Narzedzia AI
·
6 min czytania
·
14 maja 2026
Arm SME2 i Google AI Edge - CPU jako akcelerator AI

Źródło: Link
Źródło: Link
90 minut praktyki na żywo. Pokazuję krok po kroku, jak zacząć z AI bez kodowania.
"Integracja dedykowanej jednostki macierzowej bezpośrednio w klaster CPU eliminuje wybór między wolnym CPU a fragmentarycznymi akceleratorami" - cytat z oficjalnego wpisu Google Developers Blog. Brzmi korporacyjnie. Ale zobaczysz za moment, co to znaczy w praktyce.
Arm pokazało, że nie musisz wybierać między uniwersalnym procesorem a specjalistycznym układem AI. SME2 (Scalable Matrix Extension 2) to jednostka macierzowa wbudowana w CPU. Ta sama architektura, która do tej pory obsługiwała zwykłe obliczenia, teraz radzi sobie z generatywnym AI.
Arm SME2 to nie oddzielny chip. To rozszerzenie instrukcji procesora, które dodaje dedykowaną jednostkę do operacji macierzowych - tych samych, które dominują w modelach generatywnych. Google twierdzi, że daje to do 5x przyspieszenie w zadaniach inference.
Kluczowa różnica: nie potrzebujesz osobnego GPU ani NPU. CPU sam sobie radzi z obliczeniami AI, bo ma wbudowany akcelerator macierzowy. Dodajesz turbo do silnika, który już masz - nie wymieniasz całego auta.
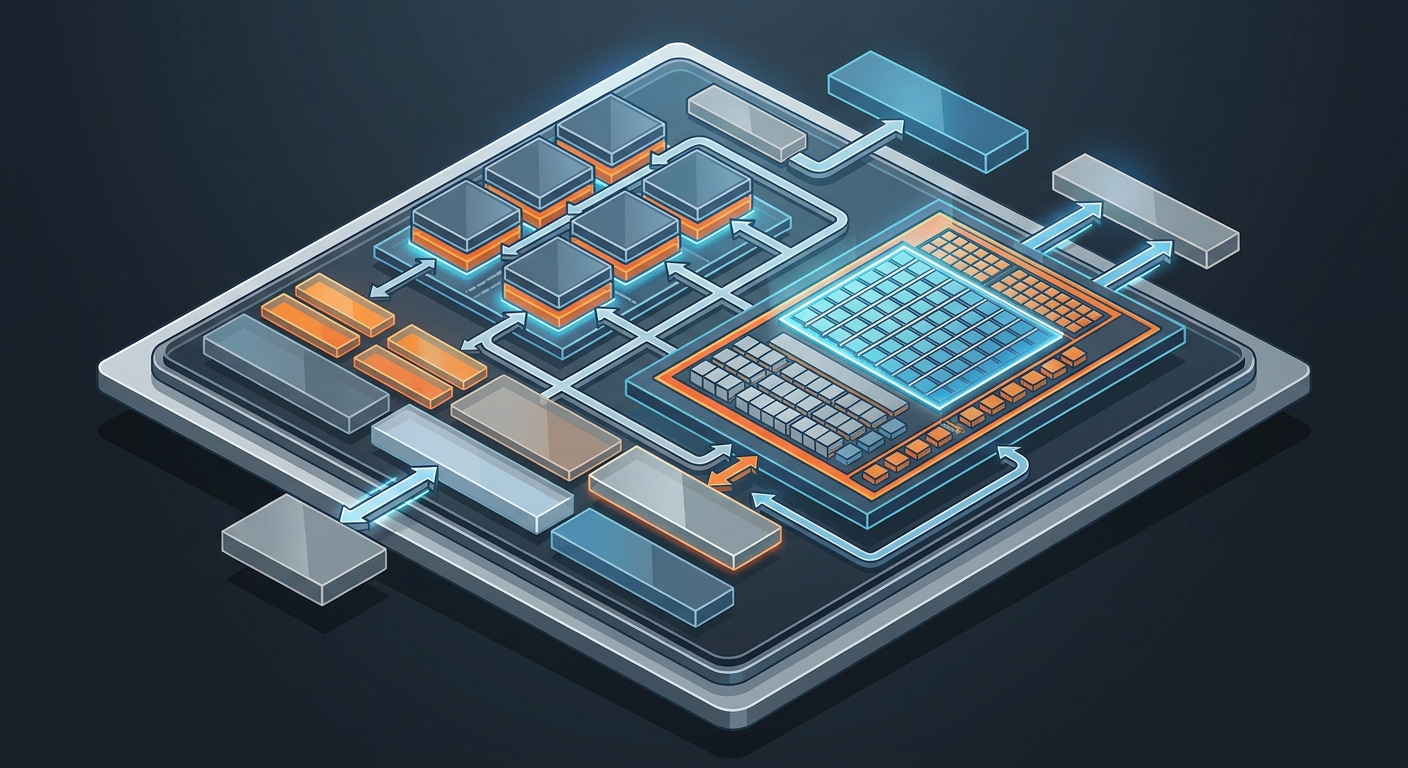
Google AI Edge to stos narzędziowy, który automatycznie wykrywa i wykorzystuje SME2. Składa się z trzech warstw:
Nie musisz ręcznie wybierać kerneli ani przepisywać kodu. LiteRT w runtime identyfikuje operacje iGeMM i GeMM (mnożenie macierzy) i automatycznie przekierowuje je do SME2. Masz Arm z SME2? Dostajesz przyspieszenie. Nie masz? Kod działa na standardowym CPU.
