka.
Gradient descent działa, ale bywa wolny. Musisz dobierać learning rate α, robić wiele iteracji. Metoda Newtona (Newton-Raphson) to alternatywa, która często zbiega szybciej.
Zamiast iść w kierunku gradientu małymi krokami, metoda Newtona używa informacji o krzywiźnie funkcji (druga pochodna, macierz Hessego) i robi większe, mądrzejsze kroki.
Aktualizacja w metodzie Newtona:
θ := θ - H⁻¹ ∇J(θ)
Gdzie H to macierz Hessego (drugie pochodne), ∇J(θ) to gradient.
Zalety: zbieżność w mniejszej liczbie iteracji (czasem 10-20 zamiast tysięcy). Wady: musisz obliczać i odwracać macierz Hessego - kosztowne dla dużych danych (setki tysięcy cech).
Dla małych i średnich problemów (tysiące przykładów, dziesiątki cech) metoda Newtona wygrywa. Dla dużych (miliony przykładów) gradient descent (lub jego warianty jak Adam) są bardziej skalowalne.
Regresja logistyczna to koń roboczy klasyfikacji binarnej. Używasz jej, gdy:
Regresja logistyczna to nie najnowocześniejszy model (dziś mamy sieci neuronowe, gradient boosting), ale wciąż używana - bo szybka, interpretowalna (widzisz, które cechy wpływają jak mocno na decyzję) i stabilna.
Jeśli dopiero zaczynasz z uczeniem maszynowym, zacznij od regresji logistycznej. Zrozumiesz fundamenty, zanim przejdziesz do bardziej złożonych modeli.
Andrew Ng w wykładzie omawia też probabilistyczną interpretację regresji liniowej i logistycznej. Dlaczego minimalizowanie sumy kwadratów błędów w regresji liniowej ma sens? Bo to równoważne maksymalizacji prawdopodobieństwa danych przy założeniu, że błędy mają rozkład Gaussa.
Dlaczego cross-entropy w regresji logistycznej? Bo to równoważne maksymalizacji prawdopodobieństwa przy założeniu rozkładu Bernoulliego (moneta - orzeł/reszka).
Ta perspektywa łączy uczenie maszynowe ze statystyką. Nie musisz tego rozumieć, żeby używać modeli. Ale jeśli chcesz głębiej - to fundament bayesowskiego podejścia do ML.
Kilka rzeczy, które łatwo spartaczyć:
Jeśli dotarłeś tutaj, rozumiesz podstawy regresji lokalnie ważonej i logistycznej. To solidny fundament. Następne kroki:
Uczenie maszynowe to umiejętność praktyczna. Czytanie o tym daje podstawy. Implementacja - zrozumienie. Eksperymentowanie - intuicję.
Ten poradnik to dopiero początek. W naszym kursie "Praktyczna AI" nauczysz się korzystać z ChatGPT, Claude i innych narzędzi AI w sposób systematyczny - od zera do zaawansowanego poziomu.
Sprawdź kurs →Regresja lokalnie ważona rozszerza regresję liniową, pozwalając dopasować nieliniowe zależności bez ręcznego dobierania cech. Dopasowujesz lokalny model dla każdego punktu zapytania, dając większą wagę bliskim sąsiadom. Elastyczna, ale kosztowna obliczeniowo.
Regresja logistyczna zmienia problem regresji (przewidywanie liczb) w klasyfikację (przewidywanie kategorii). Używa funkcji sigmoidalnej, żeby zamienić surowy wynik w prawdopodobieństwo. Trenowana przez gradient descent lub metodę Newtona z funkcją kosztu cross-entropy.
Oba podejścia to fundamenty uczenia maszynowego. Nie najnowocześniejsze, ale wciąż używane - i kluczowe, żeby zrozumieć bardziej zaawansowane modele.
