Poradniki
·
8 min czytania
·
10 maja 2026
Jak działa Stable Diffusion - przewodnik po generowaniu obrazów AI

Źródło: Link
Źródło: Link
118 lekcji bez kodowania. ChatGPT, Claude, Gemini, automatyzacje. Notatnik AI i AI Coach w cenie.
Wpisujesz "kot w kosmosie" i dostajesz obraz kota w kosmosie. Magia? Nie. Stable Diffusion to system kilku współpracujących modeli, z których każdy ma swoją rolę. Nie musisz znać architektury, żeby z niego korzystać - ale zrozumienie podstaw zmienia sposób, w jaki tworzysz prompty.
Jay Alammar - znany z wizualizacji transformerów i BERT-a - stworzył przewodnik, który rozkłada Stable Diffusion na czynniki pierwsze. Bez matematyki, za to z diagramami pokazującymi, co się dzieje pod maską. Jeśli kiedykolwiek zastanawiałeś się, dlaczego jeden prompt działa, a drugi nie - ta wiedza da Ci przewagę.
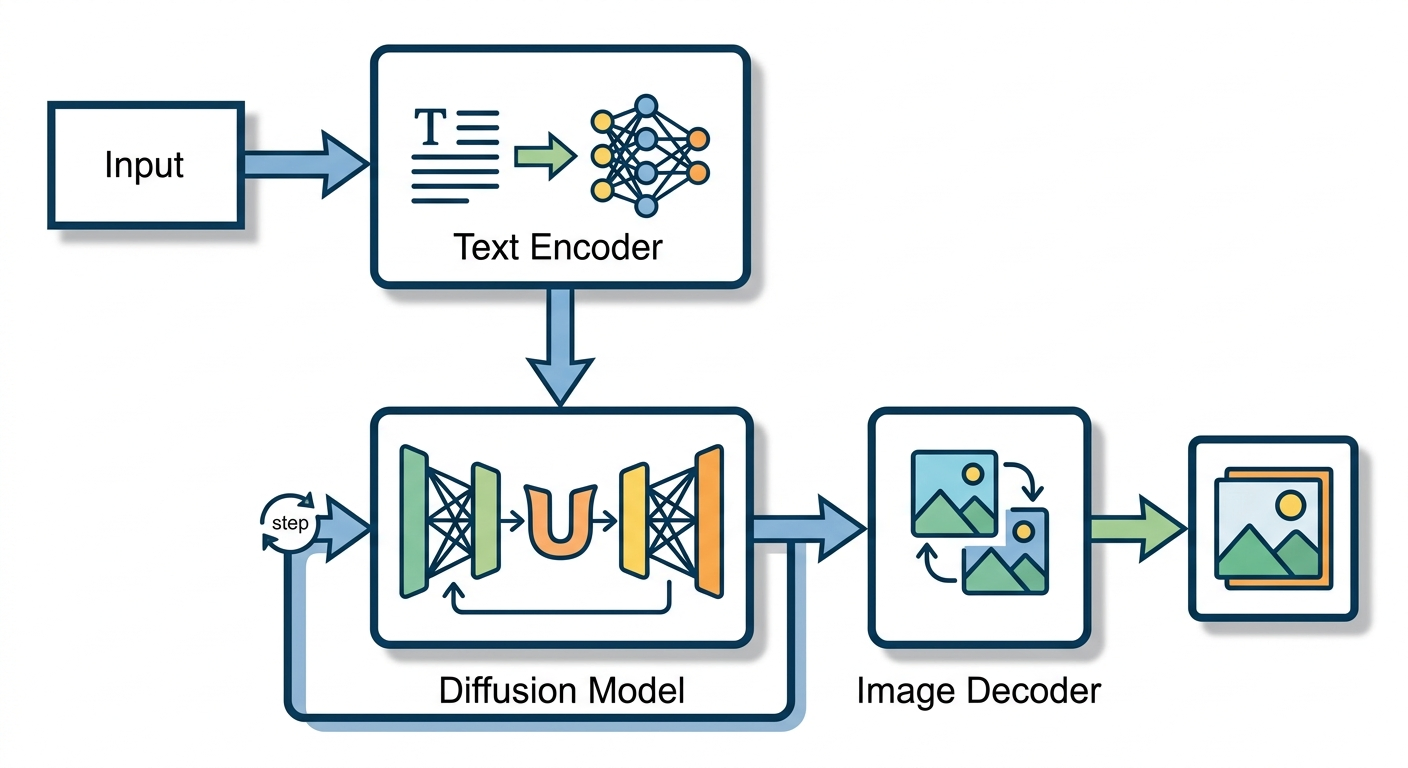
Stable Diffusion to nie jeden model - to system składający się z kilku komponentów, które współpracują jak dobrze zgrany zespół. Każdy ma konkretne zadanie, a razem zamieniają tekst w obraz.
Pierwsza obserwacja: jest tam komponent, który rozumie tekst. Zamienia słowa w reprezentację numeryczną - coś, co model może przetworzyć. To nie jest zwykłe tłumaczenie słów na liczby. Ten komponent wychwytuje idee zawarte w tekście, kontekst, relacje między pojęciami.
Dlaczego to ważne? Jeśli wpiszesz "czerwony samochód na tle gór", system musi zrozumieć nie tylko poszczególne słowa, ale także ich wzajemne relacje - że samochód ma być czerwony, że ma stać przed górami, nie na nich. To właśnie robi komponent tekstowy.
Stable Diffusion składa się z trzech głównych części:
Każdy z tych elementów to osobny, wytrenowany model. Razem tworzą pipeline, który prowadzi od tekstu do obrazu. Cały proces? Kilka sekund.

