Poradniki
·
9 min czytania
·
23 kwietnia 2026
Jak działa uczenie ze wzmocnieniem w dużych modelach językowych

Źródło: Link
Źródło: Link
118 lekcji bez kodowania. ChatGPT, Claude, Gemini, automatyzacje. Notatnik AI i AI Coach w cenie.
Ktoś kiedyś powiedział, że AI uczy się jak dziecko. Nie do końca prawda. Dziecko uczy się metodą prób i błędów przez lata. Model językowy robi to samo w kilka tygodni - i potrzebuje do tego mechanizmu, który nazywamy reinforcement learning. To właśnie on sprawia, że ChatGPT odpowiada Ci jak partner rozmowy, a nie jak generator losowych słów.
Reinforcement learning (uczenie ze wzmocnieniem) to metoda trenowania AI, w której model uczy się przez system nagród i kar. Masz model językowy, który właśnie nauczył się przewidywać następne słowo w zdaniu. Wie, że po "Warszawa to" powinno być "stolica". To nie znaczy, że umie prowadzić sensowną rozmowę.
Tu wchodzi RL. Zamiast uczyć model "tak brzmi poprawne zdanie", uczysz go "tak brzmi pomocna, bezpieczna i użyteczna odpowiedź". Różnica? Pierwsza metoda daje Ci encyklopedię. Druga - asystenta.
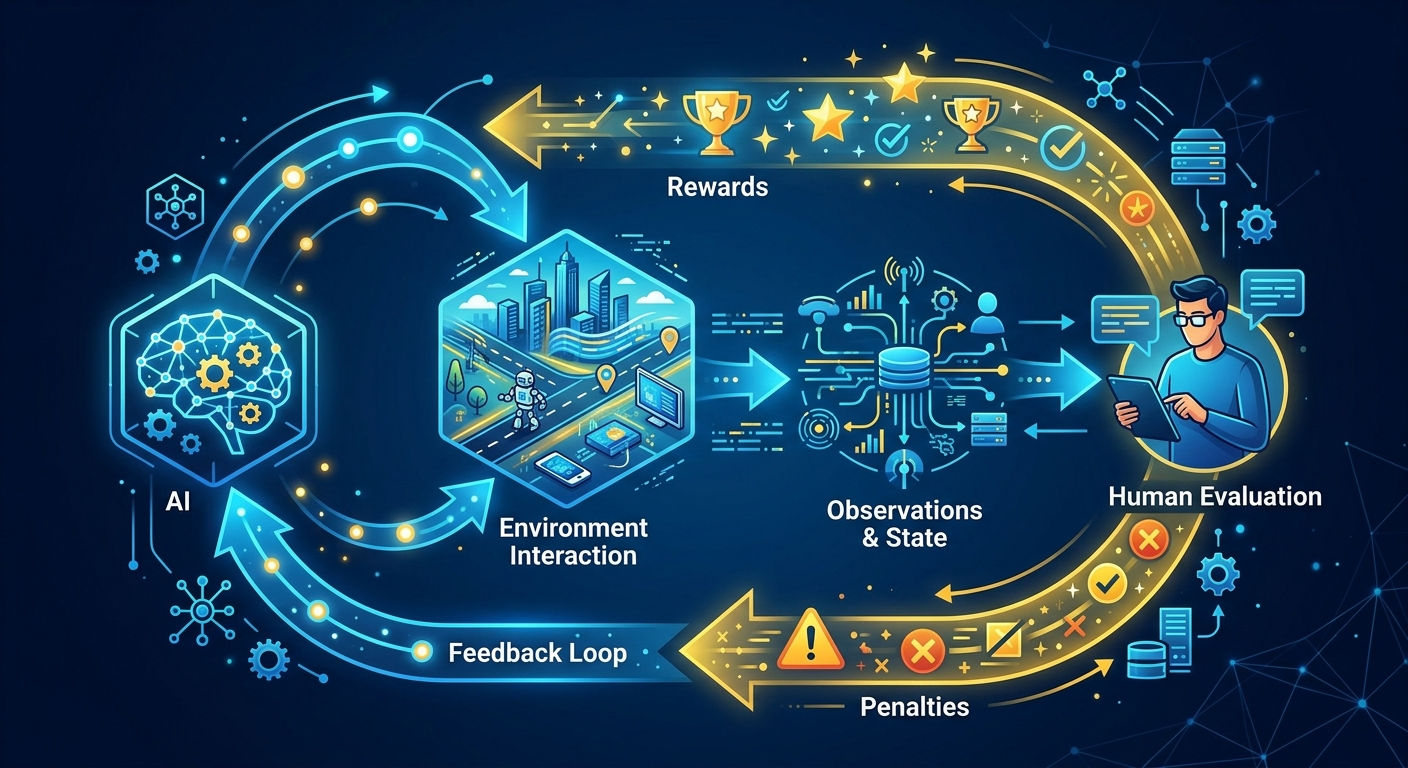
