Poradniki
·
13 min czytania
·
24 maja 2026
Jak działa RAG - przewodnik po AI, która czyta Twoje dokumenty

Źródło: Link
Źródło: Link
118 lekcji bez kodowania. ChatGPT, Claude, Gemini, automatyzacje. Notatnik AI i AI Coach w cenie.
Koleżanka z działu HR przyszła do mnie w zeszłym tygodniu z pytaniem: "Jak to jest, że ChatGPT nie zna naszych wewnętrznych procedur, ale te nowe narzędzia firmowe już tak?" Odpowiedź brzmi: RAG. I nie, to nie skrót od rage quit, tylko od Retrieval Augmented Generation.
To technologia, która sprawia, że AI potrafi rozmawiać o Twoich dokumentach, kontraktach, bazach wiedzy - jakby je faktycznie przeczytała. Bez trenowania modelu od zera. Bez wysyłania wszystkiego do OpenAI. Po prostu: wrzucasz plik, zadajesz pytanie, dostajesz odpowiedź opartą na tym, co w nim jest.
RAG to sposób na połączenie dwóch rzeczy: wyszukiwania informacji i generowania tekstu przez AI. Zamiast polegać wyłącznie na tym, co model "pamięta" z treningu, RAG najpierw szuka odpowiednich fragmentów w Twoich dokumentach, a potem używa ich jako kontekstu do odpowiedzi.
Ktoś pyta Cię o szczegóły umowy z 2019 roku. Zamiast polegać na pamięci, najpierw otwierasz archiwum, znajdujesz dokument, czytasz kluczowe fragmenty - i dopiero wtedy odpowiadasz. RAG działa podobnie. Robi to w ułamku sekundy.
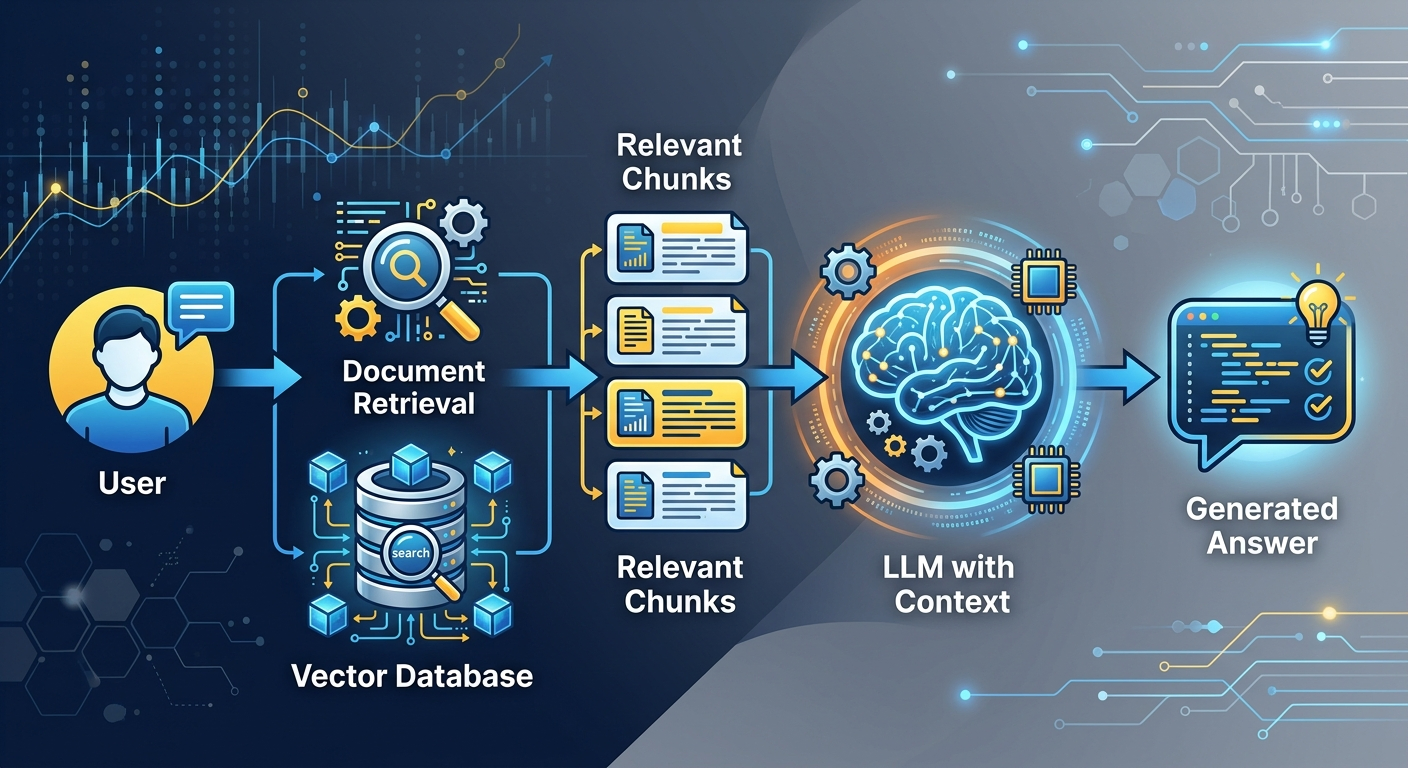
RAG to nie jeden algorytm, tylko system złożony z trzech części:
Kluczowa różnica między RAG a zwykłym promptem? Zwykły prompt wysyła do modelu tylko Twoje pytanie. RAG wysyła pytanie PLUS odpowiednie fragmenty z Twoich dokumentów. Model nie musi "pamiętać" - dostaje fakty na talerzu.
Embeddingi to fundament RAG. Bez nich nie ma wyszukiwania semantycznego, a bez wyszukiwania semantycznego - nie ma sensu cały system.
Prosty przykład: masz dwa zdania. "Kot siedzi na macie" i "Zwierzę domowe odpoczywa na dywanie". Dla człowieka to podobne znaczenia. Dla komputera? Zero wspólnych słów. Embeddingi rozwiązują ten problem - zamieniają oba zdania w wektory (np. 1536 liczb), które są do siebie matematycznie bliskie, bo ZNACZĄ podobne rzeczy.
Kiedy wrzucasz dokument do systemu RAG, dzieje się to:
Kiedy zadajesz pytanie, Twoje pytanie TEŻ zamienia się w wektor. Baza porównuje go z wektorami dokumentów i zwraca np. 5 najbardziej podobnych chunków. Te chunki trafiają do modelu językowego jako kontekst.

