Poradniki
·
10 min czytania
·
12 czerwca 2026
Jak podzielić i przeanalizować dane do RAG - przewodnik krok po kroku

Źródło: Link
Źródło: Link
Masz setki stron dokumentacji, raportów lub notatek. Chcesz, żeby AI mogło na ich podstawie odpowiadać na pytania - ale kiedy wrzucasz wszystko naraz, model się gubi albo zwraca ogólniki. Problem nie leży w AI. Leży w tym, jak przygotowujesz dane.
Podział dokumentów na mniejsze fragmenty (chunking) i ich analiza to fundament każdego systemu RAG (Retrieval-Augmented Generation). Bez tego AI nie wie, gdzie szukać odpowiedzi. Z tym - działa jak dobrze zindeksowana biblioteka.
Ten przewodnik pokaże Ci, jak podzielić i przeanalizować dane do RAG - konkretnie, z kodem i przykładami.
Żeby przejść przez ten poradnik, potrzebujesz:
Jeśli nie masz jeszcze dokumentów - zacznij od prostego pliku tekstowego z kilkoma akapitami. Możesz potem przeskalować.
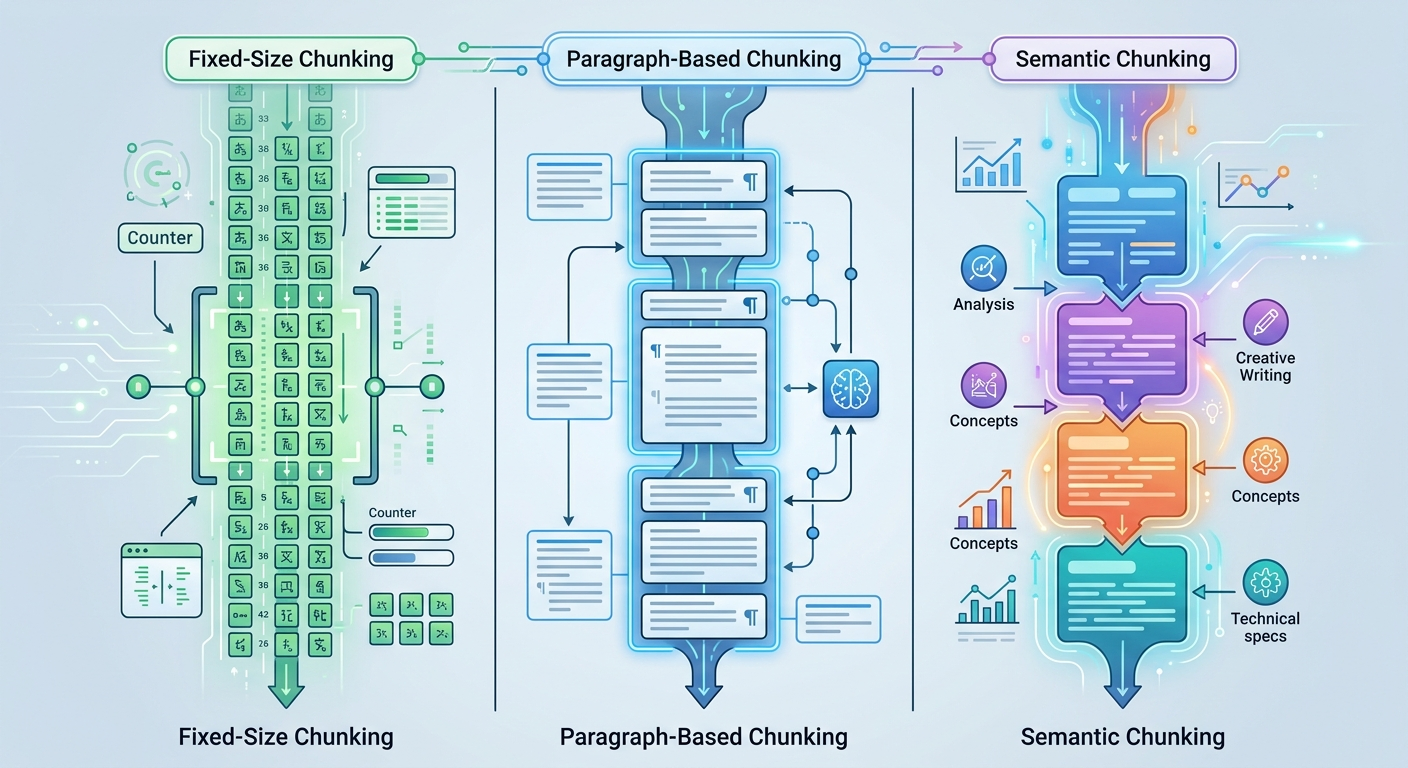
Nie ma jednej uniwersalnej metody chunking. To zależy od typu dokumentów i tego, jak będziesz ich używać. Oto trzy najczęstsze strategie:
Najprostsza metoda. Dzielisz tekst co X znaków (np. 500-1000), z nakładaniem się fragmentów (overlap) o 10-20%.
