Poradniki
·
8 min czytania
·
24 kwietnia 2026
Jak nauczyć sieć neuronową pisać teksty - przewodnik RNN

Źródło: Link
Źródło: Link
118 lekcji bez kodowania. ChatGPT, Claude, Gemini, automatyzacje. Notatnik AI i AI Coach w cenie.
Jak nauczyć komputer pisać jak Szekspir, generować kod Pythona albo tworzyć opisy obrazków - wszystko znak po znaku? W 2015 roku Andrej Karpathy pokazał, że wystarczy odpowiednia architektura sieci neuronowej i trochę cierpliwości. Jego słynny wpis o sieciach rekurencyjnych (RNN) to punkt zwrotny w popularyzacji AI - moment, kiedy generowanie tekstu przestało być magią, a stało się czymś, co możesz zrozumieć i przetestować samodzielnie.
Dzisiaj mamy GPT-5, Claude Opus 4.6 i dziesiątki innych modeli, które piszą eseje w sekundę. Żeby zrozumieć, jak to wszystko działa - warto wrócić do fundamentów. Do sieci, która uczy się przewidywać następną literę. Do RNN.
Standardowe sieci neuronowe działają jak funkcja: dostajesz dane wejściowe (np. obraz kota), przetwarzasz je przez warstwy, zwracasz wynik ("to kot"). Problem? Taka sieć nie ma pamięci. Każdy input traktuje jak niezależne zdarzenie.
Sieci rekurencyjne (RNN - Recurrent Neural Networks) zmieniają tę zasadę. Zamiast przetwarzać dane jako pojedynczy blok, przetwarzają je krok po kroku - i każdy krok "pamięta" poprzednie. Dlatego świetnie radzą sobie z sekwencjami: tekstem, muzyką, danymi czasowymi.
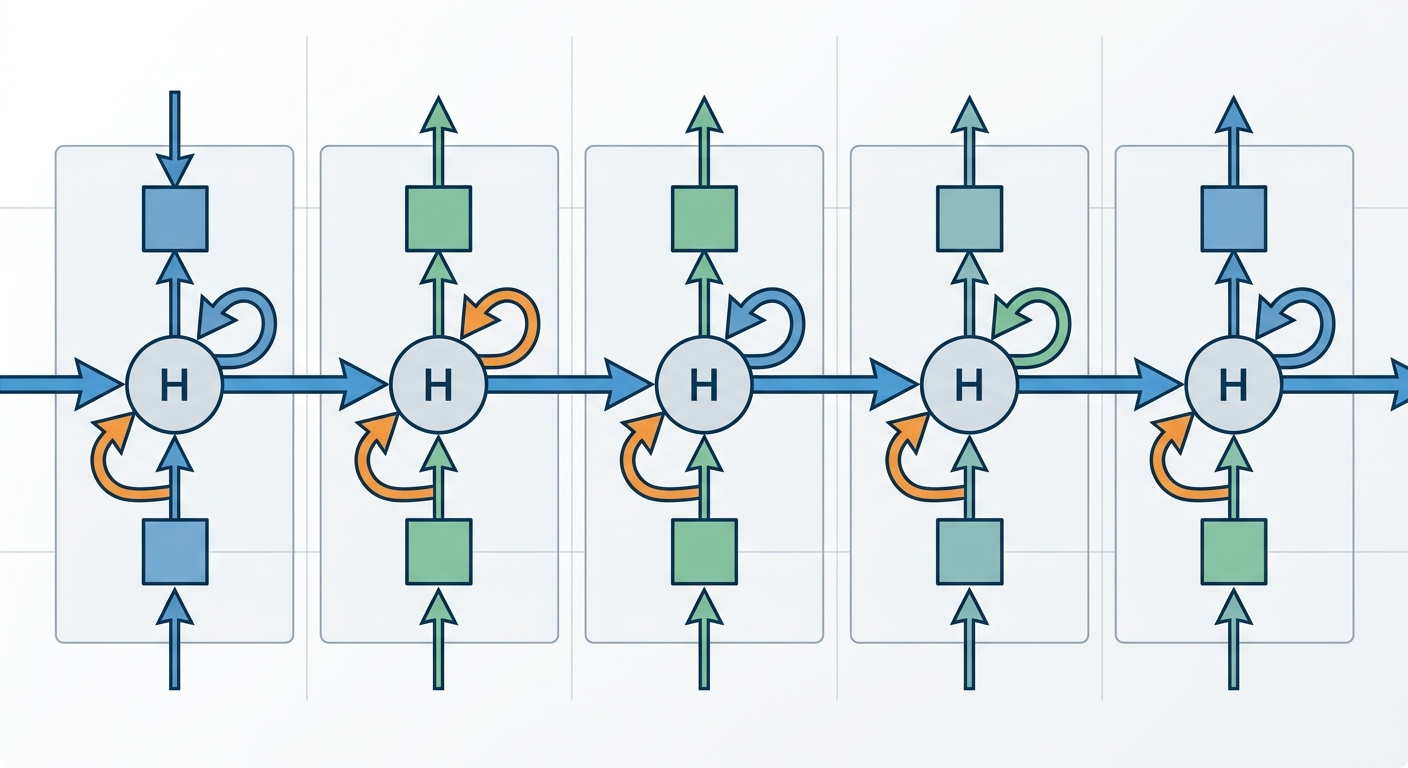
Karpathy w swoim eksperymencie nauczył RNN generować tekst znak po znaku. Sieć dostawała fragment tekstu (np. dzieła Szekspira), uczyła się przewidywać następną literę - i po kilkudziesięciu minutach treningu zaczynała tworzyć zdania, które brzmiały... niemal sensownie. Czasem lepiej, czasem gorzej. Zawsze fascynująco.
