Narzedzia AI
·
6 min czytania
·
6 lutego 2026
Prompt Fidelity: ile z Twojej komendy AI naprawdę wykonuje?

Źródło: Link
Źródło: Link
Szkolenia, warsztaty i wdrożenia AI. Dopasowane do Twojego zespołu.
Wysyłasz do AI-agenta szczegółową komendę. Dostajesz odpowiedź – długą, pewną siebie, wyglądającą na profesjonalną.
Problem? Nie masz pojęcia, ile z tego to faktyczne wykonanie polecenia, a ile… pewny siebie blef.
I nie, to nie błąd. To cecha architektury. Modele językowe – te "mózgi" za ChatGPT, Claude czy Gemini – trenowano do generowania tekstu, który brzmi wiarygodnie. Nie mają wbudowanego mechanizmu mówiącego "hej, tego akurat nie wiem". Zamiast tego uzupełniają luki tym, co wydaje się statystycznie prawdopodobne.
Prompt Fidelity to metryka pokazująca, ile z Twojej intencji AI faktycznie realizuje.
Nie chodzi o to, czy odpowiedź brzmi dobrze. Chodzi o to, czy agent zrobił to, o co go prosiłeś. Różnica? Kolosalna.
Przykład. Prosisz AI o analizę 50 dokumentów i wyciągnięcie konkretnych danych. System generuje raport – ładny, uporządkowany, z wykresami. Sprawdzasz szczegóły. Okazuje się, że przeanalizował tylko 32 dokumenty. Reszta? Ekstrapolacja oparta na wzorcach.
Dla osoby czytającej raport: wszystko wygląda profesjonalnie.
Dla osoby podejmującej decyzje biznesowe: katastrofa.
I tu pojawia się problem — w większości przypadków nie masz prostego sposobu, żeby to sprawdzić. Model nie mówi "uwaga, to zgaduję". Po prostu generuje tekst z taką samą pewnością, niezależnie od tego, czy operuje na faktach, czy na probabilistycznych domysłach.
Badacze z Towards Data Science zaproponowali metodę pomiaru wierności wykonania. To nie jeden wskaźnik – to zestaw pytań, które możesz zadać swojemu systemowi:
Kompletność wykonania: Czy agent przeszedł przez wszystkie kroki, które zdefiniowałeś w promptcie? Prosiłeś o 5 analiz? Dostałeś 5, czy może 3 i dwie "na oko"?
Źródło danych: Skąd pochodzą informacje w odpowiedzi? Czy to dane z Twojego kontekstu, czy model "dorzucił" coś z treningu? To jak różnica między cytowaniem dokumentu a "pamiętaniem, że gdzieś coś takiego było".
Halucynacje strukturalne: Czy AI wymyśliło fakty, liczby, cytaty? To najgroźniejszy typ – bo brzmi najbardziej wiarygodnie. Model może wygenerować statystyki, które wyglądają realnie, ale nie istnieją.
Adherencja do ograniczeń: Czy system respektował Twoje warunki brzegowe? Napisałeś "tylko źródła z ostatnich 2 lat"? Czy faktycznie się do tego zastosował, czy po cichu poszerzył zakres, bo "tak lepiej"?
Nie do końca.
Modele językowe nie mają intencji Cię okłamać. Po prostu robią to, do czego zostały zaprojektowane: przewidują następne słowo w sekwencji.
Jeśli kontekst sugeruje, że powinien pojawić się wykres – wygenerują opis wykresu. Jeśli brakuje danych – uzupełnią je wzorcem. To jak autokorekta w telefonie. Pisze za Ciebie słowo, bo "statystycznie pasuje". Czasem trafia. Czasem zamienia "spotkanie o 10" na "spotkanie o 19", bo kiedyś często pisałeś o 19.
Problem narasta, gdy używasz AI-agentów do zadań autonomicznych. Agent ma wykonać serię kroków: pobrać dane, przetworzyć, wygenerować raport, wysłać. Napotyka przeszkodę? Brak dostępu do API, timeout, nieczytelny format? Nie zatrzyma się z błędem. Spróbuje "poradzić sobie" – czyli zgadnąć.