Kiedy używać: dokumenty bez wyraźnej struktury (np. transkrypcje, surowe notatki).
Wada: może rozciąć zdanie w połowie albo rozdzielić kontekst.
Dzielisz tekst według naturalnych granic - podwójne entery, nagłówki, punktory.
Kiedy używać: dokumenty ze strukturą (artykuły, raporty, dokumentacja techniczna).
Wada: jeśli akapity są bardzo długie (np. 3000 znaków), model może mieć problem z przetworzeniem.
Algorytm analizuje treść i dzieli tekst tam, gdzie zmienia się temat. Wymaga więcej mocy obliczeniowej, ale daje najlepsze wyniki.
Kiedy używać: złożone dokumenty, gdzie kontekst jest kluczowy (np. umowy prawne, badania naukowe).
Wada: wolniejsze i droższe (jeśli używasz płatnego API do analizy).
Moja rekomendacja: zacznij od podziału na akapity z limitem 800-1000 znaków. Jeśli wyniki będą słabe - przejdź na semantyczny.
Otwierasz terminal i instalujesz bibliotekę. Użyjemy LangChain - ma prosty interfejs i działa z większością modeli.
pip install langchain langchain-community pypdf
Teraz tworzysz prosty skrypt Python. Zapisz go jako chunk_documents.py:
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.document_loaders import PyPDFLoader
# Wczytujesz dokument
loader = PyPDFLoader("twoj_dokument.pdf")
documents = loader.load()
# Dzielisz na fragmenty
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=1000, # max znaków w fragmencie
chunk_overlap=200, # nakładanie się fragmentów
length_function=len,
)
chunks = text_splitter.split_documents(documents)
# Wyświetlasz wynik
print(f"Podzielono na {len(chunks)} fragmentów")
print("\nPierwszy fragment:")
print(chunks[0].page_content)
Uruchamiasz: python chunk_documents.py
Jeśli wszystko działa - zobaczysz liczbę fragmentów i podgląd pierwszego. Jeśli nie - sprawdź, czy ścieżka do pliku jest poprawna.
RecursiveCharacterTextSplitter to inteligentny dzielnik. Najpierw próbuje dzielić po paragrafach, potem po zdaniach, a dopiero na końcu - po znakach. Dzięki temu zachowuje kontekst lepiej niż prosty podział co X znaków.
Parametr chunk_overlap sprawia, że każdy fragment ma wspólny kawałek z poprzednim. To ważne - jeśli odpowiedź na pytanie znajduje się na granicy dwóch chunków, AI i tak ją znajdzie.
Teraz masz fragmenty tekstu. Ale AI nie rozumie tekstu - rozumie liczby. Dlatego każdy fragment musisz zamienić na wektor (embedding) - ciąg liczb, który reprezentuje znaczenie tekstu.
Instalujesz bibliotekę do embeddingów:
pip install sentence-transformers
Rozszerzasz skrypt:
from sentence_transformers import SentenceTransformer
import numpy as np
# Ładujesz model embeddingowy
model = SentenceTransformer('all-MiniLM-L6-v2') # open-source, działa lokalnie
# Generujesz embeddingi dla każdego fragmentu
embeddings = []
for chunk in chunks:
embedding = model.encode(chunk.page_content)
embeddings.append(embedding)
print(f"Wygenerowano {len(embeddings)} embeddingów")
print(f"Wymiar wektora: {len(embeddings[0])}")
Uruchamiasz ponownie. Teraz każdy fragment ma swój wektor - zazwyczaj 384 lub 768 liczb, które opisują jego znaczenie.
Dlaczego to działa? Model embeddingowy został wytrenowany na milionach tekstów. Nauczył się, że fragmenty o podobnym znaczeniu mają podobne wektory. Dzięki temu możesz później wyszukiwać fragmenty, które odpowiadają na pytanie - nawet jeśli nie zawierają dokładnie tych samych słów.
