Poradniki
·
13 min czytania
·
14 marca 2026
Dane audio w AI. Przewodnik dla początkujących

Źródło: Link
Źródło: Link
118 lekcji bez kodowania. ChatGPT, Claude, Gemini, automatyzacje. Notatnik AI i AI Coach w cenie.
Słyszysz, jak Siri rozpoznaje Twój głos? Widzisz, jak Shazam identyfikuje piosenki w 3 sekundy? A może zastanawiasz się, jak AI generuje muzykę, która To przypomina prawdziwy utwór?
To wszystko zaczyna się od jednej rzeczy: danych audio. I właśnie tutaj większość ludzi odpuszcza, bo "to pewnie skomplikowane". Dobra, powiedzmy to wprost: praca z danymi audio w AI wcale nie wymaga stopnia z akustyki. Wymaga zrozumienia kilku podstawowych zasad - i to właśnie dostaniesz w tym przewodniku.
Zanim AI zacznie cokolwiek rozumieć z dźwięku, musisz ten dźwięk zamienić na format, który komputer potrafi przetworzyć. Dźwięk to fala - ciśnienie powietrza zmieniające się w czasie. Mikrofon rejestruje te zmiany i przekształca je w sygnał elektryczny, a komputer zapisuje ten sygnał jako ciąg liczb.
Ten proces nazywa się próbkowaniem (sampling). że robisz zdjęcia fali dźwiękowej tysiące razy na sekundę - każde "zdjęcie" to jedna próbka. Im więcej próbek na sekundę, tym dokładniej odwzorowujesz oryginalny dźwięk.

Standardowa częstotliwość próbkowania to 44.1 kHz (44 100 próbek na sekundę) - to dokładnie to, co znajdziesz na płytach CD. Dlaczego akurat tyle? Bo ludzkie ucho słyszy częstotliwości do około 20 kHz, a według twierdzenia Nyquista-Shannona potrzebujesz co najmniej dwukrotnie większej częstotliwości próbkowania, żeby wiernie odwzorować sygnał.
Dla projektów AI częstotliwość 16 kHz często wystarcza - szczególnie przy rozpoznawaniu mowy, gdzie nie potrzebujesz pełnego spektrum audio. Niższa częstotliwość to mniejsze pliki i szybsze przetwarzanie.
Masz trzy główne opcje:
Jeśli trenujesz model od zera i masz miejsce na dysku - wybierz WAV lub FLAC. Jeśli używasz gotowego modelu do rozpoznawania mowy - MP3 w 128 kbps spokojnie wystarczy.
Masz nagrania. Teraz musisz je przygotować, żeby AI mogło się z nich czegoś nauczyć. To nie jest opcjonalny krok - to fundament całego projektu.
Twoje nagrania prawdopodobnie mają różne poziomy głośności. Jedno nagrane szeptem, drugie krzykiem, trzecie z mikrofonem przy ustach, czwarte z drugiego końca pokoju. AI potrzebuje spójności.
Normalizacja to proces wyrównywania głośności wszystkich plików do tego samego poziomu. Nie chodzi o to, żeby wszystko było jednakowo głośne dla Twojego ucha - chodzi o to, żeby amplituda sygnału (te liczby, o których mówiłem wcześniej) mieściła się w tym samym zakresie.
Standardowo normalizujesz do -3 dB lub -6 dB poniżej maksymalnej wartości, żeby uniknąć przesterowania (clipping).
Szum wentylatora, uliczny hałas, trzaski mikrofonu - to wszystko zakłóca sygnał i utrudnia AI naukę. Możesz użyć narzędzi do redukcji szumów (Audacity ma darmową funkcję Noise Reduction), ale uważaj: zbyt agresywna redukcja może zniekształcić głos.
Lepsze podejście? Nagrywaj w cichym otoczeniu od samego początku. Jeśli pracujesz z gotowym zbiorem danych - sprawdź próbki i odrzuć te z nadmiernym szumem.
Jeśli masz godzinne nagranie podcastu, a chcesz nauczyć AI rozpoznawać pojedyncze słowa - musisz podzielić to nagranie na krótsze fragmenty. To nazywa się segmentacją.
Dla rozpoznawania mowy typowe segmenty to 2-10 sekund. Dla klasyfikacji dźwięków (np. rozpoznawanie instrumentów) - 3-5 sekund. Dla analizy emocji w głosie - 5-15 sekund.
