Poradniki
·
9 min czytania
·
26 maja 2026
Jak zrozumieć sieci neuronowe - przewodnik od regresji logistycznej

Źródło: Link
Źródło: Link
Kolega programista pokazał mi kiedyś diagram sieci neuronowej. Setki połączonych kółek, strzałki w każdą stronę, warstwy na warstwach. Pomyślałem: to wygląda jak mapa metra w Tokio. I odłożyłem temat na później.
Błąd.
Sieci neuronowe nie zaczynają się od skomplikowanych diagramów. Zaczynają się od czegoś, co możesz zrozumieć w 10 minut - regresji logistycznej.
Wykład 10 kursu CS229 na Stanford (Andrew Ng, jesień 2018) zaczyna się od prostego pytania: pamiętacie regresję logistyczną? To algorytm klasyfikacji. Dostajesz obraz, odpowiadasz: kot czy nie kot. 1 albo 0. Proste.
I tu jest haczyk - regresja logistyczna to już jest sieć neuronowa. Najprostsza możliwa. Jeden neuron, który bierze dane wejściowe (piksele obrazu), przetwarza je i daje odpowiedź. Jeśli to zrozumiesz, reszta to tylko dodawanie kolejnych warstw.
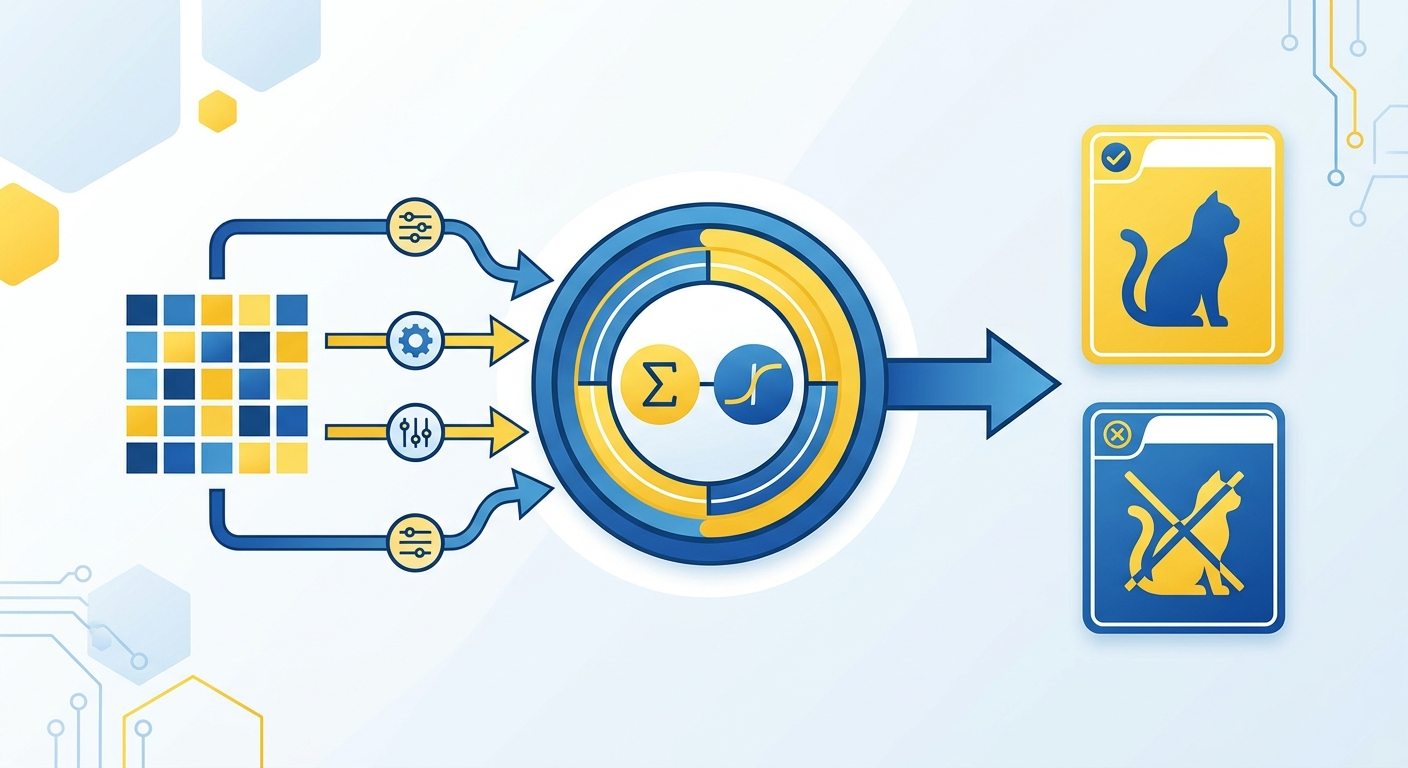
Przykład z wykładu: wykrywanie kotów na zdjęciach. Masz obraz. Przekształcasz go w liczby (piksele). Wpuszczasz do algorytmu. Algorytm uczy się, które kombinacje pikseli oznaczają kota. Po treningu dostaje nowe zdjęcie i mówi: kot (blisko 1) albo nie kot (blisko 0).