Tradycyjne wyszukiwanie (keyword search) szuka dokładnych dopasowań. Piszesz "umowa najmu" - znajduje dokumenty z tymi słowami. Jeśli w dokumencie jest "kontrakt wynajmu mieszkania", keyword search może go przegapić.
Wyszukiwanie wektorowe (semantic search) rozumie, że "umowa najmu" i "kontrakt wynajmu" to to samo. Znajduje dokumenty na podstawie ZNACZENIA, nie liter. To ogromna różnica w praktyce - szczególnie gdy masz tysiące dokumentów w różnych formatach i językach.
Zwykła baza danych (PostgreSQL, MySQL) nie nadaje się do przechowywania embeddingów. Możesz tam wrzucić wektory, nie będziesz w stanie szybko znaleźć "najbardziej podobnych". Do tego potrzebna jest baza wektorowa.
Która wybrać? Jeśli testujesz pomysł - ChromaDB. Jeśli budujesz produkcyjny system i nie chcesz zarządzać infrastrukturą - Pinecone. Jeśli masz devopsa w zespole i wolisz kontrolę - Weaviate lub Qdrant.
Teoria to jedno, praktyka to drugie. Pokażę Ci, jak zbudować działający system RAG bez kodowania od zera - używając gotowych narzędzi.
Potrzebujesz:
Nie musisz być programistą. Jeśli potrafisz skopiować kod i wpisać komendy - dasz radę.
Zbierz dokumenty, które chcesz "podłączyć" do AI. Mogą to być:
Wrzuć je do jednego folderu na dysku. Nazwij go np. "documents". Im bardziej uporządkowane, tym łatwiej później zarządzać systemem.
Otwierasz terminal i wpisujesz:
pip install langchain openai pinecone-client pypdfLangChain to framework, który łączy embeddingi, bazy wektorowe i modele językowe. Zamiast pisać setki linii kodu, używasz gotowych bloków.
Kopiujesz poniższy skrypt do pliku create_embeddings.py:
from langchain.document_loaders import DirectoryLoader, PyPDFLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.embeddings import OpenAIEmbeddings
from langchain.vectorstores import Pinecone
import pinecone
# Wczytujesz dokumenty z folderu
loader = DirectoryLoader('./documents', glob="**/*.pdf", loader_cls=PyPDFLoader)
documents = loader.load()
# Dzielisz na chunki po 500 znaków z 50-znakowym nakładaniem
text_splitter = RecursiveCharacterTextSplitter(chunk_size=500, chunk_overlap=50)
chunks = text_splitter.split_documents(documents)
# Tworzysz embeddingi przez OpenAI
embeddings = OpenAIEmbeddings(model="text-embedding-3-large")
# Łączysz się z Pinecone i wrzucasz chunki
pinecone.init(api_key="TWOJ_KLUCZ_API", environment="us-west1-gcp")
vectorstore = Pinecone.from_documents(chunks, embeddings, index_name="moje-dokumenty")
print(f"Dodano {len(chunks)} chunków do bazy wektorowej")Zamieniasz TWOJ_KLUCZ_API na prawdziwy klucz z Pinecone (znajdziesz go w panelu po zalogowaniu). Uruchamiasz:
python create_embeddings.pySkrypt przeczyta wszystkie PDF-y, podzieli je na kawałki, zamieni w wektory i wyśle do Pinecone. Przy 100 stronach dokumentów zajmie to 2-3 minuty.

