Poradniki
·
10 min czytania
·
29 maja 2026
Jak używać transformerów AI do analizy wideo - przewodnik

Źródło: Link
Źródło: Link
Kolega pokazał mi wczoraj aplikację fitness, która liczy pompki. Telefon leżał na podłodze, kamera skierowana na niego - i aplikacja bezbłędnie liczyła każde powtórzenie. Zapytałem: "Jak to działa?". Wzruszył ramionami: "AI, nie wiem jak".
Wiem jak. I zaraz Ci pokażę.
Znasz ChatGPT, Claude czy Gemini? To duże modele językowe LLM oparte na architekturze transformerów. Czytają tekst i rozumieją kontekst - wiedzą, że "bank" w zdaniu "poszedłem nad bank rzeki" to nie to samo co "bank" w "założyłem konto w banku".
Transformery AI w przetwarzaniu wideo robią dokładnie to samo - tylko zamiast słów analizują klatki filmu. Patrzą na sekwencję obrazów i rozumieją, co się dzieje: czy to człowiek robi pompkę, czy pies biega po podwórku, czy kierowca wjeżdża na czerwonym świetle.
Różnica między starszymi metodami a transformerami? Stare algorytmy analizowały każdą klatkę osobno. Jak ktoś czytający książkę słowo po słowie bez łączenia ich w zdania. Transformery patrzą na całą sekwencję i rozumieją relacje między klatkami.
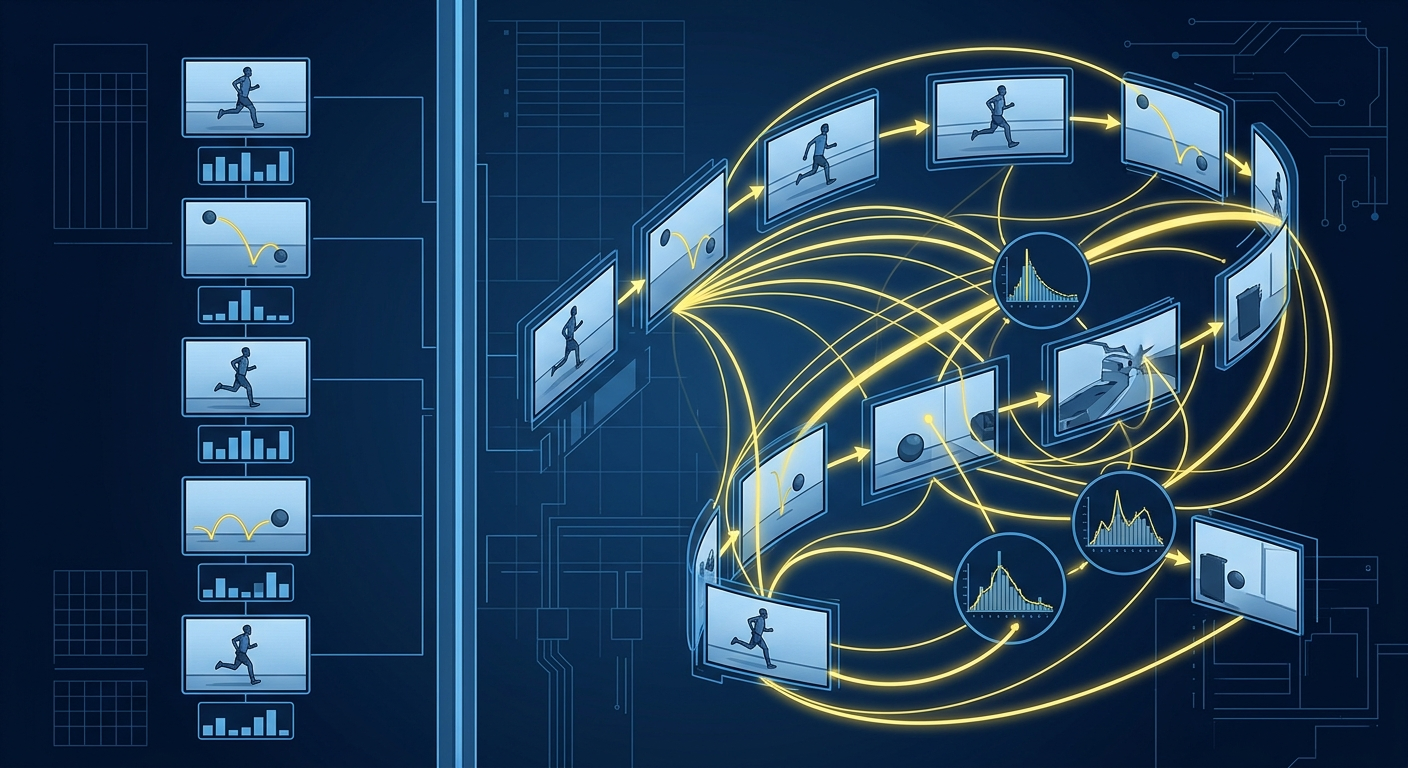
Kluczowy element to mechanizm uwagi (attention mechanism). Działa jak Twoja uwaga podczas oglądania filmu - automatycznie skupiasz się na tym, co ważne. Gdy na ekranie pojawia się postać trzymająca pistolet, Twój wzrok idzie tam, a nie na drzewo w tle.
Transformer robi to samo. Analizując wideo z pompkami, wie, że pozycja łokci i tułowia ma znaczenie, a kolor podłogi - nie. Przy filmie z ulicy skupia się na samochodach i znakach, ignorując chmury.
Ta umiejętność odróżniania sygnału od szumu sprawia, że transformery w wizji komputerowej AI działają skuteczniej niż starsze metody przy mniejszej ilości danych treningowych.
Nie musisz czekać na przyszłość. Transformery analizują wideo w narzędziach, z których korzystasz codziennie:
Włączasz napisy pod filmem w języku obcym? YouTube używa transformerów do rozpoznawania mowy (audio) i synchronizacji z obrazem. Dodatkowo algorytm dzieli długie filmy na rozdziały - analizuje zarówno dźwięk, jak i obraz, żeby znaleźć momenty zmiany tematu.
Sprawdź: wejdź na dowolny długi film edukacyjny na YouTube. Kliknij "Pokaż transkrypcję" pod opisem. Widzisz automatycznie wygenerowany tekst z znacznikami czasu? To efekt działania transformerów.
Wgrywasz film na Facebooka. Zanim ktokolwiek go zobaczy, algorytm sprawdza, czy nie zawiera przemocy, nagości czy dezinformacji. Stare systemy analizowały pojedyncze klatki - łatwo je było oszukać, wstawiając kontrowersyjną scenę między neutralne ujęcia.
Transformery patrzą na kontekst. Rozpoznają, że sekwencja ruchów to walka (nawet jeśli pojedyncza klatka wygląda niewinnie), albo że seria ujęć tworzy narrację dezinformacyjną.