Zacznijmy od tego, co się dzieje, gdy klikasz "generuj". Twój prompt - powiedzmy "kot w kosmosie" - trafia do enkodera tekstowego. Ten zamienia go w wektor liczb, który koduje znaczenie całej frazy.
Następnie model dyfuzyjny zaczyna pracę. Nie od razu tworzy obraz. Zamiast tego pracuje w przestrzeni latentnej - uproszczonej reprezentacji, gdzie obliczenia są szybsze i tańsze. To jak szkicowanie na kartce przed namalowaniem finalnego obrazu.
Model dyfuzyjny działa w dwóch fazach. Najpierw uczy się, jak dodawać szum do obrazów - jak zamieniać wyraźne zdjęcie w statyczny szum. Potem uczy się procesu odwrotnego: jak z szumu odtworzyć obraz.
Kiedy generujesz obraz, model zaczyna od czystego szumu i stopniowo go "oczyszcza", kierując się Twoim promptem. Każdy krok usuwa trochę szumu, dodając szczegóły zgodne z opisem. Po kilkudziesięciu iteracjach masz gotowy obraz.
Dlaczego to działa? Model nauczył się rozpoznawać wzorce w danych treningowych - milionach par tekst-obraz. Wie, jak wygląda "kot", jak wygląda "kosmos", i jak je połączyć w spójną całość.
Kiedy model dyfuzyjny skończy pracę, masz reprezentację obrazu w przestrzeni latentnej. To wciąż nie jest obraz, który możesz zobaczyć. Tu wkracza dekoder - model, który zamienia tę reprezentację w pełnowymiarowy obraz RGB.
Dekoder dodaje szczegóły, tekstury, kolory. Zwiększa rozdzielczość z uproszczonej reprezentacji do finalnego obrazu - często 512×512 pikseli lub więcej. To ostatni krok w pipeline'ie.