Stability AI wzięło swój model stable-audio-open-small (generowanie dźwięku z tekstu) i uruchomiło go w całości na Arm CPU. Oryginalny model to PyTorch w pełnej precyzji (FP32). Google pokazało, jak go skompresować do mixed-precision (FP16/Int8) i wdrożyć na urządzeniu brzegowym.
Proces optymalizacji:
Efekt? Model generujący audio działa na CPU bez dedykowanego układu AI. Google nie podaje konkretnych liczb wydajności w tym case study, ale podkreśla, że SME2 radzi sobie z "matrix-heavy workloads" - dokładnie tym, co dominuje w generatywnym AI.
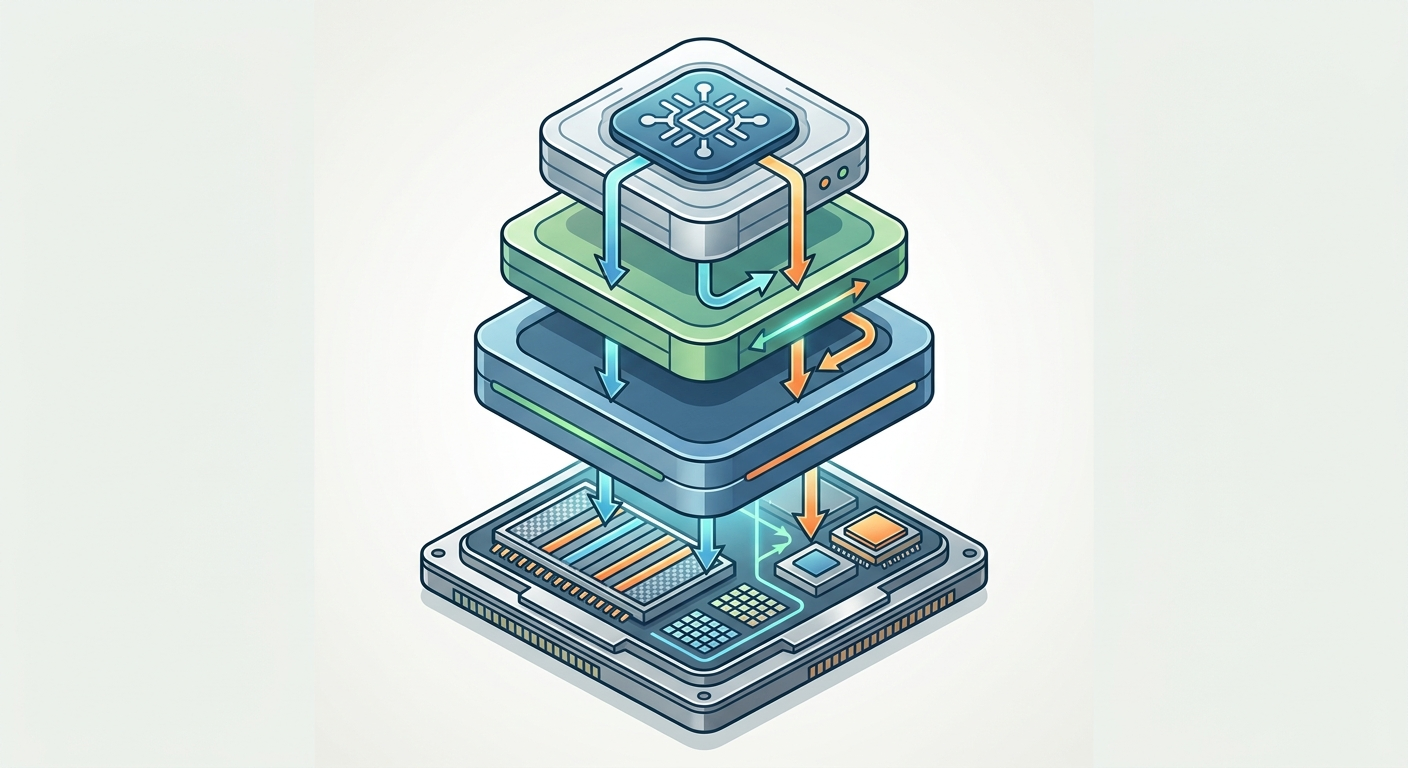
FP16/Int8 to nie tylko mniejszy rozmiar modelu. To też mniej operacji do wykonania - procesor przetwarza 16-bitowe liczby szybciej niż 32-bitowe. AI Edge Quantizer automatycznie kompresuje model, zachowując jakość wyników.