Wracam do przykładu z początku. Aplikacje jak Nike Training Club czy Freeletics używają transformerów do rozpoznawania ćwiczeń. Nie mierzą tylko pozycji ciała w jednej klatce - śledzą ruch w czasie, sprawdzają płynność wykonania, wykrywają błędy w technice.
Możesz to przetestować bez instalowania niczego. Otwórz aparat w telefonie, włącz tryb wideo, postaw telefon pod kątem 45 stopni i zrób 5 przysiadów. Potem wgraj film do dowolnej darmowej aplikacji fitness z funkcją analizy ruchu. Dostaniesz feedback o technice - to właśnie wizja komputerowa AI oparta na transformerach.
Nie musisz być programistą. Oto trzy scenariusze, w których możesz wykorzystać transformery do wideo już dziś:
Masz 200 filmów z konferencji. Chcesz je posegregować: prezentacje, panele dyskusyjne, Q&A. Ręczne przeglądanie zajmie godziny.
Rozwiązanie: Użyj gotowego narzędzia jak Google Cloud Video Intelligence API (wariant Vision AI) lub Azure Video Analyzer. Wgrywasz pliki, wybierasz "klasyfikacja scen" - system analizuje każdy film i przypisuje kategorie. Koszt: około 0.10 USD za minutę wideo.
Krok po kroku:
Nie piszesz ani linijki kodu. Interfejs webowy robi wszystko za Ciebie.
Prowadzisz sklep budowlany. Klienci przysyłają filmy z problemami - przeciek w łazience, pęknięta ściana. Chcesz automatycznie wykryć, jakie produkty polecić (uszczelka, gips, farba).
Rozwiązanie: Użyj modelu wykrywania obiektów wytrenowanego na danych budowlanych. Hugging Face (platforma z gotowymi modelami AI) oferuje modele transformerów do wizji komputerowej - możesz je przetestować przez przeglądarkę.
Krok po kroku:
Jeśli potrzebujesz rozpoznawać specyficzne obiekty (np. konkretne narzędzia), musisz dostarczyć własne dane treningowe - to już temat na kurs AI Evolution, gdzie pokazujemy fine-tuning modeli.
Prowadzisz kursy online. Chcesz wiedzieć, w którym momencie kursu studenci przewijają wideo - może tam jest problem z wyjaśnieniem?
Rozwiązanie: Użyj narzędzia do analizy engagement wideo, które śledzi ruchy myszy i przewijanie. Jeśli chcesz analizować gesty osób w filmie (np. czy instruktor gestykuluje zbyt chaotycznie), potrzebujesz modelu rozpoznawania pozy (pose estimation).
Krok po kroku (dla analizy gestów instruktora):
To nie jest pełnoprawny transformer (Teachable Machine używa uproszczonej architektury). Działa na tej samej zasadzie - analizuje sekwencje klatek, nie pojedyncze obrazy.
Transformery do wideo nie są magią. Mają ograniczenia:
Wymagania techniczne: Analiza wideo wymaga mocy obliczeniowej. Jeśli testujesz lokalnie na laptopie, przetworzenie 10-minutowego filmu może zająć 30-60 minut. Usługi w chmurze (Google Cloud, Azure) są szybsze, ale kosztują.
Jakość danych: Model wytrenowany na filmach z YouTube nie rozpozna specjalistycznych sytuacji (np. diagnostyka medyczna, kontrola jakości w fabryce). Potrzebujesz wtedy własnych danych treningowych - minimum 500-1000 przykładów każdej kategorii.
Prywatność: Wgrywając filmy do usług chmurowych, wysyłasz dane na serwery firm. Jeśli analizujesz materiały poufne (nagrania z kamer monitoringu, dane medyczne), sprawdź regulamin - niektóre usługi używają przesłanych danych do treningu własnych modeli.
Koszt: Darmowe limity wystarczą do testów (Google Cloud Video Intelligence: 1000 minut/miesiąc za darmo). Przy większej skali (setki godzin wideo miesięcznie) koszt rośnie do setek dolarów. Alternatywa: modele open-source uruchamiane lokalnie (np. DeepSeek V4-Flash) - wymaga wiedzy technicznej, ale eliminuje koszty API.
Błąd 1: Za długie wideo na start. Testujesz na 2-godzinnym filmie i czekasz pół dnia na wyniki. Zacznij od 30-sekundowego fragmentu. Sprawdź, czy model w ogóle rozpoznaje to, czego potrzebujesz. Potem skalujesz.
Błąd 2: Oczekiwanie perfekcji. Model pokazuje 85% accuracy i myślisz "to za mało". W praktyce 85% to często wystarczy - oszczędzasz czas na wstępnej selekcji, a 15% błędów poprawiasz ręcznie. Alternatywa to 100% ręcznej roboty.