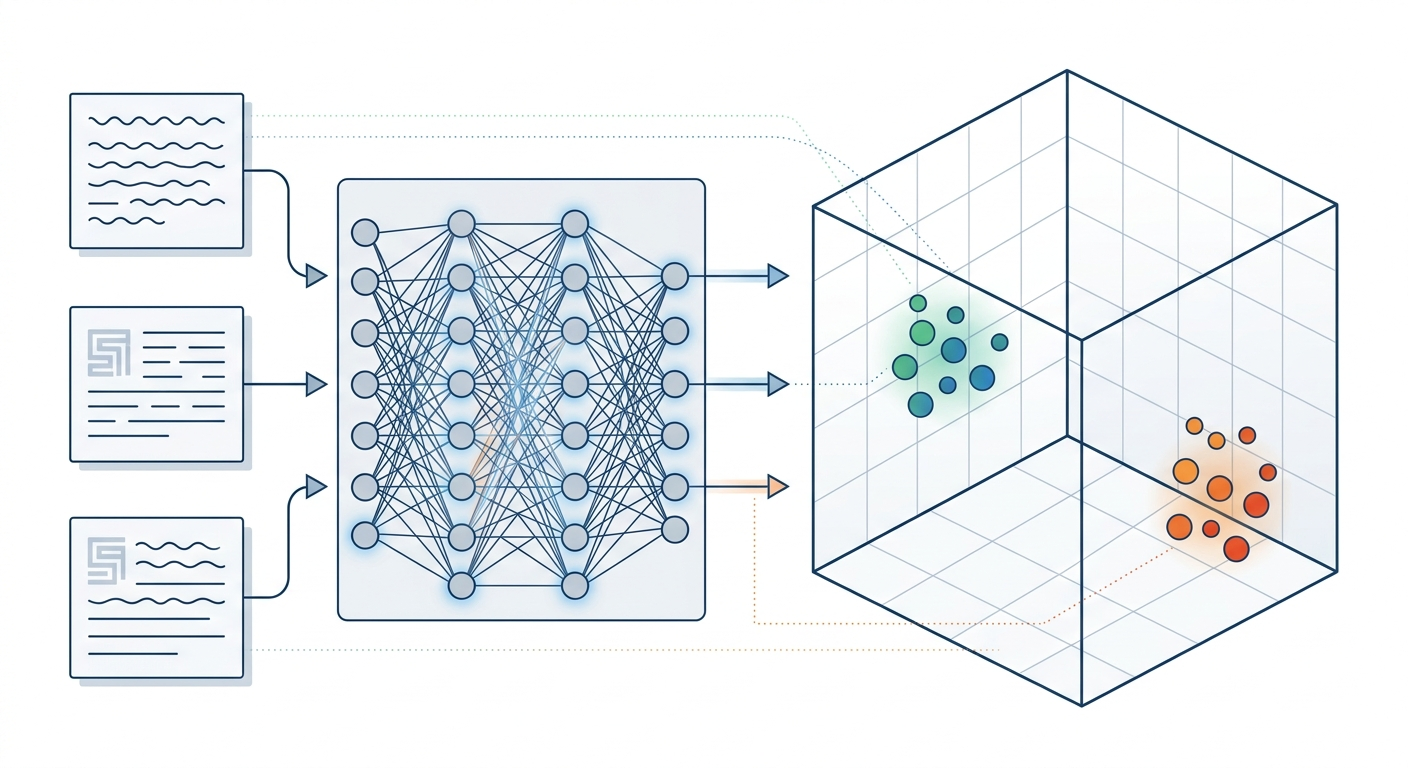
Masz fragmenty i embeddingi. Teraz musisz je gdzieś zapisać - tak, żeby później szybko wyszukać najbardziej pasujące do pytania.
Do tego służą bazy wektorowe. Najprostsze rozwiązanie na start: FAISS (biblioteka od Meta, działa lokalnie).
Instalujesz:
pip install faiss-cpu
Rozszerzasz skrypt:
import faiss
import pickle
# Konwertujesz embeddingi na format FAISS
embedding_matrix = np.array(embeddings).astype('float32')
# Tworzysz indeks FAISS
index = faiss.IndexFlatL2(embedding_matrix.shape[1]) # L2 = odległość euklidesowa
index.add(embedding_matrix)
# Zapisujesz indeks i fragmenty do plików
faiss.write_index(index, "faiss_index.bin")
with open("chunks.pkl", "wb") as f:
pickle.dump([chunk.page_content for chunk in chunks], f)
print("Zapisano indeks i fragmenty")
Uruchamiasz. Teraz masz dwa pliki: faiss_index.bin (embeddingi) i chunks.pkl (oryginalne teksty).