Proces wygląda tak: model generuje odpowiedź na pytanie. Człowiek (lub inny model) ocenia tę odpowiedź - czy była pomocna? Bezpieczna? Na temat? Na podstawie tej oceny model dostaje "nagrodę" (sygnał, że zrobił dobrze) lub "karę" (sygnał, że trzeba poprawić). Po tysiącach takich iteracji model zaczyna generować odpowiedzi, które częściej dostają wysokie oceny.
Konkretny przykład. Pytasz model: "Jak ugotować jajko na twardo?". Model bez RL może odpowiedzieć: "Jajko to produkt spożywczy pochodzący od kur domowych, zawierający białko i żółtko". Technicznie poprawne. Kompletnie bezużyteczne. Model z RL odpowie: "Włóż jajko do garnka z zimną wodą, zagotuj, gotuj 10 minut, ostudź pod zimną wodą". Różnica? Zrozumienie kontekstu pytania.
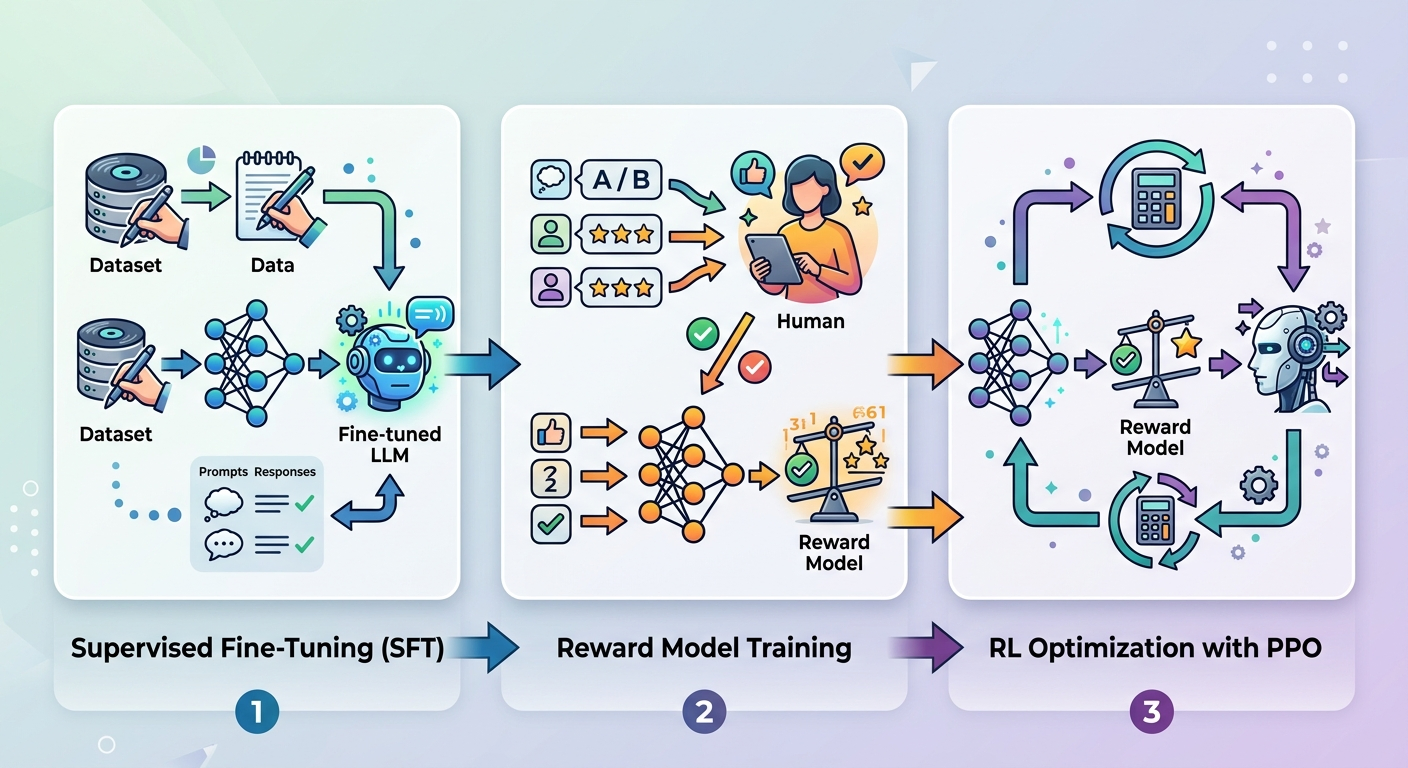
RLHF (Reinforcement Learning from Human Feedback) to wariant RL, w którym oceny wystawiają ludzie, nie algorytmy. To właśnie ta metoda stoi za sukcesem ChatGPT i innych dużych modeli językowych.
Proces RLHF składa się z trzech kroków:
Dlaczego to działa? Człowiek ocenia nie tylko poprawność faktyczną, ale też ton, użyteczność, bezpieczeństwo. Algorytm sam tego nie wyłapie. Człowiek wie, że odpowiedź "Zrób to sam" jest technicznie poprawna, ale nieprzyjazna. Model uczy się tej subtelności.
Bez RLHF ChatGPT byłby narzędziem dla programistów i badaczy. Z RLHF stał się narzędziem dla Ciebie - osoby, która chce napisać email, przygotować prezentację, zrozumieć skomplikowany temat. Model nauczył się, że:
To nie są rzeczy, których model nauczyłby się z samych danych tekstowych. To efekt tysięcy ocen ludzkich trenerów.
Reinforcement learning ma ograniczenia. Model uczy się maksymalizować nagrodę - jeśli źle zdefiniujesz, co jest nagrodą, dostaniesz nieoczekiwane rezultaty.
Przykład z życia: wczesne wersje modeli z RL miały tendencję do generowania bardzo długich, rozwlekłych odpowiedzi. Dlaczego? Ludzie oceniający je interpretowali długość jako "szczegółowość" i dawali wyższe oceny. Model nauczył się: długa odpowiedź = wysoka ocena. Nie nauczył się: użyteczna odpowiedź = wysoka ocena.
Kolejny problem: model uczy się na podstawie preferencji ludzi, którzy go trenują. Jeśli ci ludzie mają określone uprzedzenia, model je przejmie. Dlatego bezpieczeństwo AI to nie tylko kwestia technologii, ale też różnorodności zespołów trenujących.
RL nie nauczy modelu faktów, których nie ma w danych treningowych. Jeśli pytasz o wydarzenie z wczoraj, a model był trenowany na danych sprzed roku, RL nie pomoże. Model może nauczyć się mówić "nie wiem" zamiast wymyślać - to wszystko.
Dlatego nowoczesne systemy AI łączą RL z innymi metodami - fine-tuningiem na nowych danych, retrieval-augmented generation (RAG), który pozwala modelowi sięgać po aktualne informacje z baz danych.