Teraz tworzysz drugi skrypt - query.py:
from langchain.embeddings import OpenAIEmbeddings
from langchain.vectorstores import Pinecone
from langchain.chat_models import ChatOpenAI
from langchain.chains import RetrievalQA
import pinecone
# Łączysz się z bazą wektorową
pinecone.init(api_key="TWOJ_KLUCZ_API", environment="us-west1-gcp")
embeddings = OpenAIEmbeddings(model="text-embedding-3-large")
vectorstore = Pinecone.from_existing_index("moje-dokumenty", embeddings)
# Tworzysz łańcuch RAG z Claude lub GPT
llm = ChatOpenAI(model="gpt-5", temperature=0)
qa_chain = RetrievalQA.from_chain_type(
llm=llm,
chain_type="stuff",
retriever=vectorstore.as_retriever(search_kwargs={"k": 5})
)
# Zadajesz pytanie
question = "Jakie są warunki rozwiązania umowy?"
result = qa_chain.run(question)
print(result)Uruchamiasz:
python query.pySystem znajdzie 5 najbardziej pasujących fragmentów z Twoich dokumentów, wyśle je do GPT-5 jako kontekst i wydrukuje odpowiedź. Cały proces trwa 2-3 sekundy.
Zmieniasz wartość zmiennej question w skrypcie i sprawdzasz, jak system radzi sobie z różnymi zapytaniami:
Jeśli odpowiedzi są zbyt ogólne - zwiększ chunk_size do 800. Jeśli system nie znajduje odpowiedzi - zmniejsz do 300 i zwiększ k (liczba zwracanych chunków) do 8-10.
Najczęstsza przyczyna: chunki są za duże albo za małe. Jeśli chunk ma 2000 znaków, model dostaje zbyt dużo kontekstu i gubi się. Jeśli ma 100 znaków - za mało informacji.
Rozwiązanie: testuj różne wartości chunk_size. Dla dokumentów technicznych (umowy, instrukcje) - 400-600 znaków. Dla tekstów narracyjnych (artykuły, raporty) - 600-1000 znaków.
Embeddingi kosztują. Jeśli masz 1000 stron dokumentów podzielonych na chunki po 500 znaków, to około 100 000 tokenów embeddingowych. text-embedding-3-large kosztuje $0.13 za milion tokenów, więc ~$0.013. Nie dużo.
Zapytania to inna historia. Każde pytanie wysyła 5-10 chunków do GPT-5 (około 2000-4000 tokenów kontekstu). Przy $30 za milion tokenów wejściowych to $0.06-0.12 na zapytanie. 100 zapytań dziennie = $6-12 dziennie.
Rozwiązanie: użyj tańszego modelu do odpowiedzi. GPT-5-mini kosztuje $0.15/$0.60 za milion tokenów (20x taniej niż GPT-5). Dla większości przypadków wystarczy. Albo Claude Haiku 4.5 - jeszcze tańszy i szybszy.
Dwie możliwe przyczyny:
k z 5 do 10. System przeszuka więcej fragmentów i ma większą szansę trafić w odpowiedni.Podstawowy RAG działa dobrze dla prostych przypadków. Jeśli masz tysiące dokumentów, złożone zapytania lub potrzebujesz wysokiej precyzji - musisz użyć bardziej zaawansowanych technik.
Czasami wyszukiwanie semantyczne przegapia dokładne dopasowania. Przykład: szukasz "artykuł 15 ust. 3" w umowie. Wyszukiwanie wektorowe może zwrócić fragmenty o podobnej TEMATYCE, nie ten konkretny artykuł.
Hybrid search łączy oba podejścia - wektorowe (semantic) i keyword (BM25). Weaviate i Qdrant mają to wbudowane. Pinecone wymaga dodatkowej warstwy (np. Elasticsearch obok).
Baza wektorowa zwraca np. 20 chunków. Zamiast wysyłać wszystkie do modelu, używasz modelu rerankingowego (np. Cohere Rerank lub Voyage Rerank), który ocenia każdy chunk pod kątem DOKŁADNEGO dopasowania do pytania i wybiera top 5.
