Poradniki
·
9 min czytania
·
31 maja 2026
Jak zrozumieć teorię uczenia maszynowego - przewodnik Stanford CS229

Źródło: Link
"Niektóre koncepcje pogłębiają zrozumienie, jak uczenie maszynowe działa pod spodem. Jakie założenia przyjmujemy i dlaczego rzeczy generalizują" - tak zaczyna się sesja dyskusyjna Stanford CS229, kursu Andrew Ng, który ukształtował całe pokolenie inżynierów AI. Brzmi akademicko? To właśnie te "założenia pod spodem" wyjaśniają, dlaczego ChatGPT czasem gada głupoty, a czasem To przypomina ekspert.
Teoria uczenia maszynowego to instrukcja obsługi do każdego modelu AI, który kiedykolwiek użyjesz. Jeśli chcesz rozumieć, kiedy AI zawodzi (a kiedy nie), musisz poznać kilka podstawowych mechanizmów.
Zanim jakikolwiek algorytm AI zacznie się uczyć, przyjmuje dwa fundamentalne założenia. Pierwsze: istnieje dystrybucja danych, z której pochodzą wszystkie przykłady - zarówno te treningowe, jak i te, które zobaczysz w przyszłości. Drugie: wszystkie próbki są niezależne.
Czemu to ważne? Jeśli trenujesz model na zdjęciach kotów z Instagrama (profesjonalne, dobrze oświetlone, wykadrowane), a potem testujesz go na rozmytych fotkach z kamery monitoringu - założenie pada. Model się wywali. Dane treningowe i testowe pochodzą z różnych dystrybucji.
To samo dzieje się, gdy ChatGPT dostaje pytanie spoza zakresu danych treningowych. Nie "nie wie" - operuje w innej przestrzeni probabilistycznej. Znam to uczucie, gdy wpisujesz prompt i dostajesz odpowiedź totalnie obok tematu. Najczęściej to nie problem modelu, tylko naruszenie tego podstawowego założenia.
Drugie założenie - niezależność - brzmi technicznie, ale jest proste. Jeśli trenujesz model na danych giełdowych, gdzie cena akcji w dniu N zależy od ceny w dniu N-1, próbki NIE są niezależne. To szereg czasowy, nie losowa próbka. Standardowe algorytmy uczenia maszynowego to zignorowują i dadzą Ci wyniki, które wyglądają dobrze na papierze, ale w praktyce są bezwartościowe.