Błąd 3: Ignorowanie kontekstu. Wgrywasz film z konferencji nagrany telefonem (trzęsący obraz, słabe światło) i dziwisz się, że rozpoznawanie twarzy nie działa. Modele trenowane są na określonym typie danych - zazwyczaj profesjonalnych nagraniach. Jeśli Twoje wideo ma inną jakość, wyniki będą gorsze.
Tak, do podstawowych zadań (klasyfikacja, wykrywanie obiektów) wystarczą gotowe narzędzia z interfejsem webowym - Google Cloud Video Intelligence, Azure Video Analyzer, Hugging Face Inference API. Klikasz, wgrywasz, dostajesz wyniki. Jeśli potrzebujesz dostosować model do specyficznych potrzeb (np. rozpoznawanie własnych kategorii), będziesz musiał nauczyć się podstaw - albo zatrudnić kogoś technicznego.
Google Cloud Video Intelligence: pierwsze 1000 minut miesięcznie za darmo, potem około 0.10 USD za minutę. Azure Video Analyzer: podobnie. Hugging Face Inference API: 30,000 żądań miesięcznie za darmo (jedno żądanie = jeden krótki film). Przy większej skali (setki godzin) koszt rośnie do setek dolarów miesięcznie. Tańsza opcja: modele open-source (DeepSeek V4-Flash, Llama 4 Scout) uruchamiane na własnym serwerze - wymaga wiedzy technicznej.
Stare metody (CNN - convolutional neural networks) analizowały każdą klatkę osobno, bez kontekstu czasowego. Transformery patrzą na sekwencje klatek i rozumieją relacje między nimi - wiedzą, że seria ruchów to pompka, a nie przypadkowe zmiany pozycji. Dodatkowo mechanizm uwagi pozwala skupić się na istotnych fragmentach obrazu, ignorując tło. Efekt: lepsza accuracy przy mniejszej ilości danych treningowych.
Zależy od modelu i sprzętu. Lekkie modele (np. MobileViT) działają w czasie rzeczywistym na smartfonach - używane w aplikacjach fitness czy filtrach AR. Cięższe modele (np. Video Swin Transformer) wymagają GPU i przetwarzają wideo z opóźnieniem kilku sekund. Do analizy nagrań archiwalnych opóźnienie nie ma znaczenia. Do aplikacji live (monitoring, sport) potrzebujesz szybszego modelu lub mocniejszego sprzętu.
Analiza obrazu (rozpoznawanie obiektów, ruchów, scen) nie zależy od języka - działa tak samo dla polskich i angielskich filmów. Problem pojawia się przy analizie audio (napisy, rozpoznawanie mowy). Większość modeli trenowana jest na danych anglojęzycznych. Dla języka polskiego potrzebujesz specjalistycznego modelu - np. Whisper od OpenAI (obsługuje 99 języków, w tym polski) lub polskie rozwiązania jak Techmo TTS. W kursie AI Evolution pokazujemy, jak łączyć różne modele w pipeline.
Ten poradnik to dopiero początek. W naszym kursie "Praktyczna AI" nauczysz się korzystać z ChatGPT, Claude i innych narzędzi AI w sposób systematyczny - od zera do zaawansowanego poziomu.
Sprawdź kurs →Transformery AI w przetwarzaniu wideo to ta sama technologia, która napędza ChatGPT i Claude - tylko zamiast czytać tekst, analizują sekwencje obrazów. Rozumieją kontekst, odróżniają istotne elementy od szumu, uczą się z mniejszej ilości danych niż starsze metody.
Używasz ich już codziennie: w napisach na YouTube, moderacji treści na Facebooku, aplikacjach fitness. Możesz zacząć wykorzystywać je świadomie - do klasyfikacji filmów, rozpoznawania obiektów, analizy ruchu. Bez kodowania, przez gotowe narzędzia w chmurze.
Ograniczenia? Koszt przy dużej skali, wymagania sprzętowe, potrzeba własnych danych treningowych dla specjalistycznych zastosowań. Do większości podstawowych zadań wystarczą darmowe limity i modele ogólnego przeznaczenia.
Jeden krok na start: Wejdź na huggingface.co/models, przefiltruj po "Video Classification", wybierz pierwszy model z listy i przetestuj go na 30-sekundowym fragmencie dowolnego filmu z Twojego telefonu. Zobaczysz, jak transformer rozpoznaje akcje w wideo - bez instalowania niczego, przez przeglądarkę. To zajmie Ci 5 minut i pokażesz sobie, że to nie magia zarezerwowana dla programistów.
Na podstawie: materiałów kursu AI Evolution (sukcesai.com)
Przeczytaj też:
10 gotowych promptów do codziennej pracy + 5 narzędzi + plan na pierwszy tydzień. PDF, 4 strony konkretu.

