Poradniki
·
11 min czytania
·
2 maja 2026
Jak zrobić fine-tuning modelu AI - przewodnik krok po kroku

Źródło: Link
Źródło: Link
118 lekcji bez kodowania. ChatGPT, Claude, Gemini, automatyzacje. Notatnik AI i AI Coach w cenie.
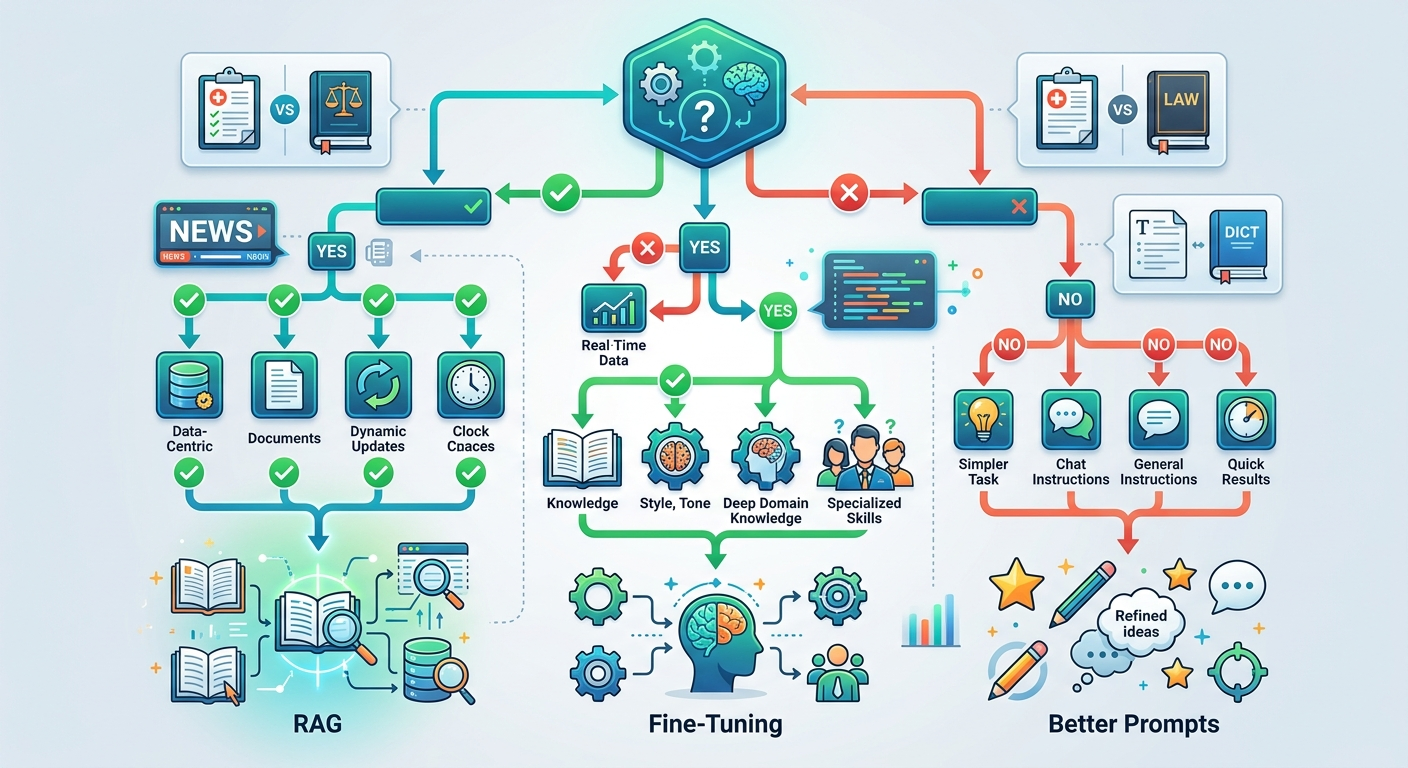
Szef przychodzi do Ciebie z pomysłem: "Nauczmy ChatGPT naszego stylu pisania, żeby generował treści dokładnie tak, jak my". Brzmi sensownie. Pytanie: czy na pewno potrzebujesz fine-tuningu? A może wystarczy lepszy prompt lub RAG?