Kiedy ktoś zada pytanie, wygenerujesz embedding tego pytania, wyszukasz najbliższe wektory w FAISS (zajmuje milisekundy, nawet dla milionów fragmentów), a potem wyciągniesz odpowiadające im teksty z chunks.pkl. Te teksty trafią do modelu AI jako kontekst.
Jeśli planujesz skalować (tysiące dokumentów, wielu użytkowników) - rozważ Pinecone, Weaviate lub Qdrant. Na start FAISS wystarczy.
Czas sprawdzić, czy to działa. Tworzysz nowy skrypt search.py:
import faiss
import pickle
from sentence_transformers import SentenceTransformer
# Ładujesz model, indeks i fragmenty
model = SentenceTransformer('all-MiniLM-L6-v2')
index = faiss.read_index("faiss_index.bin")
with open("chunks.pkl", "rb") as f:
chunks = pickle.load(f)
# Wpisujesz pytanie
query = "Jak skonfigurować API?"
query_embedding = model.encode([query]).astype('float32')
# Wyszukujesz 3 najbardziej pasujące fragmenty
k = 3
distances, indices = index.search(query_embedding, k)
print(f"Pytanie: {query}\n")
for i, idx in enumerate(indices[0]):
print(f"Fragment {i+1} (odległość: {distances[0][i]:.2f}):")
print(chunks[idx])
print("---")
Uruchamiasz: python search.py
Jeśli wszystko działa - zobaczysz 3 fragmenty, które najbardziej pasują do pytania. Odległość (distance) mówi, jak daleko wektor pytania jest od wektora fragmentu - im mniejsza, tym lepiej.
Co zrobić, jeśli wyniki są słabe?
chunk_size - może fragmenty są za długie i zawierają za dużo różnych tematów.chunk_overlap - może odpowiedź znajduje się na granicy dwóch chunków.all-mpnet-base-v2 (wolniejszy, ale dokładniejszy).
Masz działające wyszukiwanie. Teraz możesz podłączyć je do modelu AI - np. GPT-5, Claude Sonnet 4.6 lub DeepSeek V4-Pro.
Prosty przykład z OpenAI API:
import openai
openai.api_key = "twoj-klucz-api"
# Wyszukujesz fragmenty (jak wcześniej)
query = "Jak skonfigurować API?"
query_embedding = model.encode([query]).astype('float32')
k = 3
distances, indices = index.search(query_embedding, k)
# Łączysz fragmenty w kontekst
context = "\n\n".join([chunks[idx] for idx in indices[0]])
# Wysyłasz do AI
response = openai.ChatCompletion.create(
model="gpt-4o",
messages=[
{"role": "system", "content": "Odpowiadasz na pytania na podstawie podanego kontekstu."},
{"role": "user", "content": f"Kontekst:\n{context}\n\nPytanie: {query}"}
]
)
print(response['choices'][0]['message']['content'])
Uruchamiasz. AI dostaje tylko te fragmenty, które są istotne dla pytania - nie cały dokument. Dzięki temu odpowiedź jest szybsza, tańsza i dokładniejsza.
Jeśli używasz innego modelu (Claude Opus 4.7, Gemini 3.1 Pro, DeepSeek V4-Pro) - zmień tylko wywołanie API. Logika wyszukiwania pozostaje taka sama.
System działa. To nie koniec. RAG to proces iteracyjny - musisz obserwować, jak radzi sobie w praktyce, i dostosowywać parametry.
Zbierasz przykładowe pytania od użytkowników. Dla każdego pytania sprawdzasz, czy wyszukane fragmenty zawierają odpowiedź. Jeśli nie - eksperymentujesz z parametrami:
chunk_size z 1000 na 800 lub 1200.chunk_overlap z 200 na 100 lub 300.Nie ma jednego idealnego ustawienia. To zależy od Twoich dokumentów i pytań. Dlatego testowanie jest kluczowe.
Jeśli chcesz zgłębić temat RAG i embeddingów - zerknij na przewodnik po tworzeniu zbiorów danych do AI i jak kodować z Claude Code w terminalu.
Najprawdopodobniej fragmenty są za długie i zawierają za dużo różnych informacji. Zmniejsz chunk_size do 500-700 znaków i przetestuj ponownie.
Model embeddingowy może być za słaby. Spróbuj all-mpnet-base-v2 zamiast all-MiniLM-L6-v2. Albo użyj płatnego API - np. OpenAI Embeddings (text-embedding-3-large) albo Cohere Embed v3.
Jeśli masz tysiące dokumentów, FAISS może nie wystarczyć. Przejdź na Pinecone (zarządzana baza wektorowa w chmurze) albo Qdrant (self-hosted, ale szybszy niż FAISS). Albo zmniejsz liczbę fragmentów do przeszukania (k).
