Modele AI
·
5 min czytania
·
26 lutego 2026
Gemini widzi i edytuje obiekty na zdjęciach. Jak to działa?

Źródło: Link
Źródło: Link
Mówią, że AI rozumie obrazy. Dostajemy narzędzie, które nie tylko rozumie, ale też potrafi je edytować - bez Photoshopa, bez kursów, bez godzin na YouTube. Gemini od Google właśnie nauczył się wykrywać konkretne obiekty na zdjęciach i zmieniać je według Twoich instrukcji.
Dobra, powiedzmy to wprost: to nie jest kolejny filtr do selfie. Wskazujesz palcem (dosłownie - tekstem) element na zdjęciu i mówisz "usuń to", "napraw to" albo "zmień to na coś innego". Model wie, o co Ci chodzi.

Model działa w trzech trybach. Możesz je łączyć w jednym procesie.
Pierwszy to detekcja. Gemini analizuje obraz i identyfikuje wszystkie obiekty, które widzi. Nie mówi tylko "to jest pies". Wskazuje dokładnie, gdzie ten pies się znajduje i jak duży fragment obrazu zajmuje.
Drugi tryb to restauracja. Masz stare zdjęcie z zarysowaniami? Fotografię produktu z niechcianym elementem w tle? Model przywraca uszkodzone fragmenty lub usuwa wybrane obiekty, wypełniając przestrzeń w sposób, który pasuje do reszty obrazu.
Trzeci tryb - transformacja - pozwala zmieniać konkretne elementy. Możesz poprosić o zmianę koloru obiektu, jego stylu, a nawet zastąpienie go czymś zupełnie innym. Model rozumie kontekst i stara się zachować spójność z resztą zdjęcia.
Zamiast otwierać edytor graficzny i ręcznie zaznaczać obszary, piszesz: "Usuń parasol z lewej strony" albo "Zmień kolor samochodu na niebieski". Gemini sam lokalizuje obiekt i wykonuje operację.
Jeśli na zdjęciu jest kilka podobnych elementów, możesz doprecyzować: "ten samochód bliżej kamery" lub "parasol po lewej stronie kobiety".
Model korzysta z tego samego mechanizmu rozumienia wizualnego, który pozwala mu analizować złożone dokumenty i wykresy. Różnica? Teraz nie tylko opisuje to, co widzi - modyfikuje to.
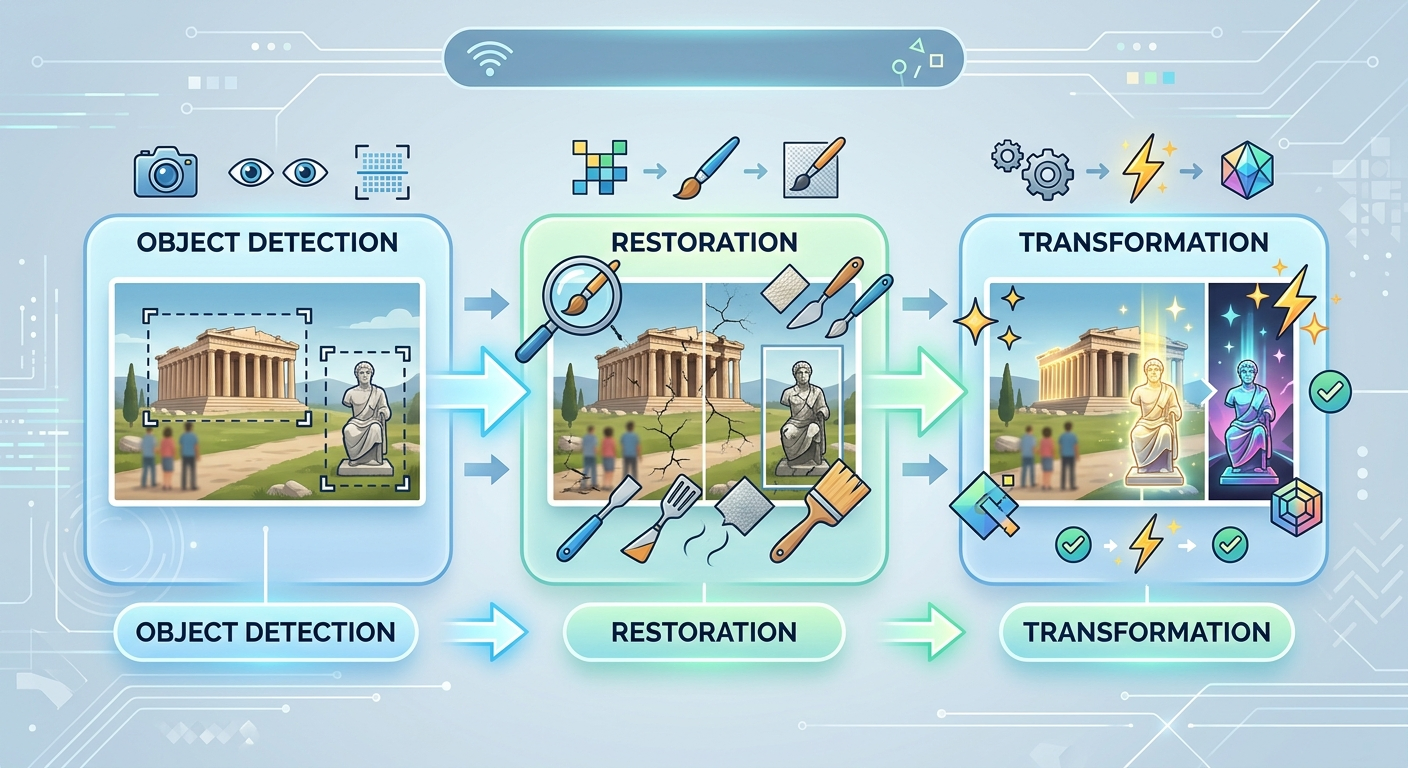
Praktyczne zastosowania dzielą się na dwie kategorie: naprawianie tego, co masz, i tworzenie tego, czego potrzebujesz.
W pierwszej kategorii: retusz zdjęć produktowych (usunięcie niechcianych elementów tła), naprawa starych fotografii (uzupełnienie uszkodzonych fragmentów), czyszczenie obrazów do prezentacji (pozbycie się rozpraszających detali). Zamiast płacić grafika lub spędzać godziny na nauce narzędzi, dajesz modelowi instrukcję tekstową.
W drugiej kategorii: szybkie prototypowanie wizualne ("pokaż mi ten produkt w trzech kolorach"), przygotowanie wariantów grafik marketingowych, testowanie różnych wersji layoutu. Podobnie jak gotowe instrukcje w Claude przyspieszają pracę z tekstem, Gemini przyspiesza iteracje wizualne.
Model radzi sobie lepiej z prostymi obiektami niż ze złożonymi scenami. Chcesz usunąć człowieka z tłumu? Efekt może być mniej precyzyjny niż przy usuwaniu pojedynczego przedmiotu z czystego tła.
Gemini ma też problemy z bardzo małymi obiektami. Im większy element na zdjęciu, tym lepsza detekcja.
Kolejna rzecz: model działa na podstawie opisu tekstowego, więc musisz umieć nazwać to, co chcesz zmienić. Nie wiesz, jak nazywa się konkretny element? Możesz opisać jego położenie ("obiekt w prawym górnym rogu"), ale to wymaga precyzji.
Zrób jedną rzecz: weź zdjęcie, na którym jest coś, co chcesz usunąć lub zmienić. Nie wybieraj od razu skomplikowanej sceny - zacznij od prostego przypadku. Zdjęcie produktu z jednym niechcianym elementem w tle to dobry start.
Napisz instrukcję jak najbardziej konkretnie. Zamiast "usuń to", napisz "usuń czerwoną torebkę po lewej stronie". Zamiast "zmień kolor", napisz "zmień kolor samochodu na ciemnoniebieski". Im precyzyjniejszy opis, tym lepszy efekt.
Jeśli wynik nie jest idealny za pierwszym razem, spróbuj zmienić sposób opisu. Model może inaczej zinterpretować "usuń osobę w tle" niż "usuń mężczyznę stojącego za główną postacią". Testowanie różnych sformułowań to część procesu - tak samo jak przy optymalizacji promptów tekstowych.