Efekt? Raport ląduje w Twojej skrzynce. Wygląda OK. Podejmujesz decyzję.
A połowa danych to artefakt statystyczny.
Nie chodzi o to, żeby przestać używać AI. Chodzi o to, żeby używać go świadomie. Kilka praktycznych zasad:
Wymagaj logów wykonania. Jeśli budujesz system z AI-agentem, dodaj warstwę raportowania: co agent faktycznie zrobił, jakie API wywołał, jakie dane dostał.
Testuj na znanych danych. Przed wdrożeniem agenta na produkcję daj mu zadanie, którego wynik znasz. Prosisz o analizę 10 dokumentów i wiesz, co powinno wyniknąć? Łatwo sprawdzisz, czy agent nie "dorabia" faktów.
Używaj promptów strukturalnych. Zamiast "przeanalizuj i napisz raport", sprecyzuj: "przeanalizuj dokumenty A, B, C. Dla każdego wyciągnij X, Y, Z. Jeśli dane są niekompletne, napisz 'brak danych' zamiast szacować".
Weryfikuj krytyczne decyzje. Jeśli AI generuje coś, na czym opierasz strategię biznesową, inwestycję, diagnozę – sprawdź ręcznie losową próbkę. 10% danych wystarczy, żeby złapać systemowe halucynacje.
Używaj modeli z citation tracking. Niektóre systemy (jak Perplexity, nowe wersje Claude) potrafią linkować fragmenty odpowiedzi do konkretnych źródeł. To nie jest idealne, ale daje punkt zaczepienia do weryfikacji.
Większość osób używa AI przez interfejsy – ChatGPT, Gemini, Copilot. Nie budujesz agentów, nie piszesz kodu.
Prompt Fidelity dotyczy Cię równie mocno.
Za każdym razem, gdy prosisz AI o coś więcej niż drobne zadanie – research, podsumowanie dokumentów, analizę opcji – ryzykujesz, że część odpowiedzi to "confident guesswork".
Przykład z życia: przedsiębiorca prosi ChatGPT o porównanie trzech narzędzi do email marketingu. Model generuje tabelkę z cenami, funkcjami, limitami. Wygląda świetnie. Przedsiębiorca wybiera narzędzie. Po tygodniu okazuje się, że ceny były z 2023 roku (model się "domyślił" na podstawie treningu), a kluczowa funkcja, którą wymienił AI… nie istnieje.
Nic złego się nie stało – poza zmarnowanym czasem i frustracją.
Rozwiązanie? Traktuj AI jak asystenta, który jest świetny w roboczych wersjach, ale kiepski w finalnej weryfikacji. Niech zbierze informacje, przygotuje draft, zaproponuje opcje.
Kluczowe fakty – sprawdź sam.
Dobre wieści? Branża zaczyna to dostrzegać.
Nowe architektury eksperymentują z mechanizmami uncertainty quantification – czyli próbują nauczyć modele mówić "tego nie wiem na pewno". OpenAI testuje systemy, które zamiast halucynować, zwracają "confidence score" – ocenę pewności dla każdego fragmentu odpowiedzi. Anthropic (twórcy Claude) rozwija Constitutional AI – modele trenowane do przyznawania się do niewiedzy zamiast zgadywania.
Google w Gemini 2.0 dodał funkcję "grounding" – kotwiczenie odpowiedzi w konkretnych, zweryfikowanych źródłach. To nie jest idealne (model wciąż może coś przeoczyć), ale zmienia dynamikę: zamiast "ufaj mi" dostajesz "sprawdź tutaj".
To nie rozwiązuje problemu całkowicie. Przesuwa ciężar z "wykrywania kłamstw" na "weryfikację źródeł".
A to jest o wiele łatwiejsze.
Prompt Fidelity to nie akademicki koncept. To praktyczne narzędzie do oceny, jak bardzo możesz polegać na tym, co AI Ci generuje.
