Narzedzia AI
·
6 min czytania
·
4 maja 2026
TPU Google przyspiesza LLM-y 3x. Jak to działa?

Źródło: Link
Źródło: Link
118 lekcji bez kodowania. ChatGPT, Claude, Gemini, automatyzacje. Notatnik AI i AI Coach w cenie.
Modele językowe generują tekst powoli. Token po tokenie, słowo po słowie - standardowa autoregresja wymaga osobnego przejścia przez sieć dla każdego kolejnego tokenu. Im dłuższa odpowiedź, tym więcej czasu. Badacze z University of California San Diego postanowili to zmienić.
Wdrożyli na TPU Google metodę DFlash - dekodowanie spekulatywne w stylu dyfuzyjnym. Zamiast przewidywać tokeny sekwencyjnie, system generuje całe bloki kandydatów jednocześnie. Rezultat? Trzykrotne przyspieszenie inferencji względem klasycznego podejścia.
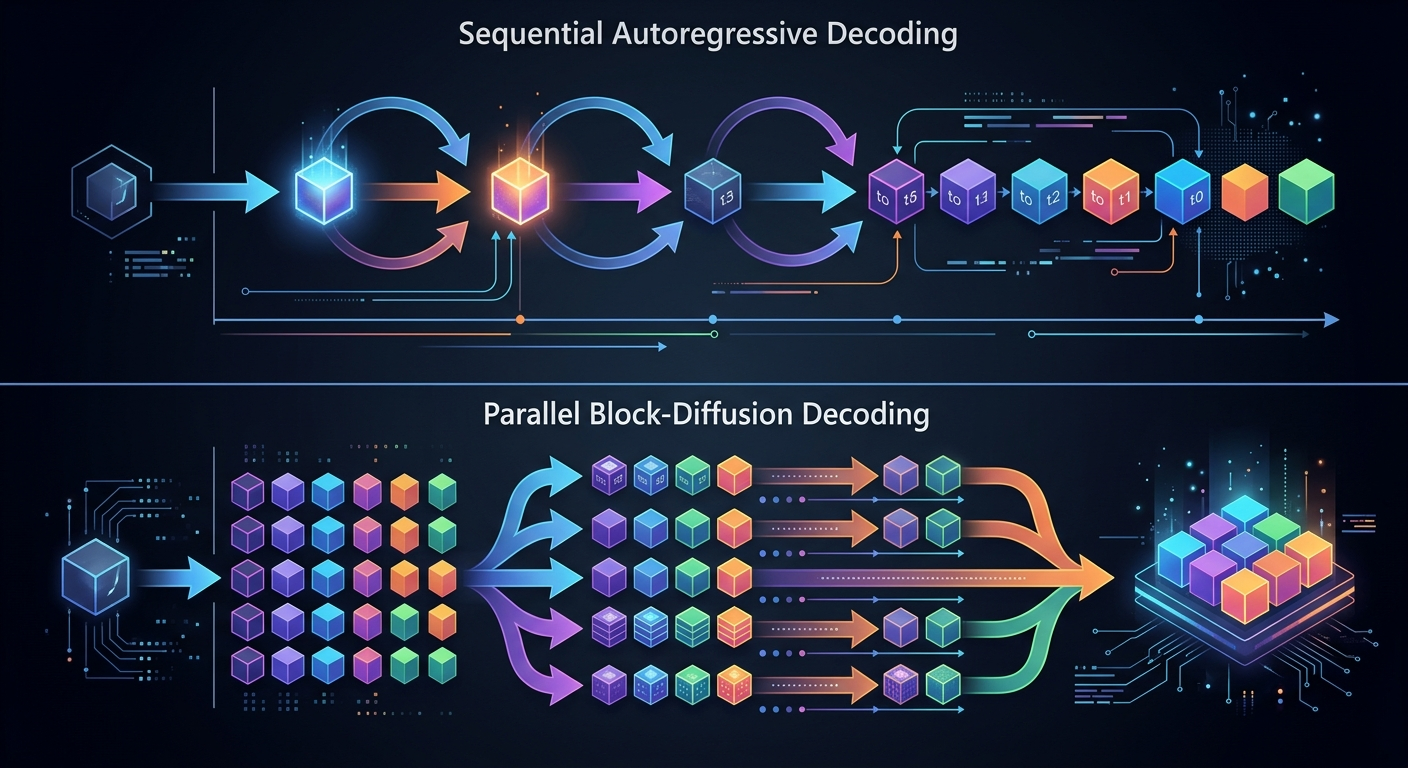
Standardowe modele językowe działają jak pisarz, który musi zobaczyć poprzednie słowo, zanim napisze kolejne. Autoregresja to sekwencja: token 1 → token 2 → token 3. Każdy krok wymaga osobnego wywołania modelu. Przy długich odpowiedziach (kilkaset tokenów) to się sumuje.
Dekodowanie spekulatywne zmienia zasady. Zamiast czekać na każdy token, system generuje kilka kandydatów jednocześnie - spekuluje, co może być dalej. Potem weryfikuje je dużym modelem. Jeśli kandydaci są poprawni, oszczędzasz czas. Jeśli nie - odrzucasz i próbujesz ponownie.
Problem tradycyjnego podejścia? Drafting (generowanie kandydatów) też jest sekwencyjny. Mały model musi przewidzieć token 1, potem token 2, potem token 3. Wąskie gardło pozostaje.
DFlash rozwiązuje to inaczej. Zamiast przewidywać tokeny po kolei, „maluje” całe bloki jednocześnie - stąd nazwa „block-diffusion”. Cały blok kandydatów powstaje w jednym przejściu przez sieć. To eliminuje sekwencyjne opóźnienia na etapie draftingu.
Standardowa autoregresja: napisz pierwsze słowo, zobacz je, napisz drugie, zobacz je, napisz trzecie. DFlash: naszkicuj cały fragment jednocześnie, sprawdź go, popraw co trzeba, idź dalej.