Ważne: segmenty powinny zawierać kompletne jednostki znaczeniowe. Nie przerywaj w połowie słowa czy nuty.
Stereo (dwa kanały audio) ma sens dla muzyki, ale dla większości zadań AI - szczególnie rozpoznawania mowy - wystarczy mono (jeden kanał). Mono to połowa danych do przetworzenia, czyli szybszy trening i mniejsze wymagania sprzętowe.
Konwersja stereo → mono to prosty proces: uśredniasz wartości z lewego i prawego kanału. Każde narzędzie audio potrafi to zrobić jednym kliknięciem.
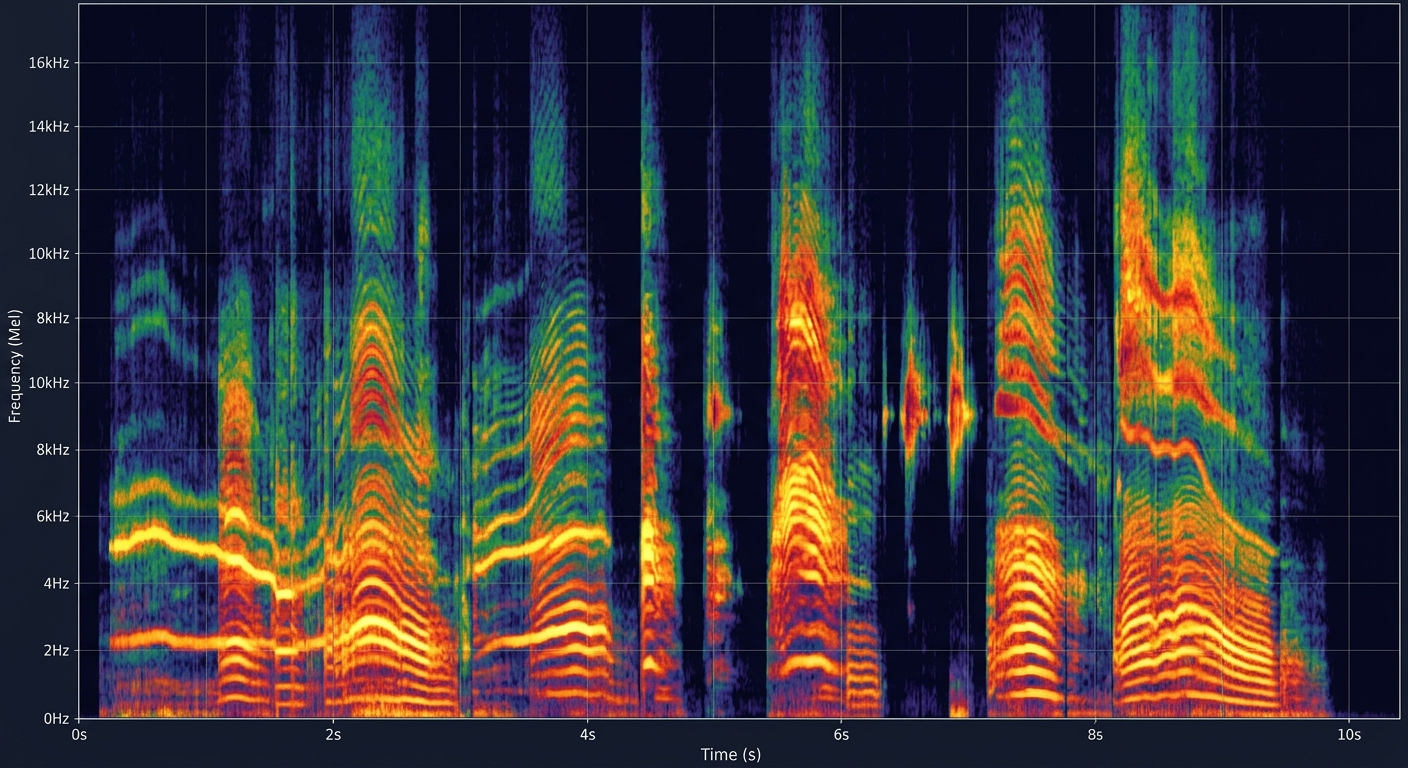
Masz czyste, znormalizowane, podzielone pliki audio. Co dalej? AI nie przetwarza ich bezpośrednio jako fal dźwiękowych - najpierw przekształca je w reprezentację wizualną zwaną spektrogramem.