Jeden krok na start: Otwórz Jupyter Notebook. Załaduj dataset Iris (klasyfikacja kwiatów na podstawie wymiarów płatków). Zaimplementuj regresję logistyczną od zera - gradient, sigmoid, cross-entropy. Nie używaj gotowych bibliotek. Zobaczysz, jak to działa naprawdę. I zrozumiesz, dlaczego sklearn robi to w jednej linii.
Regresja liniowa dopasowuje jedną globalną prostą do wszystkich danych. Regresja lokalnie ważona dopasowuje lokalną prostą dla każdego punktu zapytania, dając większą wagę przykładom treningowym bliskim temu punktowi. Dzięki temu może modelować nieliniowe zależności bez dodawania nowych cech.
Regresja liniowa przewiduje wartości ciągłe (cena domu, temperatura). Regresja logistyczna przewiduje kategorie binarne (spam/nie-spam, klik/brak kliku). Jeśli Twoje wyjście to 0/1, tak/nie, prawda/fałsz - używasz logistycznej. Jeśli liczba rzeczywista - liniowej.
Tau kontroluje szerokość "okna" wag. Małe tau oznacza, że tylko najbliżsi sąsiedzi wpływają na predykcję (model bardzo elastyczny, ryzyko overfittingu). Duże tau oznacza, że wszystkie punkty mają podobną wagę (model zachowuje się jak zwykła regresja liniowa). Dobierasz tau przez walidację krzyżową.
Sigmoid zamienia dowolną liczbę rzeczywistą w wartość między 0 a 1, którą możesz interpretować jako prawdopodobieństwo. Bez sigmoida regresja liniowa mogłaby przewidzieć wartości poza zakresem [0,1], co nie ma sensu dla prawdopodobieństwa. Sigmoid też daje gładką, różniczkowalną funkcję, łatwą do optymalizacji.
Nie. Metoda Newtona zbiega szybciej (mniej iteracji), ale każda iteracja jest droższa - musisz obliczać i odwracać macierz Hessego. Dla małych problemów (tysiące przykładów, dziesiątki cech) wygrywa. Dla dużych (miliony przykładów, setki tysięcy cech) gradient descent i jego warianty (Adam, RMSprop) są bardziej skalowalne.
Na podstawie: Stanford CS229: Machine Learning - Lecture 3 (Andrew Ng)
Podoba Ci się ten artykuł?
Co piątek wysyłam podsumowanie najlepszych artykułów tygodnia. Zapisz się!
10 gotowych promptów do codziennej pracy + 5 narzędzi + plan na pierwszy tydzień. PDF, 4 strony konkretu.
90 minut praktycznej wiedzy o AI. Pokaze Ci krok po kroku, jak zaczac oszczedzac 10 godzin tygodniowo dzieki sztucznej inteligencji.
Zapisz sie na webinarReprezentujesz firme? Zobacz wdrozenia AI dla firm →

Twój model AI działa świetnie... przez miesiąc. Potem zaczyna się sypać. Poznaj konkretne kroki, jak zbudować system, który uczy się na bieżąco - zanim użytkownicy zaczną narzekać.

Chcesz nauczyć się uczenia maszynowego, ale nie wiesz od czego zacząć? Sprawdź darmowy kurs Microsoftu z 26 lekcjami i praktycznymi projektami.

Regresja logistyczna brzmi skomplikowanie, ale to podstawa AI, która działa w Twoim telefonie. Sprawdź, jak działa i gdzie ją wykorzystasz - bez matematyki.

Fine-tuning SpeechT5 to sposób, by model mowy rozumiał Twój głos, język czy akcent. Sprawdź, jak to zrobić bez kodowania i kiedy warto zainwestować czas.

Statystyka i prawdopodobieństwo to fundament AI. Wyjaśniamy kluczowe pojęcia prostym językiem - bez matematycznego żargonu, z praktycznymi przykładami.

Uczenie przez wzmacnianie sprawia, że ChatGPT rozumie kontekst, a nie tylko składa słowa. Wyjaśniamy krok po kroku, jak to działa i dlaczego ma znaczenie.