Dlaczego to było szokujące? Nikt nie programował reguł gramatyki. Nikt nie uczył sieci, czym jest słowo, zdanie czy akapit. Ona sama wywnioskowała te struktury z danych.
Karpathy przetestował swój model na kilku zestawach danych. Każdy pokazuje, jak sieć "rozumie" strukturę języka - albo kodu.
Sieć dostała kompletne dzieła Szekspira. Po treningu zaczęła generować dialogi, które wyglądały jak fragmenty sztuk teatralnych - z podziałem na role, kwestiami, nawet didaskaliami. Oczywiście treść była nonsensowna. Forma? Idealna.
Sieć nauczyła się struktury dramatu - nie czytając podręcznika, tylko analizując wzorce w tekście. Zrozumiała, że po "ROMEO:" następuje kwestia, że sceny mają nagłówki, że dialogi mają rytm.
LaTeX to język do składu dokumentów naukowych - pełen nawiasów, komend, zagnieżdżonych struktur. Karpathy wrzucił do sieci kilkaset stron kodu LaTeX-a. Po treningu model generował poprawne składniowo dokumenty - z sekcjami, równaniami, bibliografią.
Znowu: nikt nie uczył sieci składni LaTeX-a. Ona sama "odkryła", że komenda \begin{equation} musi mieć parę \end{equation}, że równania mają strukturę, że bibliografia ma swój format.
Najbardziej imponujący test: Karpathy wrzucił do sieci kod źródłowy jądra Linuxa. Po treningu model generował kod C, który wyglądał jak prawdziwy - z funkcjami, pętlami, komentarzami, nawet wcięciami.
Czy kod działał? Nie. Czy kompilował się? Rzadko. Struktura była poprawna - nawiasy się zgadzały, zmienne miały sens, funkcje miały logiczny układ. Sieć nauczyła się "pisać jak programista", nie rozumiejąc, co robi kod.
Przez lata panowało przekonanie, że sieci rekurencyjne to koszmar do wytrenowania. Problem nazywa się "vanishing gradient" - zanikający gradient. W skrócie: kiedy sieć przetwarza długą sekwencję, sygnał błędu z końca sekwencji zanika, zanim dotrze do początku. Sieć nie uczy się długoterminowych zależności.