AI może skrócić pisanie książki o miesiące - albo zrujnować jej wartość. Narzędzia, techniki i granice, których nie wolno przekraczać.

Chcesz stworzyć aplikację AI, ale nie jesteś programistą? Platformy low-code to Twoja szansa. Sprawdź, jak zbudować działające narzędzie w kilka godzin.

Sora, Runway Gen-3, Kling, Veo 2 - cztery narzędzia, cztery filozofie generowania wideo. Sprawdzamy, które pasuje do Twojego projektu i ile faktycznie zapłacisz.

Claude i ChatGPT to dwa najpopularniejsze chatboty AI. Sprawdź, który wybrać do pisania, kodowania, analizy danych i codziennej pracy - z konkretnymi przykładami użycia.

Generowanie postów, grafik i harmonogramów publikacji z pomocą AI. Konkretne narzędzia i praktyczne wskazówki dla osób, które chcą działać szybciej bez utraty jakości.
![AI do tworzenia prezentacji - narzędzia i techniki [2026]](https://sukcesai.com/uploads/images/imagen-1784880308406.webp)
Gamma, Beautiful.ai, Canva AI i ChatGPT tworzą slajdy w minuty. Które narzędzie wybrać, jak pisać prompty i kiedy AI zastąpi PowerPointa - praktyczny przewodnik bez marketingowego bełkotu.