Model Explorer to debugger wydajności. Pokazuje graf obliczeniowy jako interaktywną mapę - widzisz, które warstwy zjadają najwięcej czasu. Jeśli bottleneck jest w operacji, którą SME2 może przyspieszyć - LiteRT automatycznie to robi.
Do tej pory AI na urządzeniach brzegowych (telefony, IoT, automotive) wymagało albo wolnego CPU, albo dedykowanego NPU/GPU. Arm SME2 daje trzecią opcję: CPU z wbudowanym akceleratorem macierzowym.
Zalety tego podejścia:
Wady:
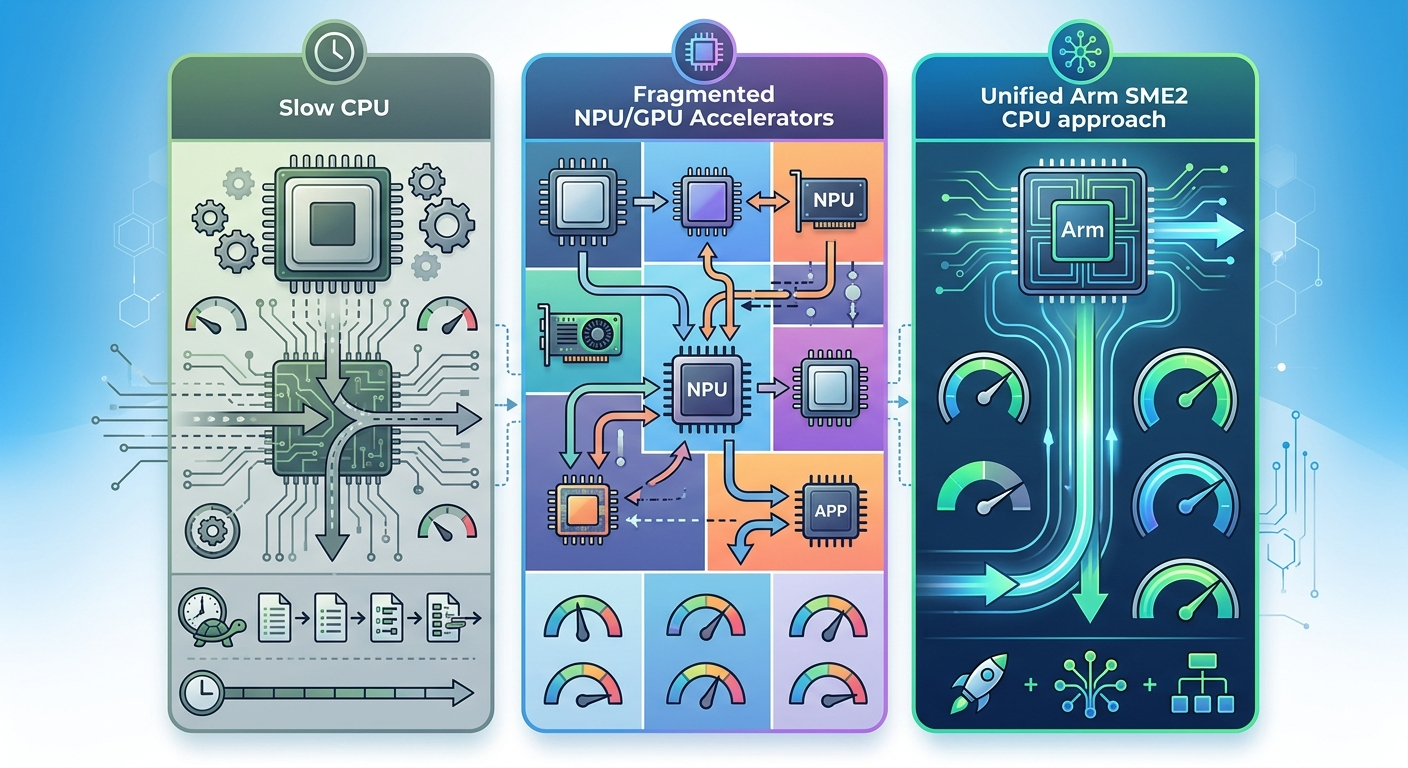
Google AI Edge (LiteRT, XNNPACK, Model Explorer) to narzędzia open-source dostępne globalnie. Arm SME2 to kwestia sprzętu - jeśli masz procesor Arm z tym rozszerzeniem (np. w najnowszych smartfonach), dostajesz przyspieszenie automatycznie.