Większość kursów AI (włącznie z wieloma na Coursera czy Udemy) pomija ten detal. A to właśnie tutaj 80% projektów AI w firmach się sypie - przez złamane założenia, nie przez słaby model.
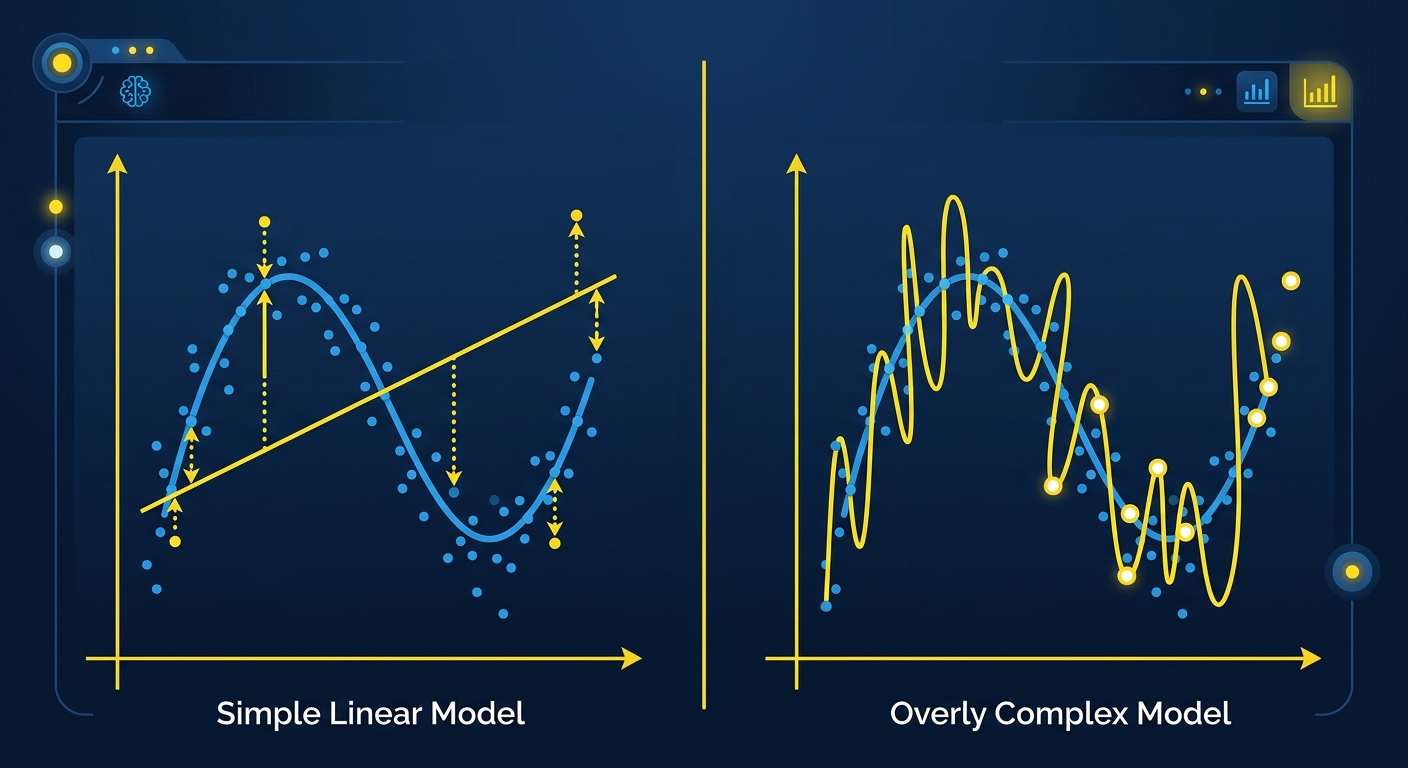
Każdy model AI ma dwa rodzaje błędu: bias (systematyczne odchylenie) i variance (wrażliwość na losowe fluktuacje w danych). I nie możesz zredukować obu jednocześnie.
Model z wysokim bias jest za prosty. Regresja liniowa próbująca opisać skomplikowaną krzywą - zawsze będzie się mylić w tym samym kierunku. Model z wysoką variance jest za skomplikowany. Sieć neuronowa z milionem parametrów, wytrenowana na 100 przykładach - zapamięta szum zamiast wzorca.
Praktyczny przykład: budujesz chatbota do obsługi klienta. Jeśli użyjesz prostego modelu opartego na słowach kluczowych (wysoki bias), będzie konsekwentnie mylić intencje użytkownika. Jeśli użyjesz GPT-5 bez fine-tuningu (wysoka variance), będzie genialny na testach, ale w produkcji zacznie halucynować fakty specyficzne dla Twojej firmy.
Stanford CS229 proponuje dekompozycję błędu na approximation error (jak dobry jest najlepszy możliwy model w danej klasie) i estimation error (jak daleko jesteś od tego optimum z powodu ograniczonej ilości danych). To bardziej użyteczny sposób myślenia niż abstrakcyjny bias-variance.
Approximation error odpowiada na pytanie: czy w ogóle wybrałeś odpowiednią klasę modeli? Jeśli próbujesz regresją liniową przewidzieć nieliniową zależność, approximation error będzie wysoki bez względu na ilość danych. Estimation error odpowiada na pytanie: czy masz wystarczająco dużo danych, żeby znaleźć najlepszy model w tej klasie?