Andrew Ng wymienia trzy powody, dla których deep learning nagle zaczął działać w praktyce (a nie tylko w teorii):
Moc obliczeniowa. Sieci neuronowe są obliczeniowo drogie. Musisz przetwarzać miliony parametrów, miliony razy. CPU by się gotowało. Rozwiązanie? GPU - procesory graficzne, które potrafią robić tysiące obliczeń równolegle. To samo, co renderuje grafikę w grach, teraz trenuje modele AI.
Dane. Po boomie internetowym mamy dostęp do gigantycznych zbiorów danych. Zdjęcia, teksty, nagrania. Sieci neuronowe są głodne danych - im więcej dostaną, tym lepiej się uczą. Bez Internetu nie byłoby deep learningu w dzisiejszej formie.
Algorytmy. Ludzie wymyślili techniki, które sprawiają, że trening jest szybszy i skuteczniejszy. Backpropagation, dropout, batch normalization. Nie musisz znać szczegółów - ważne, że to działa.
Regresja logistyczna to jeden neuron. Sieć neuronowa to wiele neuronów ułożonych w warstwy. Pierwsza warstwa bierze surowe dane (piksele). Każda kolejna warstwa wyciąga coraz bardziej abstrakcyjne cechy. Ostatnia warstwa daje odpowiedź.
Przykład z rozpoznawaniem obrazów:
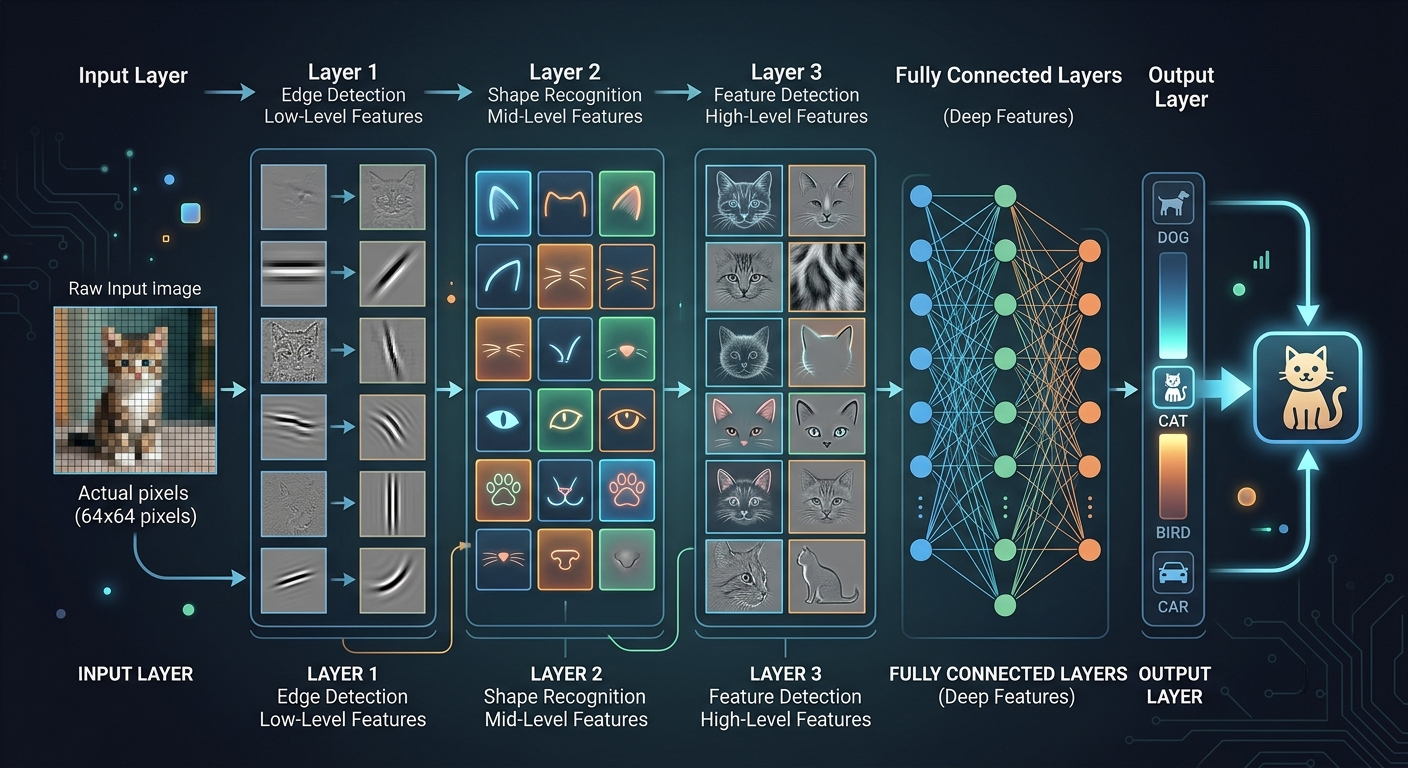
Każda warstwa uczy się automatycznie podczas treningu. Nie programujesz ręcznie "szukaj uszu kota". Dajesz sieci tysiące zdjęć kotów i nie-kotów, a ona sama znajduje wzorce. To jest magia - i jednocześnie matematyka.
Wykład wspomina o zastosowaniach: rozpoznawanie obrazów, przetwarzanie języka naturalnego, rozpoznawanie mowy. To nie jest teoria - to narzędzia, których używasz codziennie.
Asystent głosowy w telefonie? Sieć neuronowa przetwarza dźwięk na tekst. Aparat rozpoznający twarze? Sieć neuronowa. Tłumacz w czasie rzeczywistym? Znowu sieć neuronowa. Modele takie jak GPT-5, Claude Opus 4.7 czy Gemini 3.1 Pro to ogromne sieci neuronowe trenowane na miliardach parametrów.
I wszystko zaczyna się od tej jednej prostej idei: weź dane, przetwórz je przez warstwy neuronów, dostań odpowiedź. Reszta to skalowanie.
Jeśli chcesz zrozumieć sieci neuronowe głębiej (nie tylko czytać o nich), potrzebujesz:
Nie potrzebujesz doktoratu. Kurs CS229 jest dla studentów trzeciego roku. Jeśli rozumiesz podstawy regresji logistycznej, jesteś w grze.
Oto konkretny plan, jeśli chcesz przejść od zera do zrozumienia sieci neuronowych:

Pułapka 1: Za duża sieć na start. Nie zaczynaj od ResNet-152. Zacznij od 2-3 warstw. Zrozum podstawy, potem skaluj.
Pułapka 2: Brak walidacji. Model działa świetnie na danych treningowych, ale pada na nowych? To overfitting. Zawsze dziel dane na trening/walidację/test.
Pułapka 3: Ignorowanie preprocessingu. Normalizacja danych, augmentacja obrazów, czyszczenie tekstów - to nudne, ale krytyczne. Śmieci na wejściu = śmieci na wyjściu.
Pułapka 4: Brak cierpliwości. Trening zajmuje czas. Pierwszy model będzie słaby. Dziesiąty będzie lepszy. Setny będzie dobry. To maraton, nie sprint.
Nie musisz wszystkiego budować od zera. Ekosystem AI w 2026 roku daje Ci gotowe rozwiązania:
Jeśli chcesz zbudować chatbota AI lub własny model językowy, te narzędzia są punktem wyjścia.
Wykład 10 CS229 to dopiero początek. Andrew Ng w kolejnych wykładach omawia:
Każdy temat to kolejna warstwa zrozumienia. Wszystko wraca do tej prostej idei: neurony połączone w warstwy, uczące się z danych.
Jeśli interesuje Cię praktyczne zastosowanie, zobacz jak pisać lepsze prompty do modeli AI lub jak używać AI do nauki języków - to efekty tych samych sieci neuronowych, tylko "od strony użytkownika".
Ten poradnik to dopiero początek. W naszym kursie "Praktyczna AI" nauczysz się korzystać z ChatGPT, Claude i innych narzędzi AI w sposób systematyczny - od zera do zaawansowanego poziomu.
Sprawdź kurs →Sieci neuronowe nie są magią. To matematyka, dane i moc obliczeniowa. Zaczynają się od prostej regresji logistycznej - jednego neuronu klasyfikującego dane. Dodajesz warstwy, dostajesz elastyczność. Dodajesz dane i GPU, dostajesz modele, które rozpoznają obrazy, rozumieją język i prowadzą rozmowy.
Kurs CS229 pokazuje tę drogę krok po kroku. Od podstaw do zaawansowanych technik. Bez skrótów, bez zbędnej komplikacji.
Jeden krok na start: Otwórz Google Colab, znajdź tutorial "logistic regression from scratch" i zaimplementuj go. Nie czytaj - pisz kod. Zobaczysz, jak model uczy się klasyfikować dane. To 30 minut, które dadzą Ci więcej zrozumienia niż 10 godzin czytania.
Nie musisz. Wystarczy intuicja z algebry liniowej (macierze, wektory) i rachunku różniczkowego (pochodne). Kurs CS229 zakłada podstawy matematyki na poziomie studiów inżynierskich, ale większość konceptów można zrozumieć wizualnie. Jeśli umiesz mnożyć macierze i rozumiesz, czym jest gradient, jesteś w grze.
Trzy powody: moc obliczeniowa GPU (procesory graficzne potrafią robić tysiące obliczeń równolegle), dostępność ogromnych zbiorów danych po boomie internetowym oraz nowe algorytmy optymalizacji. Teoria sieci neuronowych istnieje od lat 80., ale dopiero te trzy czynniki sprawiły, że stała się praktyczna.
Zależy od tempa i celu. Podstawy (regresja logistyczna, prosta sieć neuronowa) - 2-4 tygodnie intensywnej nauki. Poziom pozwalający trenować własne modele na realnych danych - 2-3 miesiące. Poziom profesjonalny (praca w branży) - 6-12 miesięcy z systematyczną praktyką. Kluczowe jest kodowanie, nie tylko czytanie.
Tak. Google Colab daje darmowy dostęp do GPU w chmurze. Kaggle również oferuje darmowe sesje GPU. Do nauki podstaw wystarczy zwykły laptop - małe sieci trenują się w minuty. Dopiero przy dużych projektach (miliony parametrów, gigabajty danych) potrzebujesz mocniejszego sprzętu, ale wtedy możesz wynająć GPU w chmurze za kilka dolarów na godzinę.
Deep learning to po prostu sieci neuronowe z wieloma warstwami (stąd "deep" - głębokie). Klasyczna sieć neuronowa ma 1-2 warstwy ukryte. Deep learning to 10, 50, 100+ warstw. Więcej warstw = większa elastyczność = lepsze wyniki na skomplikowanych zadaniach (obrazy, język, dźwięk). Też większe wymagania obliczeniowe i więcej danych do treningu.
10 gotowych promptów do codziennej pracy + 5 narzędzi + plan na pierwszy tydzień. PDF, 4 strony konkretu.

Regresja logistyczna brzmi skomplikowanie, ale to podstawa AI, która działa w Twoim telefonie. Sprawdź, jak działa i gdzie ją wykorzystasz - bez matematyki.

AI może skrócić pisanie książki o miesiące - albo zrujnować jej wartość. Narzędzia, techniki i granice, których nie wolno przekraczać.

Propagacja wsteczna to matematyczny rdzeń każdej sieci neuronowej. Zbudujesz własny silnik autograd krok po kroku - bez bibliotek, z pełnym zrozumieniem mechanizmu.

Prognozowanie sprzedaży, ruchu na stronie czy cen - wszystko to możesz zrobić z ARIMA. Dowiedz się, jak działa ta metoda i jak ją zastosować bez wiedzy technicznej.

Chcesz stworzyć aplikację AI, ale nie jesteś programistą? Platformy low-code to Twoja szansa. Sprawdź, jak zbudować działające narzędzie w kilka godzin.

Claude i ChatGPT to dwa najpopularniejsze chatboty AI. Sprawdź, który wybrać do pisania, kodowania, analizy danych i codziennej pracy - z konkretnymi przykładami użycia.