Dla polskich deweloperów: możesz budować aplikacje AI na urządzenia brzegowe bez targetowania konkretnych akceleratorów. LiteRT wykryje dostępny sprzęt i użyje najszybszej ścieżki - SME2, jeśli jest, standardowy CPU, jeśli nie.
Arm SME2 + Google AI Edge to dobre rozwiązanie, jeśli:
To NIE jest dobre rozwiązanie, jeśli:
Google nie pokazało porównania SME2 z dedykowanymi akceleratorami. "Do 5x szybciej" to porównanie do standardowego CPU, nie do NPU. Jeśli masz wybór między Arm CPU z SME2 a dedykowanym układem AI - prawdopodobnie NPU wygra w czystej wydajności.
Jeśli budujesz aplikację, która ma działać na różnych urządzeniach (Android, Linux IoT, automotive) - SME2 daje Ci uniwersalne przyspieszenie bez pisania osobnego kodu pod każdy akcelerator. Kompromis między wydajnością a prostotą.
Nie. Google AI Edge (LiteRT, XNNPACK) działa na każdym procesorze Arm. SME2 to opcjonalne przyspieszenie - jeśli Twój CPU ma tę jednostkę, dostajesz automatyczny boost. Jeśli nie - kod działa na standardowym CPU, tylko wolniej.
Sprawdź specyfikację techniczną procesora na stronie producenta (np. Qualcomm, MediaTek). SME2 jest dostępne w najnowszych chipach Arm (od 2024-2025 roku). Starsze procesory (sprzed 2024) prawdopodobnie go nie mają.
Nie. Stable-audio-open-small to tylko przykład case study. Google AI Edge obsługuje dowolne modele PyTorch/TensorFlow skonwertowane do formatu LiteRT. Możesz użyć własnych modeli - AI Edge Quantizer skompresuje je, a LiteRT automatycznie wykorzysta dostępne przyspieszenie sprzętowe.
Tak. LiteRT (dawniej TensorFlow Lite) to standardowy runtime AI na Androidzie. Jeśli masz smartfon z procesorem Arm (większość urządzeń Android), możesz użyć Google AI Edge. Przyspieszenie SME2 dostaniesz tylko na najnowszych chipach.
Na podstawie: Google Developers Blog
Podoba Ci się ten artykuł?
Co piątek wysyłam podsumowanie najlepszych artykułów tygodnia. Zapisz się!
10 gotowych promptów do codziennej pracy + 5 narzędzi + plan na pierwszy tydzień. PDF, 4 strony konkretu.
90 minut praktycznej wiedzy o AI. Pokaze Ci krok po kroku, jak zaczac oszczedzac 10 godzin tygodniowo dzieki sztucznej inteligencji.
Zapisz sie na webinarReprezentujesz firme? Zobacz wdrozenia AI dla firm →

Google po sześciu latach wypuściło nowy głośnik smart home. Wygląda świetnie, brzmi dobrze. Problem? Gemini for Home nie dorósł do sprzętu.

Managed Agents w Gemini API dostają background execution, zdalne serwery MCP i niestandardowe funkcje. Google celuje w produkcyjne wdrożenia agentów AI.
Nowa reklama Google Workspace wyobraża sobie, że twórcy Deklaracji Niepodległości używali Gemini. Reakcje? Od cringe'u po gniew. Sprawdzamy, dlaczego.

Sąd w Monachium orzekł, że Google musi odpowiadać za fałszywe treści generowane przez AI Overview. Wyrok może zmienić całą branżę wyszukiwarek AI.

Apple Intelligence działa na infrastrukturze Google z chipami Nvidia. Jak firma z Cupertino chce pogodzić obietnice prywatności z chmurą konkurencji?

Google wypuszcza Nano Banana 2 Lite - model generujący obrazy w 4 sekundy. Jakość niższa, cena śmiesznie niska. Kiedy ma to sens, a kiedy lepiej dopłacić?