Konkretnie: jeśli masz 100 przykładów i trenujesz model z 1000 parametrów, estimation error będzie gigantyczny. Model teoretycznie może być dobry (niska approximation error), ale nie masz szans go znaleźć z tak małym zbiorem danych.
Każdy algorytm uczenia maszynowego robi w gruncie rzeczy to samo: minimalizuje błąd na danych treningowych. To się nazywa empirical risk minimization (ERM). "Empiryczna", bo operujesz na skończonej próbce, nie na całej dystrybucji.
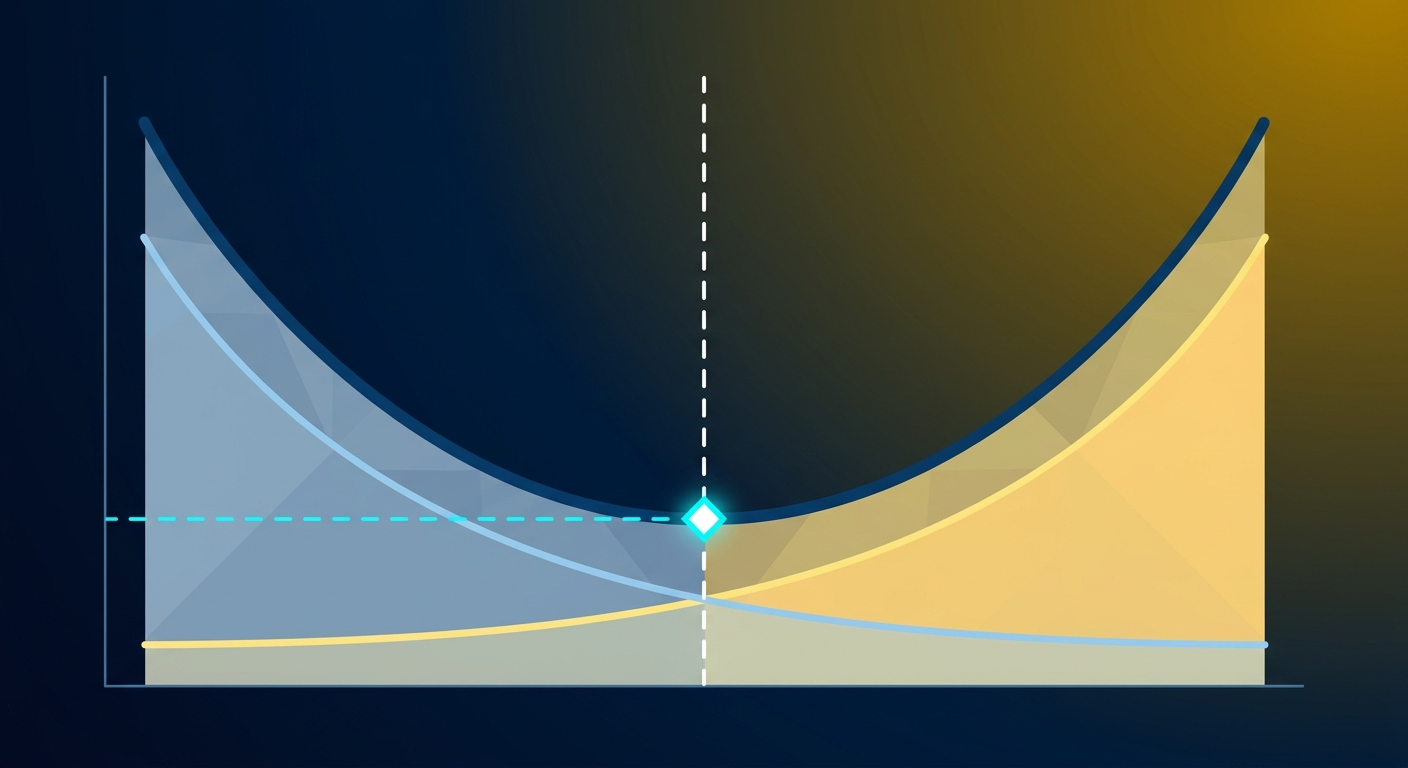
Problem? ERM nie gwarantuje, że model będzie dobrze działał na nowych danych. Możesz mieć zero błędu na zbiorze treningowym i 50% błędu na testowym. To się nazywa overfitting i każdy, kto trenował model, widział to na własne oczy.