Ten poradnik pokaże Ci, kiedy fine-tuning ma sens, ile kosztuje, jakie dane potrzebujesz i jak go przeprowadzić krok po kroku przez OpenAI API. Poziom: zaawansowany, ale wyjaśniony tak, żebyś nie musiał być inżynierem ML.
Fine-tuning to proces dostosowania gotowego modelu AI do Twojego konkretnego przypadku użycia. Zamiast uczyć model od zera (co kosztowałoby miliony dolarów), bierzesz GPT-4o, Claude lub inny model i "douczasz" go na Twoich danych.
Wymagania techniczne:
Czego NIE potrzebujesz: wiedzy o architekturach neuronowych, Pythona (możesz użyć interfejsu webowego), tysięcy przykładów treningowych.

Powiedzmy to wprost: w 80% przypadków nie potrzebujesz fine-tuningu. Serio. Firmy przepalają budżety na fine-tuning, gdy wystarczyłby lepszy prompt lub RAG (Retrieval-Augmented Generation).
Jeśli chcesz, żeby model znał Twoje dane firmowe - użyj RAG. To system, który wyszukuje odpowiednie fragmenty z Twojej bazy wiedzy i podaje je modelowi w prompcie. Tańsze, szybsze, łatwiejsze do aktualizacji. Więcej o wdrażaniu AI w produkcji znajdziesz tutaj.
Jeśli chcesz zmienić ton odpowiedzi - użyj system promptu. "Odpowiadaj zawsze w stylu formalnym, używając terminologii medycznej" działa w 90% przypadków.
Jeśli masz mniej niż 50 przykładów - fine-tuning nie będzie skuteczny. Model potrzebuje wzorców, nie pojedynczych przypadków.
1. Konsystentny format wyjściowy
Potrzebujesz, żeby model ZAWSZE zwracał dane w konkretnej strukturze JSON? Fine-tuning nauczy go tego lepiej niż prompt (który czasem model ignoruje).
2. Specjalistyczna terminologia i styl
Piszesz dokumentację prawną, raporty medyczne lub analizy finansowe w bardzo specyficznym stylu? Model po fine-tuningu będzie go naśladował bez 500-słownego promptu.
3. Redukcja kosztów przy dużej skali
Jeśli wysyłasz 100,000+ requestów miesięcznie z długimi promptami (3000+ tokenów), fine-tuning może być tańszy. Krótszy prompt = mniej tokenów input = niższe koszty.
4. Zadania wymagające nauki wzorców
Klasyfikacja tekstu według Twojej własnej taksonomii, ekstrakcja encji specyficznych dla Twojej branży, tłumaczenie z uwzględnieniem firmowego słownika - to przypadki, gdzie fine-tuning błyszczy.
OpenAI rozlicza fine-tuning w dwóch etapach: trening i używanie modelu.
GPT-4o-mini: $0.80 za 1M tokenów treningowych
Przykład: 100 przykładów po ~500 tokenów = 50,000 tokenów = $0.04
GPT-4o: $25.00 za 1M tokenów treningowych
Ten sam zestaw danych = $1.25
GPT-4 Turbo: Nie jest już dostępny do fine-tuningu (OpenAI przeniósł focus na GPT-4o).
Fine-tunowany model kosztuje więcej niż bazowy:
GPT-4o-mini fine-tuned:
Input: $0.30 za 1M tokenów (vs $0.15 dla bazowego)
Output: $1.20 za 1M tokenów (vs $0.60 dla bazowego)
GPT-4o fine-tuned:
Input: $3.75 za 1M tokenów (vs $2.50 dla bazowego)
Output: $15.00 za 1M tokenów (vs $10.00 dla bazowego)
Przykład kalkulacji:
Aplikacja generuje 10,000 odpowiedzi miesięcznie, każda ~300 tokenów output (prompt 100 tokenów).
Koszt bazowy GPT-4o-mini: (10k × 100 × $0.15/1M) + (10k × 300 × $0.60/1M) = $0.15 + $1.80 = $1.95/miesiąc
Koszt fine-tuned: (10k × 100 × $0.30/1M) + (10k × 300 × $1.20/1M) = $0.30 + $3.60 = $3.90/miesiąc
Różnica: $1.95 miesięcznie. Jeśli fine-tuning pozwoli Ci skrócić prompt z 500 do 50 tokenów, wyjdziesz na plus.