Rozwiązanie? Architektura LSTM (Long Short-Term Memory) - wariant RNN z wbudowaną pamięcią długoterminową. LSTM ma "bramy", które kontrolują, co zapamiętać, a co zapomnieć. Dzięki temu radzi sobie z długimi sekwencjami.
Karpathy użył właśnie LSTM-ów w swoich eksperymentach. Okazało się, że trenowanie wcale nie jest trudne - wystarczy odpowiednia architektura i trochę danych. Po kilkudziesięciu minutach model zaczynał generować sensowne (strukturalnie) teksty.
Jeśli interesuje Cię, jak modele AI przechowują wiedzę w warstwach neuronowych, sprawdź jak duże modele językowe przechowują fakty - to naturalne rozwinięcie tematu RNN.
RNN w czystej formie to dziś rzadkość. Modele typu GPT używają architektury Transformer, która działa inaczej (równolegle, nie sekwencyjnie). RNN wciąż mają swoje miejsce:
Najważniejsza lekcja z eksperymentów Karpathy'ego to nie "użyj RNN". To "zrozum, jak sieci uczą się struktury". Ta sama zasada - uczenie się wzorców z danych, bez ręcznego programowania reguł - napędza wszystkie współczesne modele AI.
Karpathy udostępnił kod swojego eksperymentu na GitHubie (char-rnn). Możesz go uruchomić i nauczyć sieć generować tekst na własnych danych. Oto co potrzebujesz:
Proces wygląda tak: ładujesz dane, definiujesz architekturę sieci (ile warstw LSTM, jak duże), uruchamiasz trening. Po każdej epoce możesz sprawdzić, jak sieć generuje tekst - i obserwować, jak z chaosu wyłania się struktura.
Czy to praktyczne? Nie, jeśli chcesz po prostu generować tekst - do tego użyjesz GPT-5 albo Claude. Jeśli chcesz zrozumieć, jak AI uczy się języka - to najlepsza lekcja, jaką możesz sobie dać.
Jeśli wolisz gotowe narzędzia, sprawdź jak zbudować chatbota AI bez kodowania - tam pokażę Ci, jak stworzyć działającego asystenta bez pisania linijki kodu.
Dzisiaj mamy modele, które piszą eseje, analizują obrazy, generują kod - wszystko w sekundę. Po co więc wracać do RNN z 2015 roku?
Zrozumienie fundamentów zmienia sposób, w jaki używasz narzędzi. Kiedy wiesz, że model uczy się wzorców z danych (a nie "rozumie" tekst), inaczej formułujesz prompty. Kiedy rozumiesz, że sieć przewiduje następny token (nie "myśli"), lepiej interpretujesz jej odpowiedzi.
RNN nauczyły nas, że AI to nie magia - to matematyka, dane i optymalizacja. Że sieć może "odkryć" gramatykę Szekspira albo składnię C++, nie znając ani słowa angielskiego ani jednej linijki kodu. Że struktura wyłania się z chaosu, jeśli tylko masz dość przykładów.
Ta sama zasada napędza GPT-5, Claude Opus 4.6 i wszystkie inne modele. Zmieniła się architektura (Transformery zamiast RNN), skala (miliardy parametrów zamiast milionów), moc obliczeniowa. Podstawowa idea? Ta sama.
Jeśli chcesz zgłębić temat uczenia modeli AI, zobacz jak działa uczenie ze wzmocnieniem w dużych modelach językowych - to kolejny krok w zrozumieniu, jak AI się uczy.
Tak, w niszowych zastosowaniach - głównie analiza szeregów czasowych, przetwarzanie sygnałów audio, systemy kontroli. W generowaniu tekstu i tłumaczeniu maszynowym zostały wyparte przez Transformery (architektura GPT, Claude, Gemini). RNN są wolniejsze w treningu (bo przetwarzają dane sekwencyjnie, nie równolegle) i gorzej radzą sobie z długimi kontekstami. Wciąż mają swoje miejsce tam, gdzie sekwencyjność jest kluczowa.