Teoria uczenia maszynowego próbuje odpowiedzieć na pytanie: kiedy ERM faktycznie działa? Kiedy minimalizacja błędu treningowego prowadzi do dobrej generalizacji? Tu wchodzi uniform convergence.
Uniform convergence mówi, że jeśli masz wystarczająco dużo danych, błąd treningowy i błąd testowy będą blisko siebie - dla WSZYSTKICH modeli w danej klasie jednocześnie. Nie tylko dla tego jednego, który wybrałeś.
Czemu to ważne? Gwarantuje, że jak widzisz dobry wynik na zbiorze treningowym, to nie przypadek. Model faktycznie nauczył się wzorca, nie szumu. Ale to działa tylko wtedy, gdy klasa modeli nie jest za bogata (tu wchodzi VC dimension) i masz wystarczająco dużo danych.
Jeśli testujesz 100 różnych architektur sieci neuronowych na tym samym zbiorze walidacyjnym i wybierasz najlepszą, naruszasz uniform convergence. Wynik na walidacji przestaje być wiarygodnym estymatorem błędu testowego. Dlatego poważne projekty AI mają osobny zbiór testowy, którego NIE dotykasz do samego końca.
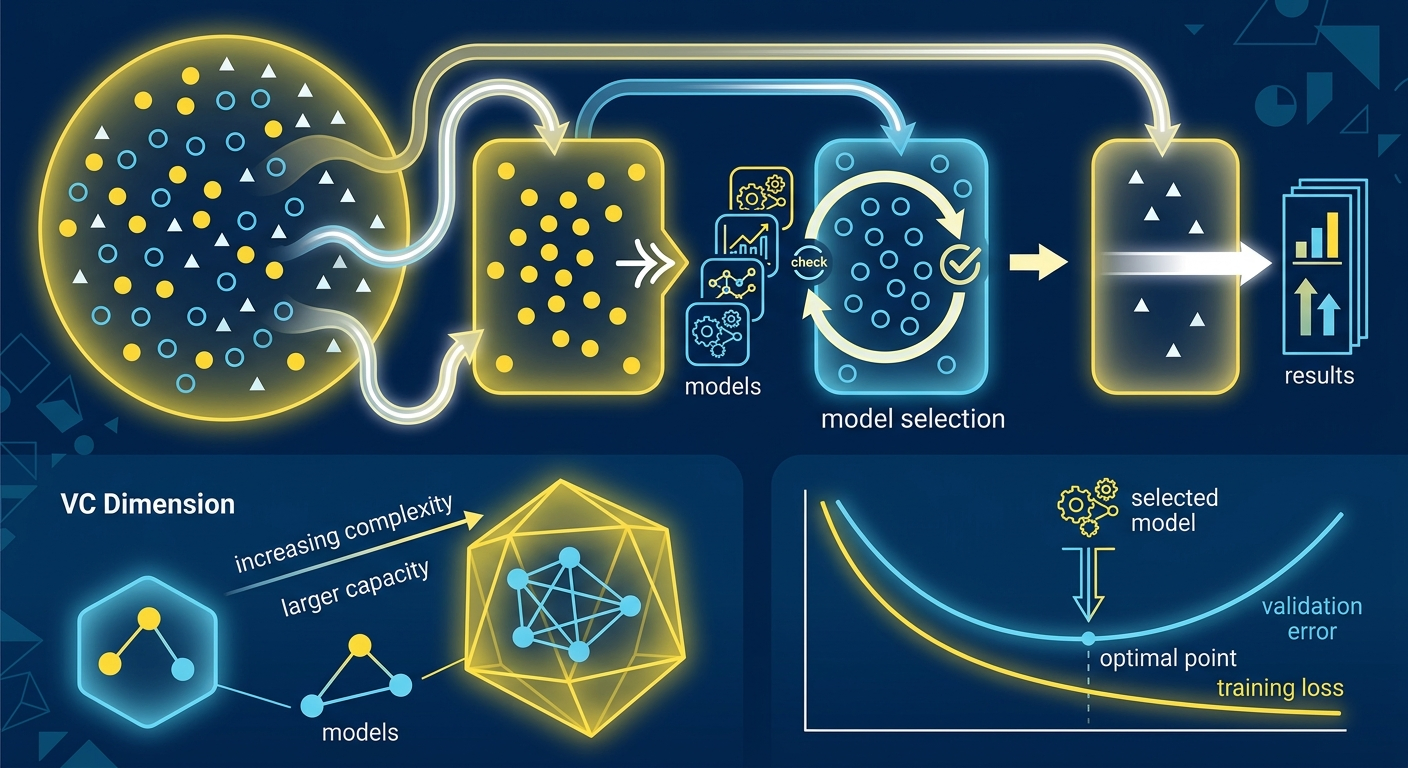
Vapnik-Chervonenkis dimension (VC dimension) to miara "pojemności" klasy modeli. Im wyższa VC dimension, tym bogatszą klasę funkcji możesz reprezentować - ale tym więcej danych potrzebujesz do treningu.
Dla regresji liniowej w d wymiarach, VC dimension wynosi d+1. Dla sieci neuronowych - może być rzędu milionów. To wyjaśnia, dlaczego GPT-5 potrzebował petabajtów danych treningowych, a prosty klasyfikator spam działa na kilku tysiącach emaili.