Koszt dodatkowy: $1 za 1000 zapytań (Cohere). Jakość odpowiedzi rośnie o 15-30% w testach.
Zamiast jednego zapytania do bazy wektorowej, system generuje 3-5 wariantów Twojego pytania i szuka osobno dla każdego. Potem łączy wyniki.
Przykład: pytasz "Jak rozwiązać umowę?". System generuje warianty: "procedura rozwiązania umowy", "warunki wypowiedzenia kontraktu", "anulowanie umowy najmu". Każdy wariant może trafić w inne fragmenty dokumentów.
Implementacja w LangChain zajmuje 10 linii kodu. Koszt rośnie (więcej zapytań embeddingowych), precyzja też.
RAG nie jest uniwersalnym rozwiązaniem. Są sytuacje, gdzie sprawdza się świetnie - i takie, gdzie lepiej użyć czegoś innego.
Nie musisz kodować, żeby użyć RAG. Jest kilka narzędzi, które dają gotowy interfejs.
Jeśli Twoja firma ma plan Enterprise, możesz wrzucić dokumenty do "Knowledge Base" i ChatGPT automatycznie użyje ich jako kontekstu. Zero setupu, działa od ręki. Drogie ($60/użytkownik/miesiąc) i tylko dla firm.
Notion dodał funkcję AI Q&A, która przeszukuje Twoją workspace i odpowiada na pytania. Działa na zasadzie RAG, nie masz kontroli nad chunkowaniem ani modelem embeddingowym. Wystarczające dla małych zespołów.
Glean łączy się z Google Drive, Slack, Confluence, Jira i innymi narzędziami firmowymi. Indeksuje wszystko, tworzy embeddingi i daje interfejs do pytań. Drogie (custom pricing), jeśli masz rozproszone dane w 10+ systemach - może się opłacić.
Jeśli chcesz kontrolę, nie chcesz pisać kodu od zera - Dify to złoty środek. Instalujesz lokalnie (Docker), wrzucasz dokumenty przez interfejs webowy, konfigurujesz chunking i embeddingi - gotowe. Możesz hostować sam lub użyć ich clouda.
Tak, modele embeddingowe (text-embedding-3-large, voyage-02) są wielojęzyczne i radzą sobie z polskim tekstem bez problemu. Również modele językowe (GPT-5, Claude Opus 4.7) rozumieją polski kontekst. Jedyna różnica: jakość embeddingów dla polskiego jest ~5-10% niższa niż dla angielskiego, bo modele były trenowane głównie na angielskich danych. W praktyce różnica jest niezauważalna dla większości zastosowań.
Zależy od wolumenu. Przykładowy breakdown: 500 stron dokumentów (około 250 000 tokenów) to ~$0.03 za embeddingi (jednorazowo). Pinecone free tier obsługuje do 100 000 wektorów (wystarczy na ~50 000 stron). Zapytania: jeśli używasz GPT-5-mini, to $0.15 za milion tokenów wejściowych. Przy 100 zapytaniach dziennie (każde ~3000 tokenów kontekstu) to $0.045 dziennie = ~$1.35 miesięcznie. Realistyczny koszt dla małej firmy: $5-20 miesięcznie.
Tak, musisz użyć lokalnych modeli. Zamiast OpenAI embeddings - użyj modelu z Hugging Face (np. sentence-transformers/all-MiniLM-L6-v2). Zamiast GPT-5 - użyj lokalnego LLM (np. Llama 4 Scout przez Ollama). Zamiast Pinecone - użyj ChromaDB lokalnie. Całość może działać na Twoim serwerze bez wysyłania czegokolwiek na zewnątrz. Jakość będzie niższa niż z komercyjnymi modelami, dla wrażliwych danych to jedyna opcja.