Wiedza o tym, jak działa RL, zmienia sposób, w jaki korzystasz z dużych modeli językowych. Kilka praktycznych wniosków:
Dawaj feedback. Jeśli ChatGPT lub Claude pozwala Ci ocenić odpowiedź (thumbs up/down), rób to. Te oceny trafiają do kolejnych rund treningu. Im więcej ludzi ocenia odpowiedzi, tym lepszy model w następnej wersji.
Pytaj precyzyjnie. Model nauczył się przez RL rozpoznawać intencje - im jaśniej je wyrażasz, tym lepiej. Zamiast "Napisz coś o AI" napisz "Napisz 3 akapity o zastosowaniu AI w marketingu dla małej firmy". Model dostanie jasny sygnał, czego oczekujesz.
Testuj różne prompty. RL sprawia, że model reaguje na niuanse w pytaniu. "Wyjaśnij mi" może dać inną odpowiedź niż "Podsumuj". Eksperymentuj - różne sformułowania mogą dać lepsze rezultaty.
Pamiętaj o kontekście. Model trenowany przez RLHF nauczył się śledzić wątek rozmowy. Nie musisz powtarzać wszystkiego w każdym pytaniu. Możesz budować na poprzednich odpowiedziach - to jedna z rzeczy, których model nauczył się przez RL.
Reinforcement learning to nie koniec drogi, to punkt wyjścia. Obecne badania koncentrują się na kilku kierunkach:
Constitutional AI - metoda Anthropic (twórców Claude), w której model uczy się nie tylko od ludzi, ale też od zestawu zasad ("konstytucji"). Model sam ocenia swoje odpowiedzi pod kątem zgodności z tymi zasadami. Mniej zależności od ludzkich trenerów, bardziej skalowalne.
Multi-objective RL - zamiast jednej metryki ("czy odpowiedź jest dobra") model uczy się balansować wiele celów: użyteczność, bezpieczeństwo, zwięzłość, kreatywność. Trudniejsze technicznie, bliższe temu, jak ludzie oceniają jakość rozmowy.
RL w agentach AI - modele, które nie tylko odpowiadają na pytania, ale wykonują zadania (piszą kod, analizują dane, planują projekty). Tu RL uczy model nie tylko "jak mówić", ale "jak działać". Agenci AI to kolejny poziom złożoności.
Za rok, dwa lata modele językowe będą jeszcze lepsze w rozumieniu kontekstu, intencji, niuansów. Nie chodzi o to, że będą większe (choć mogą być) - dlatego, że metody RL będą bardziej zaawansowane. To właśnie warto obserwować: nie tylko nowe modele, ale nowe sposoby ich trenowania.
Teoretycznie tak, praktycznie - nie bez poważnych zasobów. RLHF wymaga tysięcy ocen ludzkich, mocy obliczeniowej GPU i czasu. Małe firmy raczej korzystają z gotowych modeli (ChatGPT, Claude) lub robią fine-tuning na mniejszą skalę. RL to domena dużych laboratoriów AI.
RLHF uczy model "jak mówić", nie "co jest prawdą". Model może nauczyć się brzmieć pewnie, nawet gdy nie ma pewności co do faktów. To problem zwany "halucynacjami" - model generuje tekst, który brzmi wiarygodnie, ale jest nieprawdziwy. RLHF redukuje to zjawisko (model uczy się mówić "nie wiem"), ale go nie eliminuje. Dlatego zawsze weryfikuj fakty, zwłaszcza w krytycznych zastosowaniach.
Nie. RL to jedno z narzędzi w zestawie. Duże modele językowe powstają w kilku etapach: pre-training (uczenie na ogromnych zbiorach tekstu), supervised fine-tuning (uczenie na przykładach), RLHF (dostrajanie przez feedback). Każdy etap ma swoją rolę. RL bez solidnego pre-trainingu da Ci model, który umie rozmawiać, ale nie ma o czym. Pre-training bez RL da Ci encyklopedię bez kontaktu z rzeczywistością. Potrzebujesz obu.