Teoria mówi, że żeby osiągnąć błąd ε z prawdopodobieństwem 1-δ, potrzebujesz mniej więcej O(VC/ε) przykładów. Konkretnie: jeśli VC dimension wynosi 1000 i chcesz 1% błędu z 95% pewnością, potrzebujesz rzędu 100 000 przykładów. To nie dokładny wzór (zależy od stałych), ale daje intuicję.
Jeśli budujesz model do klasyfikacji obrazów i masz 500 zdjęć, nie używaj ResNet-152 (miliony parametrów, gigantyczna VC dimension). Użyj prostszego modelu albo transfer learningu - wtedy efektywna VC dimension spada, bo większość parametrów jest zamrożona.
Jeśli fine-tunujesz Claude Opus 4.7 czy GPT-5 na swoich danych, pamiętaj: te modele mają astronomiczną VC dimension. Bez regularyzacji (dropout, weight decay, early stopping) overfitting jest gwarantowany. Dlatego wszystkie nowoczesne frameworki (Hugging Face, OpenAI API) mają wbudowane mechanizmy regularyzacji - to konieczność, nie opcja.
Możesz trenować modele bez znajomości teorii uczenia maszynowego. Możesz też prowadzić samochód bez znajomości termodynamiki silnika spalinowego. Ale gdy coś pójdzie nie tak - a pójdzie - teoria podpowie Ci, gdzie szukać problemu.
Model overfittuje? Sprawdź stosunek VC dimension do ilości danych. Wyniki na walidacji są dobre, ale w produkcji słabe? Naruszenie założenia o jednej dystrybucji. Błąd treningowy jest wysoki bez względu na to, co robisz? Wysoki approximation error - wybierasz za prostą klasę modeli.