Możesz korzystać ze Stable Diffusion bez znajomości architektury. Zrozumienie, jak działa, zmienia jednak sposób, w jaki piszesz prompty.
Przykład: wiesz już, że enkoder tekstowy przetwarza relacje między słowami. Więc prompt "czerwony samochód" to nie to samo co "samochód czerwony". Model zwraca uwagę na kolejność, kontekst, strukturę zdania. Im precyzyjniej opiszesz, czego chcesz, tym lepsze wyniki.
Wiesz też, że model pracuje w przestrzeni latentnej - uproszczonej reprezentacji. Dlatego niektóre szczegóły mogą być niedokładne (np. liczba palców u postaci). Model nie "widzi" pikseli w trakcie generowania - operuje na abstrakcyjnej reprezentacji.
Stable Diffusion daje Ci kontrolę nad kilkoma parametrami:
Rozumiejąc, jak działa dyfuzja, wiesz, że zwiększenie kroków z 20 do 50 da Ci bardziej wyrafinowany obraz. Zwiększenie do 200 niekoniecznie coś zmieni - model osiąga plateau jakości.
Podobnie z CFG scale: wartość 7-10 daje równowagę między kreatywnością a wiernością promptowi. Wartość 20 sprawi, że obraz będzie dosłowny, może jednak stracić naturalność.
Jeśli chcesz zobaczyć to w praktyce, nie musisz instalować niczego lokalnie. Narzędzia jak Stable Diffusion w przeglądarce pozwalają testować różne prompty i parametry bez konfiguracji.
Zacznij od prostego opisu - np. "górski krajobraz o zachodzie słońca". Wygeneruj obraz z domyślnymi ustawieniami. Zapisz wynik.
Teraz wpisz "zachód słońca nad górskim krajobrazem". Wygeneruj ponownie. Zauważysz różnicę - enkoder tekstowy interpretuje kolejność jako wskazówkę, co jest ważniejsze.
Zwiększ liczbę kroków do 50. Zmień CFG scale na 10. Zobacz, jak zmienia się jakość i styl obrazu. Użyj tego samego seed, żeby porównać wyniki przy różnych ustawieniach.
Po kilku próbach zobaczysz wzorce - które ustawienia dają Ci kontrolę, a które wprowadzają chaos. To wiedza, której nie dostaniesz z tutoriali - tylko z praktyki.
Tak, możesz uruchomić Stable Diffusion lokalnie na swoim komputerze. Wymaga to karty graficznej z przynajmniej 6 GB VRAM (najlepiej NVIDIA). Istnieją instalacje typu "jeden klik" dla Windows i macOS, które ułatwiają start.
Model pracuje w przestrzeni latentnej - uproszczonej reprezentacji obrazu. Nie "widzi" pikseli w trakcie generowania, tylko abstrakcyjne cechy. Dlatego szczegóły anatomiczne mogą być niedokładne. Nowsze wersje (SDXL, SD 3) poprawiają to, problem nie zniknął jednak całkowicie.
Na nowoczesnej karcie graficznej (np. RTX 4070) - około 5-10 sekund dla obrazu 512×512 przy 30 krokach dyfuzji. Na CPU - kilka minut. W chmurze (np. Google Colab z GPU) - 10-20 sekund. Im wyższa rozdzielczość i więcej kroków, tym dłużej.
Zależy od licencji modelu, którego używasz. Stable Diffusion (wersja open-source) ma licencję CreativeML Open RAIL-M, która pozwala na użytek komercyjny, zabrania jednak tworzenia treści nielegalnych lub szkodliwych. Sprawdź zawsze konkretną licencję wersji, z której korzystasz.
Trzy rzeczy mają największy wpływ: (1) precyzyjny prompt z detalami stylu, oświetlenia, kompozycji, (2) odpowiedni CFG scale (7-12 dla równowagi między kreatywnością a wiernością), (3) wystarczająca liczba kroków dyfuzji (30-50 dla większości przypadków). Możesz też użyć fine-tuningu modelu na własnych danych, jeśli potrzebujesz specyficznego stylu.
Ten poradnik to dopiero początek. W naszym kursie "Praktyczna AI" nauczysz się korzystać z ChatGPT, Claude i innych narzędzi AI w sposób systematyczny - od zera do zaawansowanego poziomu.
Sprawdź kurs →Stable Diffusion to punkt wyjścia, nie koniec drogi. Rozumiejąc, jak działa enkoder tekstowy, model dyfuzyjny i dekoder, masz fundament do eksperymentowania z innymi narzędziami - DALL-E, Midjourney, czy nowszymi modelami dyfuzyjnymi.
Wiedza o tym, że model pracuje w przestrzeni latentnej, tłumaczy, dlaczego niektóre szczegóły są niedokładne. Zrozumienie parametrów (kroki, CFG scale, seed) daje Ci kontrolę nad wynikami. A znajomość architektury pozwala przewidzieć, które prompty zadziałają, a które nie.
Jeśli chcesz zgłębić temat wizualnie, materiał Jay'a Alammara to najlepszy start - diagramy pokazują przepływ danych przez system bez matematyki. A jeśli chcesz praktyki - otwierasz narzędzie i zaczynasz testować.
Wejdź na Hugging Face Spaces, znajdź Stable Diffusion demo, wpisz prosty prompt i zmień CFG scale z 7 na 15. Zobacz różnicę. To Ci pokaże, jak parametry wpływają na wynik - bez instalacji, bez konfiguracji.
Na podstawie: The Illustrated Stable Diffusion - Jay Alammar
Przeczytaj też:
Podoba Ci się ten artykuł?
Co piątek wysyłam podsumowanie najlepszych artykułów tygodnia. Zapisz się!
10 gotowych promptów do codziennej pracy + 5 narzędzi + plan na pierwszy tydzień. PDF, 4 strony konkretu.
90 minut praktycznej wiedzy o AI. Pokaze Ci krok po kroku, jak zaczac oszczedzac 10 godzin tygodniowo dzieki sztucznej inteligencji.
Zapisz sie na webinarReprezentujesz firme? Zobacz wdrozenia AI dla firm →

Nie każdy generator obrazów AI pasuje do tego samego zadania. Zobacz, czym różnią się Midjourney, DALL-E i Stable Diffusion oraz jak wybrać narzędzie bez zgadywania.

Struktura promptu, dobór stylu, parametry techniczne i negatywne prompty - wszystko, czego potrzebujesz, by AI narysowało dokładnie to, co masz w głowie.

Retrieval Augmented Generation to technologia, która pozwala AI korzystać z Twoich dokumentów. Embeddingi, bazy wektorowe i wyszukiwanie semantyczne - wyjaśnione bez żargonu.

Statystyka i prawdopodobieństwo to fundament AI. Wyjaśniamy kluczowe pojęcia prostym językiem - bez matematycznego żargonu, z praktycznymi przykładami.

Zamień notatki w gotowy podcast w 30 minut. Konkretne narzędzia (NotebookLM, Descript, ElevenLabs), przepływ pracy krok po kroku i przykłady dla początkujących.

Kompletna instrukcja konfiguracji Gemini w języku polskim, porównanie jakości odpowiedzi PL vs EN i sprawdzone praktyki promptowania dla polskich użytkowników.