Przygotowujesz materiały wizualne - do prezentacji, na stronę, do mediów społecznościowych? Właśnie dostałeś narzędzie, które eliminuje wąskie gardło.
Nie musisz czekać na grafika, żeby usunąć jeden element ze zdjęcia. Nie musisz uczyć się Photoshopa, żeby przetestować trzy warianty koloru produktu.
Dla osób pracujących w marketingu czy e-commerce to konkretna oszczędność czasu. Zamiast zlecać zewnętrznie retusz dziesiątek zdjęć produktowych, robisz to sam w kilka minut. Zamiast czekać tydzień na warianty grafik, testujesz je tego samego dnia.
Gemini nie zastąpi profesjonalnego grafika przy złożonych projektach (podobnie jak ChatGPT nie zastępuje copywritera przy kampaniach reklamowych). Zastąpi go przy 80% rutynowych zadań, które do tej pory pochłaniały czas i budżet.
Znajdź jedno zdjęcie, które masz już gotowe, ale wymaga drobnej poprawki. Może to być zdjęcie produktu z niechcianym cieniem, fotografia z prezentacji z literówką na slajdzie w tle, albo stare zdjęcie z rodziną, które ma uszkodzony fragment. Otwórz Gemini i napisz konkretną instrukcję, co chcesz zmienić.
Nie testuj możliwości modelu abstrakcyjnie. Rozwiąż jeden realny problem, który masz teraz. Zobaczysz od razu, czy narzędzie ma sens w Twoim przypadku, czy wymaga więcej pracy niż tradycyjna metoda. I będziesz wiedział, kiedy po nie sięgnąć następnym razem.
Przeczytaj też:
10 gotowych promptów do codziennej pracy + 5 narzędzi + plan na pierwszy tydzień. PDF, 4 strony konkretu.

Google rozszerza rodzinę Gemini o trzy modele: 3.6 Flash, 3.5 Flash-Lite i 3.5 Flash Cyber. Stawka jest prosta: niższy koszt, większa skala i mocniejszy nacisk na bezpieczeństwo.

Google wykorzystuje Twoje rozmowy z Gemini do szkolenia modeli AI. Możesz to zatrzymać - wystarczy zmienić kilka ustawień prywatności.

Google aktualizuje Gemini Live, dodając pamięć długoterminową i integrację z Gmail, Keep i YouTube. Asystent przestaje zapominać o Twoich preferencjach.

Gemini przeszedł na limity 5-godzinne. Błędy AI liczą się do limitu, a użytkownicy tracą dostęp po kilku promptach. Google ma więcej zasobów niż Anthropic, ale ogranicza bardziej.

19 maja 2026 Google wypuścił Gemini 3.5 Flash - model, który bije własnego flagowca Gemini 3.1 Pro w większości benchmarków. I robi to przy 300 tokenach na sekundę.

Gemini 3.5 Live Translate kończy z robotycznymi tłumaczeniami. Model odtwarza Twój głos, intonację i tempo - w czasie rzeczywistym, w 70 językach.