Stanford CS229 uczy tej teorii nie przez wzgląd na matematyczną elegancję (choć jest), ale dlatego, że daje Ci narzędzia diagnostyczne. Gdy budujesz chatbota AI albo system rekomendacji, teoria uczenia maszynowego to Twój debug tool.
Jeszcze jedno: wszystkie nowoczesne techniki - dropout, batch normalization, data augmentation, ensemble methods - to praktyczne implementacje teoretycznych insights z lat 90. Teoria nie jest oderwana od praktyki. To praktyka oparta na solidnych fundamentach.
Ten poradnik to dopiero początek. W naszym kursie "Praktyczna AI" nauczysz się korzystać z ChatGPT, Claude i innych narzędzi AI w sposób systematyczny - od zera do zaawansowanego poziomu.
Sprawdź kurs →Nie musisz. Możesz używać narzędzi AI bez znajomości teorii - tak jak prowadzisz samochód bez znajomości mechaniki. Ale teoria pomaga zrozumieć, dlaczego model czasem się myli i jak pisać lepsze prompty - szczególnie gdy pracujesz z zaawansowanymi funkcjami jak Artifacts w Claude.
Overfitting to sytuacja, gdy model "zapamiętuje" dane treningowe zamiast uczyć się ogólnych wzorców. Objawia się niskim błędem treningowym i wysokim błędem testowym. Unikniesz go przez: więcej danych, prostszy model, regularyzację (dropout, weight decay) lub early stopping podczas treningu.
Zależy od VC dimension modelu. Prosty klasyfikator może potrzebować setek przykładów. Sieć neuronowa z milionami parametrów - dziesiątków tysięcy lub więcej. Jeśli masz mało danych, użyj transfer learningu (fine-tuning gotowego modelu jak GPT-5 czy Claude) zamiast trenować od zera.
Najczęstsza przyczyna: dane treningowe i produkcyjne pochodzą z różnych dystrybucji. Przykład: trenujesz na zdjęciach z Instagrama, testujesz na zdjęciach z aparatu telefonu. Albo: trenujesz na danych z 2023 roku, wdrażasz w 2026 - świat się zmienił. Rozwiązanie: regularnie aktualizuj dane treningowe lub użyj technik domain adaptation.
To balans między prostotą a złożonością modelu. Za prosty model (wysoki bias) systematycznie się myli. Za skomplikowany (wysoka variance) reaguje na losowy szum w danych. Znalezienie balansu wymaga eksperymentów - zacznij od prostego modelu i stopniowo zwiększaj złożoność, obserwując błąd walidacyjny.
10 gotowych promptów do codziennej pracy + 5 narzędzi + plan na pierwszy tydzień. PDF, 4 strony konkretu.

Uczenie przez wzmacnianie sprawia, że ChatGPT rozumie kontekst, a nie tylko składa słowa. Wyjaśniamy krok po kroku, jak to działa i dlaczego ma znaczenie.

Statystyka i prawdopodobieństwo to fundament AI. Wyjaśniamy kluczowe pojęcia prostym językiem - bez matematycznego żargonu, z praktycznymi przykładami.

Python i biblioteka Pandas to fundament pracy z danymi w AI. Dowiedz się, jak przetwarzać tabelki, tekst i obrazy bez doktoratu z informatyki - konkretnie i krok po kroku.

Gradient descent to fundament uczenia maszynowego. Dowiedz się krok po kroku, jak sieci neuronowe uczą się rozpoznawać obrazy i wzorce - bez matematyki wyższej.

Dowiedz się, jak zintegrować Codex CLI z GitLab, aby automatycznie wykrywać błędy w kodzie i luki bezpieczeństwa. Praktyczny poradnik krok po kroku dla zespołów bez głębokiej wiedzy technicznej.

Badania o prompt engineeringu i LLM wyglądają jak chińszczyzna? Pokazuję, jak wyciągać z nich konkretną wiedzę - bez znajomości statystyki.