Technicznie: model generuje blok N tokenów w jednym forward pass. Duży model weryfikuje cały blok. Jeśli większość tokenów jest poprawna, system zaakceptuje je i przejdzie dalej. Jeśli nie - odrzuci błędne i wygeneruje nowe kandydaty.
Kluczowa różnica względem klasycznego dekodowania spekulatywnego: drafting nie jest już sekwencyjny. Cały blok powstaje równolegle. To właśnie daje przyspieszenie 3x.
Implementacja na TPU Google nie jest przypadkowa. Te akceleratory są zoptymalizowane pod operacje macierzowe - dokładnie to, czego wymaga równoległe generowanie tokenów.
CPU i GPU też potrafią równoległość, ale TPU mają architekturę zaprojektowaną specjalnie pod transformery. Operacje attention, mnożenie macierzy, przepływ danych - wszystko jest dostrojone pod modele językowe. DFlash wykorzystuje to w pełni.
Badacze z UCSD pokazali, że metoda działa na produkcyjnym sprzęcie Google. Nie jest to eksperyment laboratoryjny - to implementacja, którą można wdrożyć w rzeczywistych systemach.
Trzykrotne przyspieszenie to konkretna różnica. Jeśli standardowa inferencja zajmuje 3 sekundy, DFlash skraca to do 1 sekundy. Przy tysiącach zapytań dziennie to zmiana, która wpływa na koszty i doświadczenie użytkownika.
Inferencja LLM-ów kosztuje. Każdy token to obliczenia, każde obliczenie to energia i czas procesora. Jeśli przyspieszysz generowanie 3x, możesz obsłużyć 3x więcej zapytań na tym samym sprzęcie. Albo zredukować infrastrukturę o dwie trzecie.
Dla firm używających API modeli językowych to może nie mieć bezpośredniego przełożenia (płacisz za token, nie za czas). Ale dla tych, którzy hostują własne modele - różnica jest realna.
Google Cloud oferuje TPU jako usługę. Jeśli DFlash stanie się standardem, możesz spodziewać się niższych kosztów inferencji albo wyższej przepustowości za tę samą cenę.

