Narzedzia AI
·
6 min czytania
·
1 maja 2026
Gemini Embedding 2 - jeden model dla tekstu, obrazu i dźwięku

Źródło: Link
Źródło: Link
118 lekcji bez kodowania. ChatGPT, Claude, Gemini, automatyzacje. Notatnik AI i AI Coach w cenie.
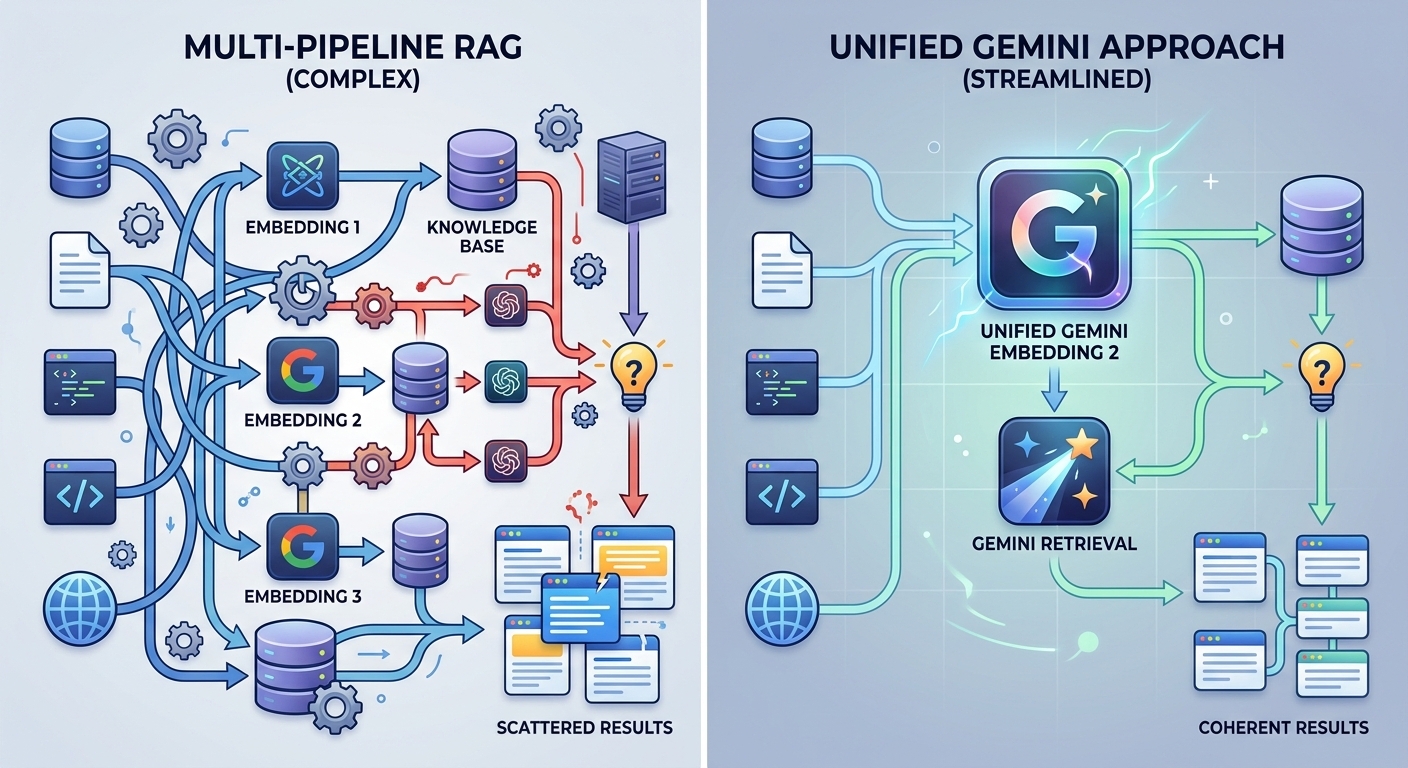
Większość systemów AI traktuje tekst, obraz i dźwięk jak osobne światy. Chcesz przeszukać bazę wiedzy z raportami PDF, nagraniami spotkań i slajdami? Musisz zbudować trzy różne pipeline'y, zsynchronizować wyniki i mieć nadzieję, że coś sensownego z tego wyjdzie.
Google właśnie wypuściło narzędzie, które to upraszcza. Gemini Embedding 2 mapuje wszystkie te formaty w jednej przestrzeni semantycznej. Jeden model, jedno zapytanie, zero żonglowania.