RNN przetwarza tekst krok po kroku - każdy token zależy od poprzednich, sieć "patrzy" tylko na to, co już przetworzyła. GPT (Transformer) przetwarza cały kontekst równolegle - każdy token "widzi" wszystkie inne tokeny w oknie kontekstu. Dlatego Transformery są szybsze w treningu i lepiej radzą sobie z długimi tekstami. RNN miały problem z długoterminowymi zależnościami (vanishing gradient), Transformery ten problem rozwiązały mechanizmem uwagi (attention).
Oczywiście. RNN uczą się wzorców z danych - język nie ma znaczenia. Wystarczy, że dostarczysz polskojęzyczny korpus tekstów (np. polskie książki, artykuły, kod z polskimi komentarzami). Sieć nauczy się polskiej gramatyki, składni, nawet stylu - tak samo jak nauczyła się Szekspira. Problem? Polskiego jest mniej w internecie niż angielskiego, więc potrzebujesz solidnego zbioru danych treningowych (minimum kilka MB tekstu).
Ten poradnik to dopiero początek. W naszym kursie "Praktyczna AI" nauczysz się korzystać z ChatGPT, Claude i innych narzędzi AI w sposób systematyczny - od zera do zaawansowanego poziomu.
Sprawdź kurs →Sieci rekurencyjne pokazały, że AI może uczyć się struktury języka bez ręcznego programowania reguł. Wystarczy dostarczyć dane i pozwolić sieci "odkryć" wzorce. Generowanie tekstu znak po znaku to nie magia - to matematyka i optymalizacja.
Dzisiaj mamy lepsze narzędzia - Transformery dominują w generowaniu tekstu, tłumaczeniu, analizie. RNN to fundament, na którym zbudowano współczesne AI. Zrozumienie, jak działają, zmienia sposób, w jaki patrzysz na GPT-5, Claude czy Gemini.
Otwórz Google Colab, wklej kod char-rnn z GitHuba Karpathy'ego, wrzuć plik tekstowy z czymkolwiek (Twoje notatki, fragment książki, kod) i uruchom trening. Obserwuj, jak z chaosu wyłania się struktura. To najlepsza lekcja AI, jaką możesz sobie dać - bez slajdów, bez teorii, tylko Ty i sieć ucząca się pisać.
Podoba Ci się ten artykuł?
Co piątek wysyłam podsumowanie najlepszych artykułów tygodnia. Zapisz się!
90 minut praktycznej wiedzy o AI. Pokaze Ci krok po kroku, jak zaczac oszczedzac 10 godzin tygodniowo dzieki sztucznej inteligencji.
Zapisz sie na webinar
Konkretne zastosowania AI w content marketingu, SEO, social media, email marketingu i analityce. Praktyczny przewodnik bez buzzwordów.

Claude i ChatGPT to dwa najpopularniejsze chatboty AI. Sprawdź, który wybrać do pisania, kodowania, analizy danych i codziennej pracy - z konkretnymi przykładami użycia.

Generowanie postów, grafik i harmonogramów publikacji z pomocą AI. Konkretne narzędzia i praktyczne wskazówki dla osób, które chcą działać szybciej bez utraty jakości.

Sora, Runway Gen-3, Kling, Veo 2 - cztery narzędzia, cztery filozofie generowania wideo. Sprawdzamy, które pasuje do Twojego projektu i ile faktycznie zapłacisz.

Google Gemini to nie jedno narzędzie, tylko cały ekosystem. Zobacz, czym różnią się Flash, Pro, Studio i API oraz jak wybrać wersję do swojej pracy.

Instalacja, pierwsze komendy i praktyczny workflow z Claude Code. Sprawdź, jak AI asystent działa w terminalu i czym różni się od GitHub Copilot.