Zależy od dynamiki zmian. Jeśli dokumenty zmieniają się codziennie (np. baza wiedzy produktowej) - uruchom skrypt embeddingowy raz dziennie w nocy (cron job). Jeśli raz w tygodniu - wystarczy manualna aktualizacja. Większość baz wektorowych pozwala na inkrementalne dodawanie (nie musisz przetwarzać wszystkiego od nowa, tylko nowe/zmienione pliki). Pinecone i Weaviate mają API do usuwania starych chunków i dodawania nowych.
Nie do końca. RAG daje modelowi DOSTĘP do informacji, nie zmienia jego "sposobu myślenia". Fine-tuning zmienia wagi modelu - uczy go nowego stylu, formatu odpowiedzi, specjalistycznej wiedzy. Jeśli potrzebujesz, żeby model odpowiadał w konkretnym tonie (np. formalnym języku prawniczym) - fine-tuning. Jeśli potrzebujesz, żeby znał Twoje dokumenty - RAG. Często najlepsze rozwiązanie to połączenie: fine-tuning na styl + RAG na treść.
Ten poradnik to dopiero początek. W naszym kursie "Praktyczna AI" nauczysz się korzystać z ChatGPT, Claude i innych narzędzi AI w sposób systematyczny - od zera do zaawansowanego poziomu.
Sprawdź kurs →RAG to nie teoria - to narzędzie, które możesz uruchomić dziś. Jeśli masz 10-20 dokumentów, z których często korzystasz (procedury, umowy, raporty), spróbuj zbudować prosty system według kroków z tego artykułu.
Zacznij od ChromaDB lokalnie - zero konfiguracji, zero kosztów. Wrzuć 5 dokumentów. Zadaj 10 pytań. Zobacz, jak system radzi sobie z różnymi sformułowaniami. Jak zobaczysz, że to działa - przejdź na Pinecone i GPT-5.
Jedna konkretna akcja na dziś: zainstaluj LangChain i ChromaDB (pip install langchain chromadb), stwórz folder "documents", wrzuć tam 3 PDF-y i uruchom pierwszy skrypt embeddingowy. Zajmie Ci to 15 minut. Za tydzień będziesz mógł zapytać swoje dokumenty o cokolwiek.
Na podstawie: SukcesAI Tutorial Generator
Podoba Ci się ten artykuł?
Co piątek wysyłam podsumowanie najlepszych artykułów tygodnia. Zapisz się!
10 gotowych promptów do codziennej pracy + 5 narzędzi + plan na pierwszy tydzień. PDF, 4 strony konkretu.
90 minut praktycznej wiedzy o AI. Pokaze Ci krok po kroku, jak zaczac oszczedzac 10 godzin tygodniowo dzieki sztucznej inteligencji.
Zapisz sie na webinarReprezentujesz firme? Zobacz wdrozenia AI dla firm →

Podział dokumentów na fragmenty to fundament skutecznego RAG. Dowiedz się, jak to zrobić praktycznie - od wyboru strategii po testowanie wyników.

RAG łączy moc dużych modeli językowych z aktualną wiedzą z Twoich dokumentów. Sprawdź, jak to działa i jak to zastosować w praktyce.

Chcesz zbudować własną aplikację AI, ale programowanie Cię przeraża? Gradio Blocks pozwala tworzyć interaktywne interfejsy bez znajomości kodu. Sprawdź, jak zacząć w 10 minut.

Fast tokenizery mogą przyspieszyć pipeline RAG nawet 10-krotnie. Sprawdź, jak działają, kiedy mają sens i jak je wdrożyć krok po kroku.

Statystyka i prawdopodobieństwo to fundament AI. Wyjaśniamy kluczowe pojęcia prostym językiem - bez matematycznego żargonu, z praktycznymi przykładami.

Zamień notatki w gotowy podcast w 30 minut. Konkretne narzędzia (NotebookLM, Descript, ElevenLabs), przepływ pracy krok po kroku i przykłady dla początkujących.