To najważniejsza część. Śmieci na wejściu = śmieci na wyjściu, tylko droższe.
Każda linia to osobny przykład w formacie JSON. OpenAI wymaga struktury:
{"messages": [{"role": "system", "content": "Jesteś asystentem prawnym specjalizującym się w RODO."}, {"role": "user", "content": "Czy mogę przechowywać dane klientów w Google Sheets?"}, {"role": "assistant", "content": "Nie, Google Sheets nie spełnia wymogów RODO dotyczących..."}]}
{"messages": [{"role": "system", "content": "Jesteś asystentem prawnym specjalizującym się w RODO."}, {"role": "user", "content": "Jak długo mogę przechowywać CV kandydatów?"}, {"role": "assistant", "content": "Maksymalnie przez okres rekrutacji plus..."}]}Minimum: 10 przykładów (OpenAI wymaga co najmniej 10)
Optymalne: 50-100 przykładów dla prostych zadań
Zaawansowane: 500+ przykładów dla złożonych zadań (klasyfikacja wieloklasowa, generowanie długich tekstów)
Jakość > ilość. 50 dobrych przykładów pokona 500 średnich.
1. Konsystencja
Jeśli w jednym przykładzie asystent odpowiada formalnie, a w drugim używa emoji - model się pogubi.
2. Różnorodność
Pokaż modelowi różne przypadki: krótkie pytania, długie, z kontekstem, bez kontekstu. Nie kopiuj tego samego wzorca 100 razy.
3. Prawdziwe dane
Najlepsze wyniki dają rzeczywiste konwersacje z Twoimi klientami/użytkownikami (oczywiście zanonimizowane). Syntetyczne przykłady "wymyślone na kolanie" są gorsze.
4. Walidacja
Sprawdź każdy przykład. Czy odpowiedź asystenta jest faktycznie poprawna i w stylu, którego oczekujesz? Model nauczy się dokładnie tego, co mu pokażesz - włącznie z błędami.
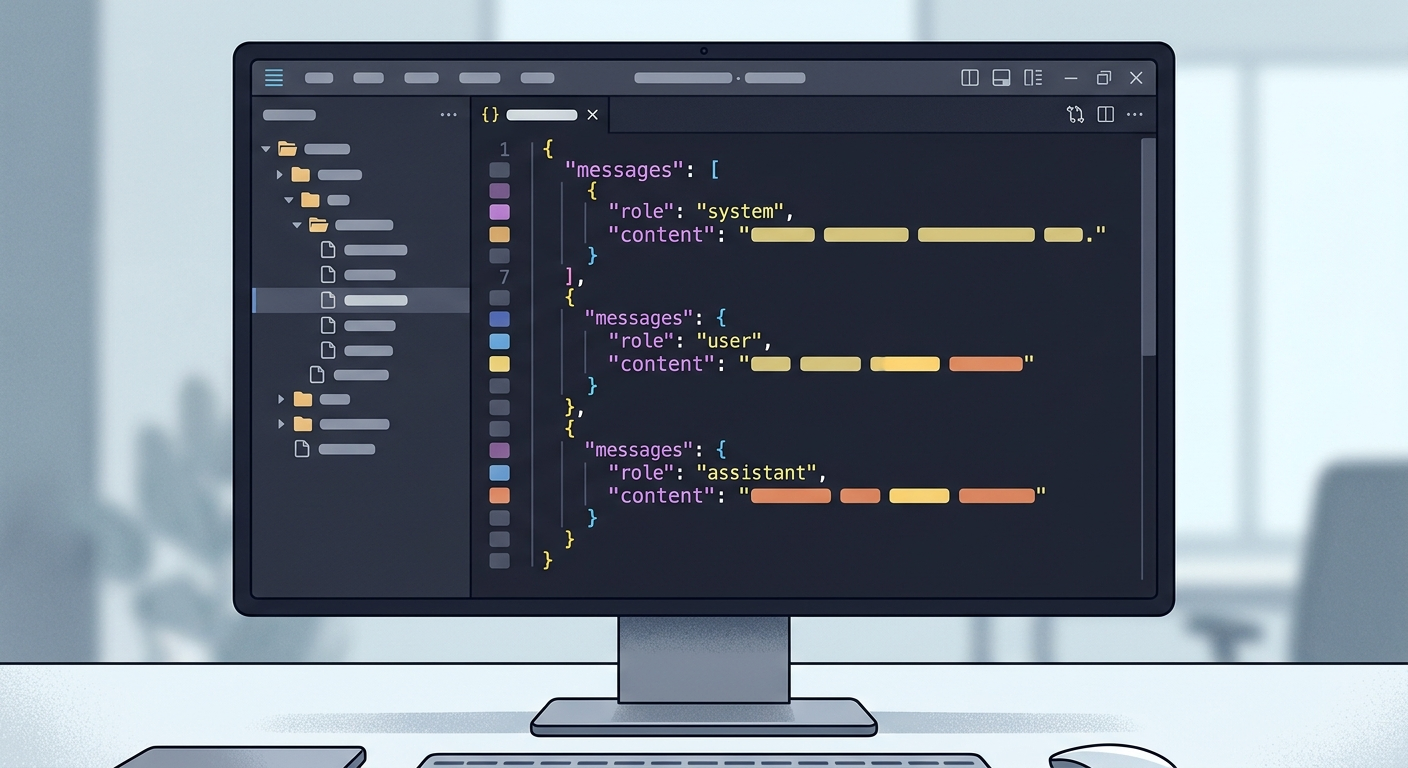
Zapisz swoje przykłady w pliku training_data.jsonl. Każda linia = jeden przykład, format jak wyżej.
Walidacja pliku:
OpenAI udostępnia narzędzie do sprawdzenia formatu. Zainstaluj bibliotekę:
pip install openaiNastępnie uruchom walidację:
openai tools fine_tunes.prepare_data -f training_data.jsonlNarzędzie pokaże błędy (jeśli są) i zasugeruje poprawki.
Przez API (wymagany klucz API z platform.openai.com):
curl https://api.openai.com/v1/files \
-H "Authorization: Bearer $OPENAI_API_KEY" \
-F purpose="fine-tune" \
-F file="@training_data.jsonl"Odpowiedź zwróci file-abc123 - to ID Twojego pliku. Zapisz je.
Alternatywa bez kodu: Wejdź na platform.openai.com/finetune, kliknij "Upload file", wybierz plik. Proste.
Przez API:
curl https://api.openai.com/v1/fine_tuning/jobs \
-H "Authorization: Bearer $OPENAI_API_KEY" \
-H "Content-Type: application/json" \
-d '{
"training_file": "file-abc123",
"model": "gpt-4o-mini-2024-07-18"
}'Możesz dodać parametry opcjonalne:"hyperparameters": {"n_epochs": 3} - liczba epok (domyślnie auto)"suffix": "moja-firma" - sufiks nazwy modelu (będzie ft:gpt-4o-mini:moja-firma:abc123)
Przez interfejs webowy: Na platform.openai.com/finetune kliknij "Create", wybierz plik, wybierz model bazowy, kliknij "Start".
Fine-tuning trwa od kilku minut (GPT-4o-mini, mały dataset) do kilku godzin (GPT-4o, duży dataset).
Sprawdzaj status:
curl https://api.openai.com/v1/fine_tuning/jobs/ftjob-abc123 \
-H "Authorization: Bearer $OPENAI_API_KEY"Albo po prostu odśwież stronę w Playground - status się zaktualizuje.
Gdy status zmieni się na succeeded, dostaniesz nazwę modelu, np. ft:gpt-4o-mini-2024-07-18:moja-firma:abc123.
Użyj dokładnie tak samo jak zwykłego modelu, tylko zmień nazwę:
curl https://api.openai.com/v1/chat/completions \
-H "Authorization: Bearer $OPENAI_API_KEY" \
-H "Content-Type: application/json" \
-d '{
"model": "ft:gpt-4o-mini-2024-07-18:moja-firma:abc123",
"messages": [{"role": "user", "content": "Testowe pytanie"}]
}'Testowanie w Playground: Wejdź na platform.openai.com/playground, w rozwijanym menu "Model" wybierz swój fine-tunowany model, wpisz prompt, kliknij Submit.