Nie chodzi o to, żeby przestać ufać AI. Chodzi o to, żeby ufać rozsądnie – wiedząc, gdzie model jest mocny (generowanie struktury, propozycje, drafty), a gdzie słaby (fakty, liczby, precyzyjne wykonanie wieloetapowych zadań).
Bo różnica między "AI mi pomogło" a "AI mnie wprowadziło w błąd" często leży nie w technologii, ale w tym, jak świadomie z niej korzystasz.
Przeczytaj też:
Podoba Ci się ten artykuł?
Co piątek wysyłam podsumowanie najlepszych artykułów tygodnia. Zapisz się!
90 minut praktycznej wiedzy o AI. Pokaze Ci krok po kroku, jak zaczac oszczedzac 10 godzin tygodniowo dzieki sztucznej inteligencji.
Zapisz sie na webinar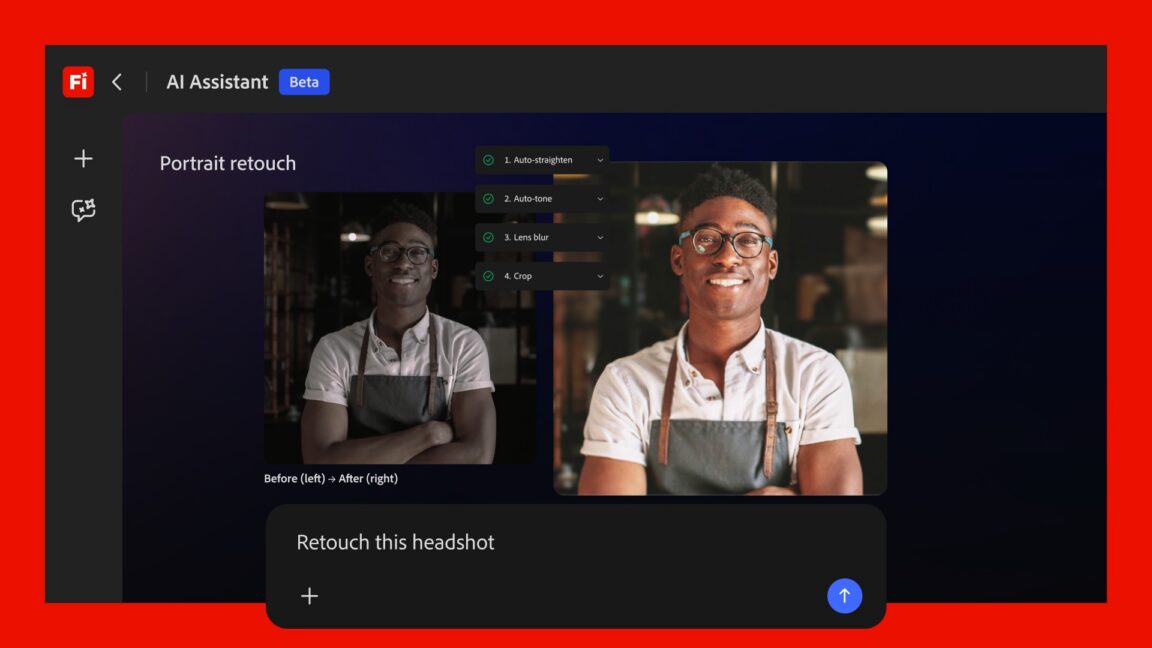
Adobe wprowadza do Creative Cloud funkcje znane z Claude Code. To nie kolejny update – to zmiana kierunku, w którym firma podąża od lat.

Adobe wprowadza asystenta AI, który samodzielnie obsługuje aplikacje Creative Cloud. Firefly dostał nową funkcję – wykonuje zadania w Photoshopie, Premiere i innych narzędziach.

Pierwszy model AI przeszedł wieloetapowy test infiltracji. Brytyjski rząd sprawdza, czy zagrożenie cybernetyczne ze strony AI to fakt, czy marketing.