Może chunk_overlap jest za mały i kontekst się urywa. Zwiększ do 20-30% rozmiaru fragmentu. Albo użyj podziału semantycznego zamiast na stałą liczbę znaków.
Jeśli używasz płatnego API do embeddingów - przejdź na open-source (Sentence-Transformers działa lokalnie, zero kosztów). Jeśli używasz drogiego modelu AI (np. Claude Opus 4.7) - przejdź na tańszy wariant (Haiku 4.5 albo DeepSeek V4-Flash).
Tak, istnieją narzędzia no-code do budowy systemów RAG - np. Flowise, LangFlow czy Bubble z integracją Pinecone. Mają ograniczenia - nie dostosowujesz parametrów chunking, nie kontrolujesz kosztów, nie debugujesz błędów. Jeśli chcesz czegoś więcej niż demo - musisz zakodować.
Zależy od narzędzi. FAISS radzi sobie z milionami fragmentów, ale działa w pamięci RAM - jeśli masz 10GB embeddingów, potrzebujesz 10GB RAM. Pinecone i Qdrant skalują się lepiej (przechowują dane na dysku). Jeśli masz setki tysięcy stron - rozważ przetwarzanie wsadowe i dedykowaną bazę wektorową.
Tak, ale musisz użyć modelu embeddingowego, który obsługuje polski. all-MiniLM-L6-v2 działa, ale nie jest idealny. Lepsze opcje: paraphrase-multilingual-MiniLM-L12-v2 (open-source) albo Cohere Embed v3 (płatne API, ale wspiera 100+ języków, w tym polski).
Tak, RAG działa z każdym modelem AI, który przyjmuje tekst jako kontekst. GPT-5, Claude Opus 4.7, Gemini 3.1 Pro, DeepSeek V4-Pro - wszystkie obsługują długie konteksty (128k-1M tokenów). Różnica jest w cenie i jakości - Claude lepiej radzi sobie z długimi dokumentami, GPT-5 jest szybszy, DeepSeek tańszy.
Zależy, jak często zmieniają się dokumenty. Jeśli dokumentacja jest statyczna - raz na miesiąc wystarczy. Jeśli dodajesz nowe treści codziennie - potrzebujesz systemu, który automatycznie przetwarza nowe pliki i dodaje je do indeksu. Możesz to zautomatyzować przez cron job albo webhook.
Ten poradnik to dopiero początek. W naszym kursie "Praktyczna AI" nauczysz się korzystać z ChatGPT, Claude i innych narzędzi AI w sposób systematyczny - od zera do zaawansowanego poziomu.
Sprawdź kurs →Podział i analiza danych to fundament każdego systemu RAG. Bez tego AI nie wie, gdzie szukać odpowiedzi. Z tym - działa jak dobrze zindeksowana biblioteka.
Kluczowe kroki:
Nie ma jednego idealnego ustawienia. Musisz testować i optymalizować pod swoje dane. Podstawy masz już teraz.
Otwórz terminal. Zainstaluj LangChain i Sentence-Transformers. Weź jeden dokument - raport, artykuł, dokumentację - i podziel go na fragmenty. Wyświetl pierwszy fragment. To zajmie 10 minut. I będziesz miał działający prototyp RAG.
Reszta to iteracja.
Na podstawie: SukcesAI Course Material
10 gotowych promptów do codziennej pracy + 5 narzędzi + plan na pierwszy tydzień. PDF, 4 strony konkretu.

RAG łączy modele AI z zewnętrznymi dokumentami. Dowiedz się, jak działa retrieval augmented generation, embeddingi i bazy wektorowe - krok po kroku.

Kompletna instrukcja konfiguracji Gemini w języku polskim, porównanie jakości odpowiedzi PL vs EN i sprawdzone praktyki promptowania dla polskich użytkowników.

RAG łączy moc dużych modeli językowych z aktualną wiedzą z Twoich dokumentów. Sprawdź, jak to działa i jak to zastosować w praktyce.

Chcesz zbudować własną aplikację AI, ale programowanie Cię przeraża? Gradio Blocks pozwala tworzyć interaktywne interfejsy bez znajomości kodu. Sprawdź, jak zacząć w 10 minut.

Od pomysłu po sprzedaż: zobacz, jak wykorzystać AI do planowania kursu online, tworzenia treści, nagrywania i marketingu bez chaosu i zgadywania.

BPE to algorytm, który uczy modele AI czytać tekst. Bez niego GPT-5 czy Claude nie rozumieliby ani słowa. Oto jak to działa - bez matematyki.