Spektrogram to wykres pokazujący, jak intensywność różnych częstotliwości zmienia się w czasie. Oś X to czas, oś Y to częstotliwość, a kolor (lub jasność) to głośność danej częstotliwości w danym momencie.
Dla AI spektrogram to po prostu obrazek. I tutaj dzieje się magia: zamiast uczyć model rozumieć fale dźwiękowe (co jest trudne), uczysz go rozpoznawać wzorce na obrazkach (co AI robi znakomicie od lat).
Dlatego modele do rozpoznawania mowy często bazują na tych samych architekturach co modele do rozpoznawania obrazów - CNN (konwolucyjne sieci neuronowe).
Nie musisz trenować modelu od zera. Możesz wziąć gotowy model (np. Whisper od OpenAI do rozpoznawania mowy) i dostroić go (fine-tuning) do Twojego konkretnego przypadku użycia.
Przykład: Whisper świetnie radzi sobie z ogólnym rozpoznawaniem mowy po polsku, ale jeśli pracujesz w branży medycznej i potrzebujesz, żeby rozumiał specjalistyczne terminy - możesz go dotrenować na nagraniach z konsultacji lekarskich.
Fine-tuning wymaga mniejszego zbioru danych (setki przykładów zamiast tysięcy) i mniej mocy obliczeniowej niż trening od podstaw. To najbardziej praktyczne podejście dla większości projektów.
Jeśli interesujesz się tym tematem głębiej, sprawdź nasz przewodnik o tym, jak działa baza wektorowa AI - to technologia, która umożliwia szybkie wyszukiwanie podobnych dźwięków w ogromnych zbiorach danych.
Teoria to jedno, ale po co Ci to wszystko w praktyce? Oto trzy najpopularniejsze zastosowania danych audio w AI, które możesz wdrożyć bez doktoratu z informatyki.
Najpopularniejsze zastosowanie. Zamieniasz mowę na tekst - przydatne do transkrypcji nagrań, tworzenia napisów do filmów, obsługi głosowej aplikacji.
Gotowe narzędzia: Whisper (OpenAI), Google Speech-to-Text, Azure Speech Services. Większość z nich ma API - wysyłasz plik audio, dostajesz tekst. Nie musisz sam trenować modelu.
Polskie wsparcie? Whisper radzi sobie z polskim świetnie. Google Speech-to-Text też. Azure - również. Jeśli szukasz darmowego rozwiązania - Whisper możesz uruchomić lokalnie na swoim komputerze.
Uczysz AI rozpoznawać konkretne typy dźwięków: szczekanie psa, klakson samochodu, strzał, płacz dziecka, alarm pożarowy. Zastosowania? Monitoring bezpieczeństwa, analiza środowiska miejskiego, systemy smart home.
Przykład z życia: aplikacja dla rodziców, która wykrywa płacz dziecka i wysyła powiadomienie na telefon. Albo system w fabryce, który rozpoznaje nietypowe dźwięki maszyn i ostrzega przed awarią.
Do klasyfikacji potrzebujesz oznaczonych danych - każdy plik audio musi mieć etykietę ("szczekanie", "klakson", itd.). Im więcej przykładów każdej kategorii, tym lepiej model się uczy.
Odwrotny kierunek: zamiast analizować dźwięk, AI go tworzy. Modele jak MusicLM (Google) czy AudioCraft (Meta) generują muzykę z opisów tekstowych. Modele TTS (Text-to-Speech) zamieniają tekst na naturalnie brzmiącą mowę.
To najtrudniejsze zastosowanie, bo wymaga ogromnych zbiorów danych i mocy obliczeniowej. Ale gotowe narzędzia są już dostępne - ElevenLabs do klonowania głosu, Play.ht do generowania mowy, Suno do tworzenia muzyki.
Warto też spojrzeć na jak używać AI do nauki języków obcych - wiele z tych narzędzi wykorzystuje dokładnie te same techniki pracy z danymi audio.
Nie musisz programować od zera. Oto narzędzia, które ułatwią Ci pracę z danymi audio:
Jeśli dopiero zaczynasz przygodę z AI, zobacz też jak stworzyć własnego asystenta AI w 10 minut - to dobry punkt startowy, żeby zrozumieć, jak w ogóle pracuje się z modelami AI.