Badacze z UCSD opublikowali wyniki na blogu Google Developers. To sygnał, że technologia jest na etapie, gdzie Google rozważa wdrożenie. Trzykrotne przyspieszenie to argument, którego trudno zignorować.
Dla Ciebie jako użytkownika API (czy to Google, OpenAI, Anthropic) to może oznaczać szybsze odpowiedzi w aplikacjach opartych na LLM-ach. Chatboty, agenci AI, systemy analizy tekstu - wszystko, co dziś czeka sekundę na odpowiedź, może działać w 300 milisekund.
Jeśli hostrujesz własne modele (np. open-source DeepSeek czy Llama), implementacja DFlash będzie wymagała dostępu do TPU albo portowania na GPU. Kod badaczy jest dostępny, ale to nie jest plug-and-play - potrzebujesz infrastruktury i wiedzy technicznej.
Dekodowanie spekulatywne to jeden z kierunków optymalizacji inferencji. Inne metody to kwantyzacja (zmniejszanie precyzji obliczeń), pruning (usuwanie zbędnych parametrów), destylacja (tworzenie mniejszych modeli). DFlash pokazuje, że można przyspieszyć nie model, ale sposób jego działania.
Jeśli równoległe generowanie bloków stanie się standardem, możemy zobaczyć kolejne iteracje tej techniki. Większe bloki, lepsza weryfikacja, adaptacyjna długość - to naturalne kierunki rozwoju.
Dla branży AI to sygnał, że inferencja nie musi być wąskim gardłem. Modele rosną, ale metody ich uruchamiania też ewoluują. Trzykrotne przyspieszenie dzisiaj może być pięciokrotnym za rok.
Ten artykuł pokazuje jedną technikę optymalizacji. W kursie AI Evolution rozkładam na czynniki pierwsze, jak LLM-y generują tekst, czym jest autoregresja, jak działa attention - i jak to wszystko wykorzystać w praktyce. Od podstaw do zaawansowanych zastosowań, bez matematyki na poziomie PhD.
Sprawdź AI Evolution →Badacze z UCSD wdrożyli metodę na TPU, ale sama technika nie jest ograniczona do tego sprzętu. Można ją zaportować na GPU (NVIDIA, AMD) albo inne akceleratory AI. TPU dają najlepsze wyniki ze względu na architekturę zoptymalizowaną pod transformery, ale nie są jedyną opcją.
Nie. Efektywność dekodowania spekulatywnego zależy od tego, jak dobrze drafting przewiduje tokeny. Jeśli model generuje przewidywalny tekst (np. kod, dokumentacja), przyspieszenie może być większe. Jeśli tekst jest kreatywny i nieprzewidywalny, zysk będzie mniejszy. 3x to średnia z testów badaczy - Twoje wyniki mogą się różnić.
Nie bezpośrednio. DFlash to metoda inferencji, którą stosuje się po stronie serwera. Jeśli OpenAI, Anthropic czy Google wdrożą ją w swoich systemach, zobaczysz efekt jako szybsze odpowiedzi - ale nie masz kontroli nad tym, jak API działa wewnętrznie. Jeśli hostrujesz własny model, możesz zaimplementować DFlash samodzielnie (wymaga to dostępu do kodu i infrastruktury).
Nie powinien. Dekodowanie spekulatywne generuje kandydatów, ale duży model weryfikuje je przed zaakceptowaniem. Jeśli token jest błędny, zostaje odrzucony. Końcowy wynik powinien być identyczny jak przy standardowej autoregresji - zmienia się tylko sposób dojścia do niego. W praktyce mogą wystąpić minimalne różnice numeryczne (zaokrąglenia, losowość), ale nie powinny wpływać na użyteczność tekstu.
Na podstawie: Google Developers Blog
Podoba Ci się ten artykuł?
Co piątek wysyłam podsumowanie najlepszych artykułów tygodnia. Zapisz się!
90 minut praktycznej wiedzy o AI. Pokaze Ci krok po kroku, jak zaczac oszczedzac 10 godzin tygodniowo dzieki sztucznej inteligencji.
Zapisz sie na webinar
Integracja Arm SME2 z Google AI Edge zamienia procesor w potężny akcelerator macierzowy. Stability AI pokazuje, jak uruchomić generatywne audio na zwykłym CPU.

Fast tokenizery mogą przyspieszyć pipeline RAG nawet 10-krotnie. Sprawdź, jak działają, kiedy mają sens i jak je wdrożyć krok po kroku.

Sąd w Monachium orzekł, że Google musi odpowiadać za fałszywe treści generowane przez AI Overview. Wyrok może zmienić całą branżę wyszukiwarek AI.

Apple Intelligence działa na infrastrukturze Google z chipami Nvidia. Jak firma z Cupertino chce pogodzić obietnice prywatności z chmurą konkurencji?

Qwen dostaje ekosystem zewnętrznych agentów i umiejętności. Tencent pracuje nad AI w WeChat. Chińskie firmy stawiają na platformy, nie pojedyncze narzędzia.

LINKER Technology pokazał OttoBox - asystenta AI, który przetwarza materiały lokalnie i znajduje klip w 10 sekund zamiast 30 minut. Pierwsze wdrożenia skracają cykl produkcji o 80%.