Przetestuj model na przykładach, których NIE było w datasecie treningowym. Czy odpowiedzi są lepsze niż z bazowego modelu?
Jeśli NIE:
- Sprawdź jakość danych treningowych (może są niespójne?)
- Dodaj więcej przykładów (50 to minimum, ale 100-200 daje lepsze wyniki)
- Zmień liczbę epok (domyślnie OpenAI dobiera auto, ale możesz wymusić 1-4)
Jeśli TAK:
Wdróż model w produkcji. Pamiętaj, że kosztuje więcej niż bazowy - monitoruj koszty.
Widziałem firmy płacące $500 za fine-tuning, gdy wystarczyło dodać 3 zdania do system promptu. Zanim zaczniesz, spróbuj poprawić prompt. Dopiero gdy osiągniesz sufit - idź w fine-tuning.
100 przykładów, które są prawie identyczne = 1 przykład powtórzony 100 razy. Model nauczy się jednego wzorca i będzie bezradny wobec czegokolwiek innego.
Ktoś wrzuca dane treningowe z błędami ortograficznymi, niespójnym tonem, czasem błędnymi odpowiedziami. Model nauczy się błędów. Każdy przykład musi być perfekcyjny.
"Chcę, żeby model był lepszy w marketingu". To nie jest zadanie do fine-tuningu. Fine-tuning działa na konkretne, wąskie zadania: "Generuj opisy produktów w stylu naszego brandbooka" - to już tak.
Fine-tunowany model kosztuje 2x więcej niż bazowy. Jeśli Twoja aplikacja obsługuje 1M requestów miesięcznie, różnica to tysiące dolarów. Upewnij się, że fine-tuning faktycznie daje wartość, która to uzasadnia.
To pytanie wraca w kółko. Oto prosta matryca decyzyjna:
Wybierz RAG, jeśli:
- Potrzebujesz, żeby model znał aktualne dane (ceny produktów, dokumentacja, FAQ)
- Dane zmieniają się często (fine-tuning wymaga ponownego treningu za każdym razem)
- Masz dużo danych, ale nie w formacie konwersacji (dokumenty, PDFy, bazy wiedzy)
- Chcesz kontrolować, jakie źródła model cytuje
Wybierz fine-tuning, jeśli:
- Potrzebujesz konsystentnego stylu/formatu, nie wiedzy faktograficznej
- Dane są stabilne (np. styl pisania Twojej firmy nie zmienia się co tydzień)
- Chcesz zredukować długość promptu (RAG wymaga wklejania kontekstu w każdym requeście)
- Zadanie wymaga nauki wzorców (klasyfikacja, ekstrakcja encji)
Możesz użyć obu: Fine-tuning dla stylu + RAG dla wiedzy. Model fine-tunowany na Twoim tonie + RAG dostarczający aktualne dane = najlepsza kombinacja dla wielu aplikacji.
Jeśli chcesz zgłębić temat RAG i wdrażania AI, sprawdź nasz przewodnik po wdrażaniu modeli w produkcji.
OpenAI to nie jedyna opcja. Inne platformy oferują fine-tuning (czasem taniej, czasem z lepszymi modelami bazowymi):
Anthropic (Claude): Nie oferuje publicznego fine-tuningu. Tylko dla enterprise klientów z dedykowanym wsparciem.
Google Vertex AI (Gemini): Możesz fine-tunować Gemini 1.5 Flash. Proces podobny do OpenAI, ale przez Google Cloud Console. Ceny: ~$3-4 za 1000 przykładów treningowych.
Cohere: Oferuje fine-tuning modeli Command. Prostszy interfejs niż OpenAI, dobry dla zadań klasyfikacji i generowania tekstu. Ceny od $1 za 1000 przykładów.
Hugging Face AutoTrain: Jeśli chcesz fine-tunować modele open-source (Llama 4, Qwen 3), AutoTrain to no-code narzędzie. Płacisz tylko za compute (GPU), nie za API.
Replicate: Fine-tuning Llama, Mistral i innych modeli open-source. Prosty interfejs, płacisz za czas GPU (~$0.50-2/godzina).
Nie (kwiecień 2026). OpenAI nie udostępnił jeszcze fine-tuningu dla GPT-5. Dostępne modele to GPT-4o i GPT-4o-mini. GPT-5 jest dostępny tylko przez standardowe API.