Pracowałem z danymi audio przy kilku projektach i widziałem te same błędy powtarzane w kółko. Oto cztery najczęstsze:
Nagrałeś 100 próbek swojego głosu w ciszy swojego pokoju. Model się nauczył. Testujesz w hałaśliwej kawiarni - katastrofa. Dlaczego? Bo model nauczył się rozpoznawać Twój głos w cichym pokoju, nie mowę w ogóle.
Rozwiązanie: zbieraj dane z różnych środowisk, od różnych osób, z różnym sprzętem nagraniowym. Im bardziej zróżnicowany zbiór, tym lepiej model generalizuje.
Masz 1000 przykładów dźwięku A i 50 przykładów dźwięku B. Model nauczy się rozpoznawać A perfekcyjnie, a B - prawie wcale. To oczywiste, ale zaskakująco często pomijane.
Rozwiązanie: zadbaj o podobną liczbę przykładów każdej kategorii. Jeśli nie możesz zebrać więcej danych - użyj technik augmentacji (zmiana tempa, pitch, dodanie szumu).
Redukcja szumów, kompresja, equalizacja, normalizacja, jeszcze raz kompresja... I nagle Twoje nagrania brzmią jak z radia w tunelu. AI uczy się artefaktów obróbki, nie rzeczywistego dźwięku.
Rozwiązanie: minimalna obróbka. Normalizacja głośności - tak. Usunięcie ekstremalnych szumów - tak. Wszystko inne - tylko jeśli naprawdę potrzeba.
Dźwięk "tak" wypowiedziany z entuzjazmem to co innego niż "tak" wypowiedziane z sarkazmem. Jeśli Twój model ma rozpoznawać intencje, nie tylko słowa - musisz to uwzględnić w oznaczeniach danych.
Rozwiązanie: przemyśl, co dokładnie chcesz, żeby AI rozpoznawało. Słowa? Emocje? Intencje? Kontekst? Oznaczaj dane zgodnie z tym celem.
Masz już podstawy. Czas na praktykę. Oto najprostszy projekt startowy, który możesz zrealizować w weekend:
Klasyfikator dźwięków domowych - naucz AI rozpoznawać 3-5 typowych dźwięków z Twojego domu: zamykanie drzwi, szczekanie psa, dzwonek telefonu, alarm, gotująca się woda.
To zajmie Ci 4-6 godzin, a zobaczysz cały proces od początku do końca. I zrozumiesz, dlaczego jakość danych to 80% sukcesu projektu AI.
Jeśli chcesz pójść o krok dalej i zautomatyzować więcej procesów w swoim życiu, sprawdź 10 zadań, które możesz zautomatyzować AI już dziś - znajdziesz tam konkretne pomysły na projekty.
Czy muszę znać programowanie, żeby pracować z danymi audio w AI?
Nie musisz. Narzędzia takie jak Teachable Machine (Google), Runway ML czy Hugging Face Spaces pozwalają trenować modele audio bez pisania kodu. Programowanie (Python + biblioteki jak Librosa czy TensorFlow) daje Ci więcej kontroli i możliwości, ale do podstawowych projektów nie jest wymagane. Możesz zacząć od gotowych narzędzi, a później - jeśli poczujesz potrzebę - nauczyć się kodowania.
Ile danych audio potrzebuję do wytrenowania modelu?
Zależy od zadania. Do fine-tuningu gotowego modelu (np. Whisper do rozpoznawania mowy) wystarczy 100-500 przykładów na kategorię. Do trenowania modelu od zera - tysiące, czasem dziesiątki tysięcy przykładów. Dla prostych projektów klasyfikacji (5-10 kategorii dźwięków) - 200-300 przykładów łącznie to realistyczne minimum. Pamiętaj: jakość danych > ilość danych. 100 czystych, zróżnicowanych nagrań to lepiej niż 1000 podobnych do siebie.
Czy mogę używać muzyki z YouTube do trenowania modelu?
Technicznie - tak, możesz pobrać audio z YouTube. Prawnie - to zależy. Większość materiałów na YouTube jest chroniona prawami autorskimi. Jeśli trenujesz model do użytku osobistego, niekomercyjnego - prawdopodobnie nikt nie będzie miał problemu. Jeśli planujesz komercyjne wykorzystanie modelu - musisz użyć danych, do których masz prawa. Bezpieczniejsze opcje to otwarte zbiory danych (Common Voice, FreeSound, AudioSet) lub nagrania własne. Dla projektów edukacyjnych - YouTube jest OK, ale nie publikuj modelu ani wyników komercyjnie.