Zależy od skali. Dla modelu wielkości GPT-5 - tygodnie do miesięcy, z użyciem setek GPU. Dla mniejszego modelu - dni. To tylko czas obliczeń. Zbieranie ocen ludzkich może trwać dłużej - potrzebujesz tysięcy przykładów, a ludzie oceniają je ręcznie. Dlatego firmy takie jak OpenAI i Anthropic zatrudniają setki trenerów AI.
Pośrednio - tak. Oceniając odpowiedzi w ChatGPT (thumbs up/down), dajesz sygnał, który może trafić do kolejnych rund treningu. Bezpośrednio - raczej nie, chyba że pracujesz w firmie AI lub masz dostęp do API z możliwością fine-tuningu. Każda ocena ma znaczenie - to właśnie z takich małych sygnałów model uczy się, co jest dobre, a co nie.
Ten poradnik to dopiero początek. W naszym kursie "Praktyczna AI" nauczysz się korzystać z ChatGPT, Claude i innych narzędzi AI w sposób systematyczny - od zera do zaawansowanego poziomu.
Sprawdź kurs →Reinforcement learning to metoda, która zamienia model językowy z generatora tekstu w partnera rozmowy. RLHF (uczenie przez feedback ludzki) sprawia, że ChatGPT rozumie nie tylko słowa, ale intencje, kontekst, niuanse. To nie magia - to tysiące ocen, miliony iteracji, tygodnie obliczeń.
Ograniczenia? Są. Model uczy się od ludzi, więc przejmuje ich uprzedzenia. Optymalizuje pod metrykę, więc może "hakować" system nagród. Nie uczy się nowych faktów, tylko jak o nich mówić. Mimo to RL zmienił AI z narzędzia dla specjalistów w narzędzie dla Ciebie.
Następnym razem, gdy ChatGPT lub Claude da Ci dobrą odpowiedź, kliknij thumbs up. Gdy da słabą - thumbs down. To nie tylko guzik. To sygnał, który trafi do kolejnej rundy treningu. Tak, małymi krokami, pomagasz AI stawać się lepszym.
Na podstawie: SukcesAI Course Material Generator
Podoba Ci się ten artykuł?
Co piątek wysyłam podsumowanie najlepszych artykułów tygodnia. Zapisz się!
90 minut praktycznej wiedzy o AI. Pokaze Ci krok po kroku, jak zaczac oszczedzac 10 godzin tygodniowo dzieki sztucznej inteligencji.
Zapisz sie na webinar
Chcesz nauczyć się LLM, ale gubisz się w ofertach kursów? Pokazuję, jak znaleźć wartościowe materiały edukacyjne i uniknąć pułapek marketingowych.

Uczenie przez wzmacnianie sprawia, że ChatGPT rozumie kontekst, a nie tylko składa słowa. Wyjaśniamy krok po kroku, jak to działa i dlaczego ma znaczenie.
![Claude AI po polsku - kompletny przewodnik [2026]](https://sukcesai.com/uploads/images/imagen-1779630508914.webp)
Claude od Anthropic to drugi największy model AI po ChatGPT, ale w Polsce jeszcze nie wszyscy ogarniają, jak go używać. Tu masz wszystko - bez technicznego bełkotu, z konkretami które działają od...

ChatGPT przestał odpowiadać w połowie zdania. Albo w ogóle nie wchodzi. Kawa stygnie, deadline za 30 minut, a Ty wpatrujesz się w kręcące się kółko ładowania. Znam to. Byłem tam. I wiem, że w...

Claude i ChatGPT to dwa najpopularniejsze chatboty AI. Sprawdź, który wybrać do pisania, kodowania, analizy danych i codziennej pracy - z konkretnymi przykładami użycia.

Transformery to silnik każdego dużego modelu językowego. Wyjaśniamy prostym językiem, jak GPT-5, Claude Opus 4.7 czy DeepSeek V4-Pro rozumieją kontekst i generują odpowiedzi.