Od 10 minut (GPT-4o-mini, 50 przykładów) do kilku godzin (GPT-4o, 1000+ przykładów). Średnio: 20-40 minut dla typowego datasetu (100-200 przykładów).
Tak. Wejdź na platform.openai.com/finetune, znajdź model, kliknij "Delete". Przestaniesz za niego płacić. Uwaga: nie odzyskasz kosztów treningu (to jednorazowa opłata).
Nie przez OpenAI API (kwiecień 2026). OpenAI nie oferuje fine-tuningu dla DALL-E ani GPT-4 Vision. Możesz fine-tunować tylko modele tekstowe. Dla obrazów sprawdź Stable Diffusion (DreamBooth, LoRA) lub Midjourney Style Tuner.
Tak. GPT-4o i GPT-4o-mini radzą sobie dobrze z polskim. Twoje dane treningowe mogą być w dowolnym języku. Jakość fine-tuningu zależy od jakości danych, nie od języka.
Twój fine-tunowany model pozostanie dostępny. OpenAI nie usuwa starszych wersji (np. fine-tuning na GPT-4o-mini-2024-07-18 będzie działał nawet jak wyjdzie GPT-4o-mini-2025-01-01). Możesz wtedy zdecydować, czy fine-tunować ponownie na nowym modelu bazowym.
Ten poradnik to dopiero początek. W naszym kursie "Praktyczna AI" nauczysz się korzystać z ChatGPT, Claude i innych narzędzi AI w sposób systematyczny - od zera do zaawansowanego poziomu.
Sprawdź kurs →Fine-tuning to potężne narzędzie, ale nie dla każdego. Jeśli potrzebujesz konsystentnego stylu, specjalistycznej terminologii lub redukcji kosztów przy dużej skali - ma sens. Jeśli chcesz po prostu "lepszego ChatGPT" - zacznij od poprawy promptów lub RAG.
Koszty są rozsądne (od kilku centów za trening), ale używanie fine-tunowanego modelu kosztuje 2x więcej niż bazowego. Liczy się ROI: czy korzyści (lepsze wyniki, krótsze prompty, konsystencja) przeważają koszty?
Dane to fundament. 50-100 wysokiej jakości przykładów to minimum. Bez nich fine-tuning to strzał w ciemno.
Zanim wydasz dolara na fine-tuning, weź 10 przykładów interakcji, które chcesz ulepszyć, i przetestuj je z bazowym modelem + dobrym promptem. Jeśli wyniki są słabe - masz case do fine-tuningu. Jeśli wystarczające - oszczędziłeś czas i pieniądze.
Na podstawie: OpenAI Fine-tuning Guide, OpenAI Pricing
Podoba Ci się ten artykuł?
Co piątek wysyłam podsumowanie najlepszych artykułów tygodnia. Zapisz się!
90 minut praktycznej wiedzy o AI. Pokaze Ci krok po kroku, jak zaczac oszczedzac 10 godzin tygodniowo dzieki sztucznej inteligencji.
Zapisz sie na webinar
Od pomysłu po sprzedaż: zobacz, jak wykorzystać AI do planowania kursu online, tworzenia treści, nagrywania i marketingu bez chaosu i zgadywania.

Fine-tuning kusi, ale często wystarczy RAG albo lepszy prompt. Sprawdź, kiedy trenowanie modelu ma sens, jak przygotować dane i jak podejść do OpenAI fine-tuning API.

Konkretne zastosowania AI w content marketingu, SEO, social media, email marketingu i analityce. Praktyczny przewodnik bez buzzwordów.

Claude i ChatGPT to dwa najpopularniejsze chatboty AI. Sprawdź, który wybrać do pisania, kodowania, analizy danych i codziennej pracy - z konkretnymi przykładami użycia.

Generowanie postów, grafik i harmonogramów publikacji z pomocą AI. Konkretne narzędzia i praktyczne wskazówki dla osób, które chcą działać szybciej bez utraty jakości.

Podział dokumentów na fragmenty to fundament skutecznego RAG. Dowiedz się, jak to zrobić praktycznie - od wyboru strategii po testowanie wyników.