Gemini Embedding 2 to model embeddingowy, który rozumie tekst, obrazy, wideo, audio i dokumenty w jednym zapytaniu. Nie musisz osobno przetwarzać PDF-a, potem wyciągać z niego obrazków, potem transkrybować nagrania. Wysyłasz wszystko naraz, a model zwraca wektory w tej samej przestrzeni semantycznej.
Co to oznacza w praktyce? Budujesz system RAG (Retrieval-Augmented Generation), który ma przeszukiwać bazę wiedzy z raportami, prezentacjami i nagraniami. Dotychczas potrzebowałeś osobnych modeli dla każdego formatu. Gemini Embedding 2 przetwarza wszystko w jednym kroku.
Wysyłasz zapytanie "pokaż mi wszystkie dane o kampanii Q3". System zwraca fragmenty tekstu z raportów, slajdy z wykresami i fragmenty nagrań ze spotkań - wszystko posortowane według trafności.
Google podaje, że model poprawia wydajność w zadaniach multimodalnych - szczególnie tam, gdzie kontekst wymaga zrozumienia relacji między formatami. Przykład: raport finansowy z wykresami. Tekst mówi "wzrost o 23%", wykres pokazuje trend, a nagranie CEO wyjaśnia przyczyny. Gemini Embedding 2 rozumie, że to wszystko dotyczy tego samego faktu - i zwraca kompletny kontekst, nie trzy osobne fragmenty.
Model mapuje różne formaty danych (tekst, obraz, audio, wideo) na wektory w tej samej przestrzeni. Jeśli dwa elementy są semantycznie podobne - nawet jeśli jeden to tekst, a drugi obraz - ich wektory będą blisko siebie.
To pozwala na cross-modal retrieval: wysyłasz zapytanie tekstowe, a dostajesz trafne obrazy. Albo odwrotnie - wysyłasz zdjęcie, a dostajesz opisy tekstowe.
Google udostępnia model przez Vertex AI i Google AI Studio. Możesz wysłać jednym zapytaniem interleaved input - czyli np. tekst + obraz + fragment wideo - i dostać embedding, który uwzględnia kontekst między nimi. Nie musisz osobno przetwarzać każdego formatu i potem ręcznie łączyć wyników.
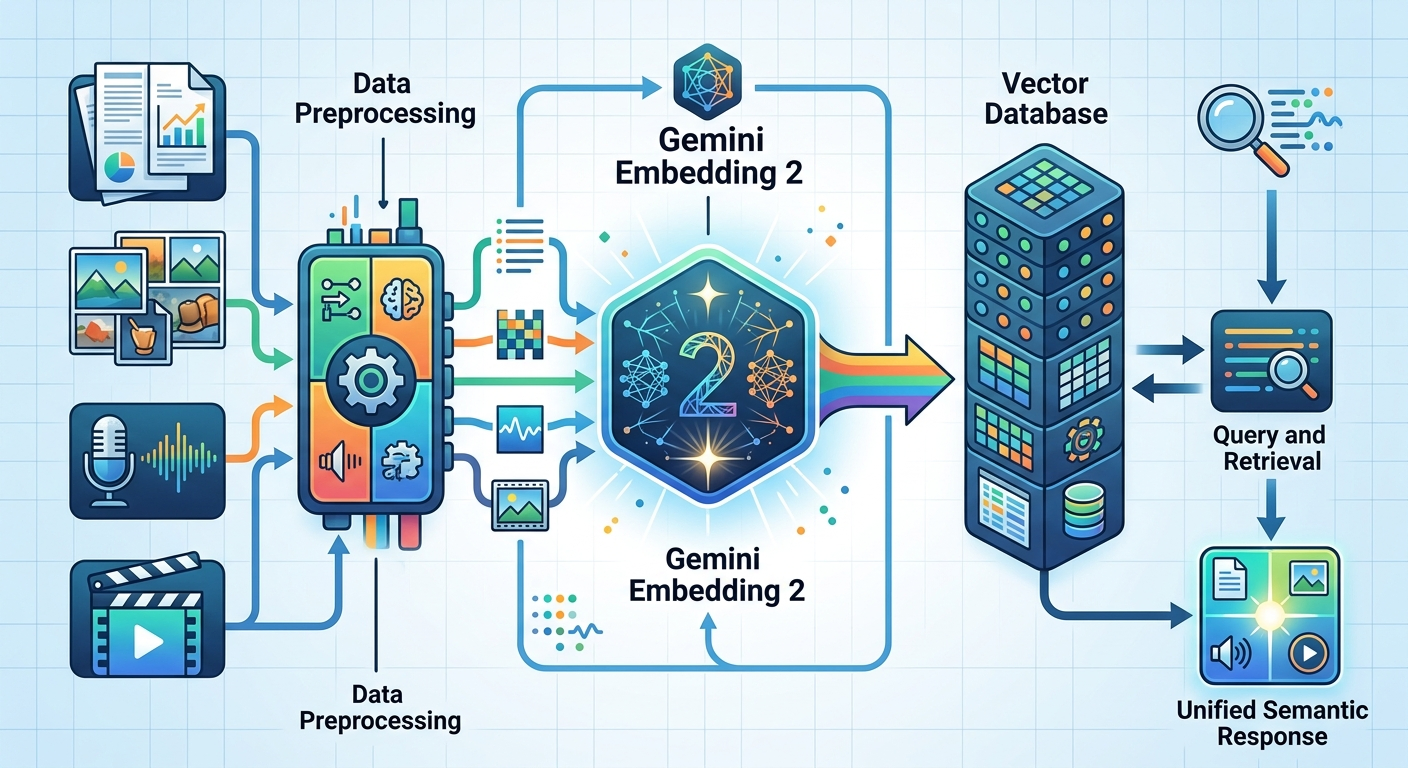
Google pokazuje, jak Gemini Embedding 2 działa w systemach agentowych. Przykład: agent AI, który analizuje dokumentację produktu. Dokumentacja to nie tylko tekst - to diagramy, zrzuty ekranu, nagrania demo, PDF-y z tabelami.
Dotychczas agent musiał mieć osobne moduły dla każdego formatu. Teraz wysyła wszystko do Gemini Embedding 2 i dostaje ujednolicony kontekst.
Kolejny przykład z bloga Google: multimodal RAG dla e-commerce. Klient pyta "pokaż mi produkty podobne do tego na zdjęciu, ale w innym kolorze". System musi zrozumieć obraz (co jest na zdjęciu), tekst ("inny kolor") i połączyć to z bazą produktów (która ma opisy tekstowe + zdjęcia).
Gemini Embedding 2 robi to w jednym zapytaniu - bez osobnych pipeline'ów dla vision i text retrieval.
Jeśli budujesz agentów AI, którzy mają działać w środowisku z różnymi formatami danych - to narzędzie upraszcza architekturę. Zamiast synchronizować wyniki z pięciu modeli, wysyłasz wszystko do jednego i dostajesz spójny wynik.