Jaki komputer potrzebuję do pracy z danymi audio w AI?
Do przygotowania danych (czyszczenie, normalizacja, segmentacja) wystarczy zwykły laptop. Do trenowania modeli - zależy. Fine-tuning małych modeli możesz robić na laptopie z 8 GB RAM i przyzwoitym procesorem (proces zajmie godziny, nie minuty). Trening od zera lub praca z dużymi modelami wymaga karty graficznej NVIDIA (minimum 8 GB VRAM, optymalnie 16 GB+). Alternatywa: usługi chmurowe jak Google Colab (ma darmowy plan z dostępem do GPU), Kaggle Notebooks czy AWS. Większość początkujących projektów spokojnie zrealizujesz w darmowym Google Colab.
Czy AI może rozpoznawać emocje w głosie?
Tak, ale z ograniczeniami. Modele do rozpoznawania emocji (Speech Emotion Recognition) analizują cechy dźwięku jak tempo, wysokość tonu, głośność, drżenie głosu. Potrafią rozróżnić podstawowe emocje: radość, smutek, złość, strach, neutralność. Dokładność to około 60-80% w kontrolowanych warunkach - lepiej niż zgadywanie, gorzej niż człowiek. Problem: emocje są kulturowo zależne i kontekstowe. Ten sam ton głosu może znaczyć coś innego w różnych kulturach. Więc tak - AI potrafi, ale nie traktuj wyników jako absolutnej prawdy. To narzędzie wspierające, nie wyrocznią.
Ten poradnik to dopiero początek. W naszym kursie "Praktyczna AI" nauczysz się korzystać z ChatGPT, Claude i innych narzędzi AI w sposób systematyczny - od zera do zaawansowanego poziomu.
Sprawdź kurs →Praca z danymi audio w AI to nie czarna magia. To proces: nagrywasz lub zbierasz dźwięki, przygotowujesz je (normalizacja, czyszczenie, segmentacja), przekształcasz w format zrozumiały dla AI (spektrogramy), a potem trenujesz lub dostosujesz model.
Najważniejsze lekcje:
Dane audio to jeden z najbardziej praktycznych obszarów AI. Rozpoznawanie mowy, klasyfikacja dźwięków, generowanie audio - to wszystko już działa i jest dostępne. Nie czekaj na "idealny moment" ani "więcej wiedzy". Nagraj 20 plików, otwórz Teachable Machine i zobacz, jak to działa w praktyce.
Jeden krok na start: Otwórz Audacity (darmowy), nagraj 10 próbek swojego głosu mówiącego "tak" i 10 próbek mówiących "nie". Znormalizuj głośność (Effect → Normalize). Zapisz jako WAV. Masz pierwszy mini-zbiór danych do eksperymentów. To zajmie Ci 15 minut.
Podoba Ci się ten artykuł?
Co piątek wysyłam podsumowanie najlepszych artykułów tygodnia. Zapisz się!
90 minut praktycznej wiedzy o AI. Pokaze Ci krok po kroku, jak zaczac oszczedzac 10 godzin tygodniowo dzieki sztucznej inteligencji.
Zapisz sie na webinar
Konkretne zastosowania AI w content marketingu, SEO, social media, email marketingu i analityce. Praktyczny przewodnik bez buzzwordów.

Suno, Udio i inne generatory muzyki AI. Jak działają, jakie masz prawa do utworów i do czego naprawdę można ich używać - bez marketingowego bełkotu.

Claude i ChatGPT to dwa najpopularniejsze chatboty AI. Sprawdź, który wybrać do pisania, kodowania, analizy danych i codziennej pracy - z konkretnymi przykładami użycia.

Generowanie postów, grafik i harmonogramów publikacji z pomocą AI. Konkretne narzędzia i praktyczne wskazówki dla osób, które chcą działać szybciej bez utraty jakości.

Sora, Runway Gen-3, Kling, Veo 2 - cztery narzędzia, cztery filozofie generowania wideo. Sprawdzamy, które pasuje do Twojego projektu i ile faktycznie zapłacisz.

Google Gemini to nie jedno narzędzie, tylko cały ekosystem. Zobacz, czym różnią się Flash, Pro, Studio i API oraz jak wybrać wersję do swojej pracy.