Gemini Embedding 2 ma sens tam, gdzie dane są rzeczywiście multimodalne - i gdzie kontekst wymaga zrozumienia relacji między formatami. Przykłady:
Nie ma sensu tam, gdzie dane są jednorodne. Jeśli masz tylko tekst - zwykły model embeddingowy (np. text-embedding-004 od Google, czy DeepSeek V4 z API) będzie szybszy i tańszy.
Gemini Embedding 2 to narzędzie dla przypadków, gdzie musisz łączyć formaty - nie dla każdego projektu.
Model jest dostępny przez Google AI Studio (dla prototypów i testów) oraz Vertex AI (dla produkcji). Google udostępnia dokumentację z przykładami kodu - pokazują, jak wysłać interleaved input (tekst + obraz + wideo w jednym zapytaniu) i jak zbudować multimodal RAG.
Jeśli masz już system RAG oparty na tekście i chcesz dodać obsługę obrazów czy wideo - Gemini Embedding 2 pozwala to zrobić bez przepisywania całej architektury. Wysyłasz nowe formaty do tego samego modelu, dostajesz embeddingi w tej samej przestrzeni - i możesz je dodać do istniejącej bazy wektorowej.
Cena? Google nie podaje szczegółów w ogłoszeniu - musisz sprawdzić w Vertex AI pricing. Typowo embeddingi kosztują ułamek tego, co inference dużych modeli (GPT-5, Claude Opus 4.7), ale jeśli przetwarzasz wideo i audio na dużą skalę - koszty mogą rosnąć szybciej niż przy samym tekście.
Gemini Embedding 2 to narzędzie dla konkretnego przypadku: masz dane w różnych formatach i potrzebujesz je przeszukiwać w jednym systemie. Jeśli to Twój case - warto przetestować. Jeśli pracujesz tylko z tekstem - zostań przy prostszych (i tańszych) modelach.
Nie każdy projekt potrzebuje multimodalności - ale tam, gdzie potrzebuje, różnica między jednym modelem a pięcioma osobnymi pipeline'ami jest konkretna.
Na podstawie: Google Developers Blog
Podoba Ci się ten artykuł?
Co piątek wysyłam podsumowanie najlepszych artykułów tygodnia. Zapisz się!
90 minut praktycznej wiedzy o AI. Pokaze Ci krok po kroku, jak zaczac oszczedzac 10 godzin tygodniowo dzieki sztucznej inteligencji.
Zapisz sie na webinar
Google aktualizuje Gemini Live, dodając pamięć długoterminową i integrację z Gmail, Keep i YouTube. Asystent przestaje zapominać o Twoich preferencjach.

Google wypuszcza pierwszy głośnik od 6 lat. Gorsza jakość dźwięku, ale Gemini w środku. Czy AI ratuje przeciętny sprzęt?

Gemini przeszedł na limity 5-godzinne. Błędy AI liczą się do limitu, a użytkownicy tracą dostęp po kilku promptach. Google ma więcej zasobów niż Anthropic, ale ogranicza bardziej.

Google Gemini to nie jedno narzędzie, tylko cały ekosystem. Zobacz, czym różnią się Flash, Pro, Studio i API oraz jak wybrać wersję do swojej pracy.

Google uruchamia Gemini 3.5 Live Translate - model audio tłumaczący mowę w ponad 70 językach niemal natychmiast. Dostępny w Google AI Studio, Translate i Meet.

Google udostępnia Gemini w smartfonach z Android Go - modelach za mniej niż 1000 zł. Asystent AI zastępuje Google Assistant bez instalowania dodatkowych aplikacji.
