Poradniki
·
13 min czytania
·
23 czerwca 2026
Jak wdrożyć continual learning w systemie AI - przewodnik

Źródło: Link
Źródło: Link
118 lekcji bez kodowania. ChatGPT, Claude, Gemini, automatyzacje. Notatnik AI i AI Coach w cenie.
Twój model AI działa świetnie. Przez tydzień. Może miesiąc. A potem dostajesz pierwszą wiadomość od użytkownika: "coś tu nie gra". Potem drugą. Trzecią. I nagle okazuje się, że model, który miał działać sam, wymaga ciągłej interwencji. Josh Tobin z Full Stack Deep Learning mówi wprost: "W prawdziwym świecie nigdy nie mamy do czynienia ze statycznymi rozkładami danych. Jeśli chcesz używać ML w produkcji, musisz myśleć o continual learning, nie o statycznym modelu."
Ten poradnik pokaże Ci, jak zbudować system, który uczy się na bieżąco - zanim biznes zacznie tracić pieniądze, a Ty nerwy.
Continual learning to podejście, w którym Twój model AI nie kończy nauki w momencie wdrożenia. Zamiast tego monitorujesz jego działanie, zbierasz nowe dane i regularnie go aktualizujesz. Brzmi oczywiste? W teorii tak. W praktyce większość zespołów wdraża model, sprawdza kilka predykcji ręcznie i idzie dalej.
Problem zaczyna się później. Dane w produkcji zmieniają się - użytkownicy zaczynają pisać inaczej, pojawiają się nowe trendy, zmieniają się wzorce zachowań. Twój model, wytrenowany na danych sprzed trzech miesięcy, zaczyna się mylić. Tylko że nikt tego nie zauważa, dopóki nie jest za późno.
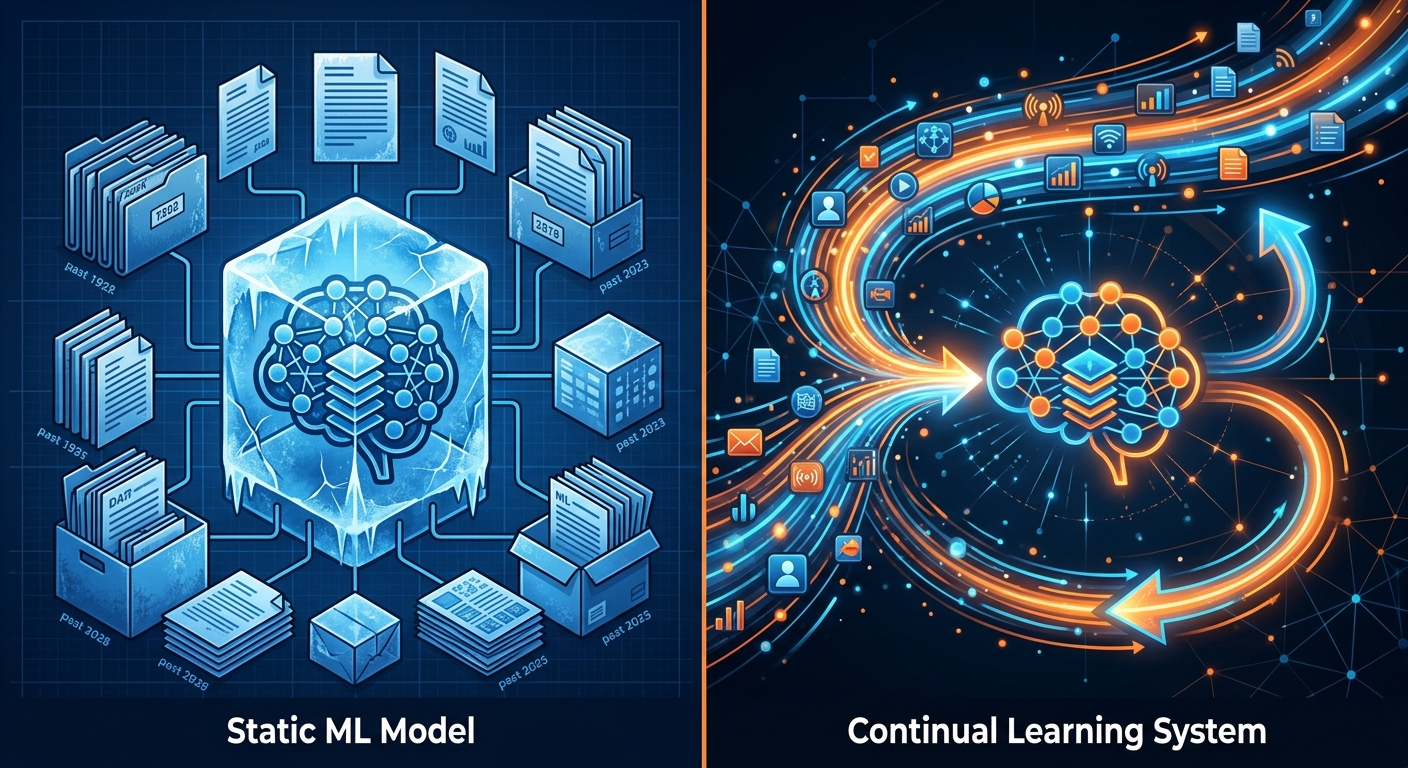
Andrej Karpathy opisał kiedyś wizję "Operation Vacation" - systemu continual learning tak dobrego, że inżynierowie ML mogą po prostu wyjechać na wakacje, a model sam się ulepsza. Dane napływają od użytkowników, model się uczy, przyciąga więcej użytkowników, zbiera więcej danych. Koło zamachowe kręci się samo.
Rzeczywistość? Najpierw zbierasz dane, czyścisz je, oznaczasz. Trenujesz model. Oceniasz. Poprawiasz. Wdrażasz. I dopiero wtedy zaczynają się prawdziwe problemy - bo nie masz dobrego sposobu na mierzenie, jak model radzi sobie w produkcji. Sprawdzasz kilka predykcji ręcznie. Jeśli wyglądają OK, idziesz dalej.
A kto odkrywa problemy? Nie Ty. Użytkownicy. Albo menedżer produktu, który widzi spadające metryki. Albo zespół biznesowy, który dostaje reklamacje. W tym momencie firma już traci pieniądze, a Ty musisz robić ad-hoc analizy, żeby zrozumieć, co poszło nie tak.
Zanim wdrożysz continual learning, upewnij się, że masz:
Jeśli nie masz któregoś z powyższych elementów, zacznij od tego. Bez nich continual learning to tylko teoria.
Pierwsza rzecz, którą robisz - definiujesz metryki systemowe. Nie chodzi tu o accuracy czy F1 score (te liczysz offline, na zbiorze testowym). Chodzi o metryki, które możesz mierzyć w produkcji, bez etykiet.
Zależy od typu modelu, ale typowe przykłady to:
Te metryki możesz zbierać bez etykiet. Nie powiedzą Ci, czy model się myli, ale pokażą, kiedy coś się zmienia. A zmiana to sygnał, że warto przyjrzeć się bliżej.
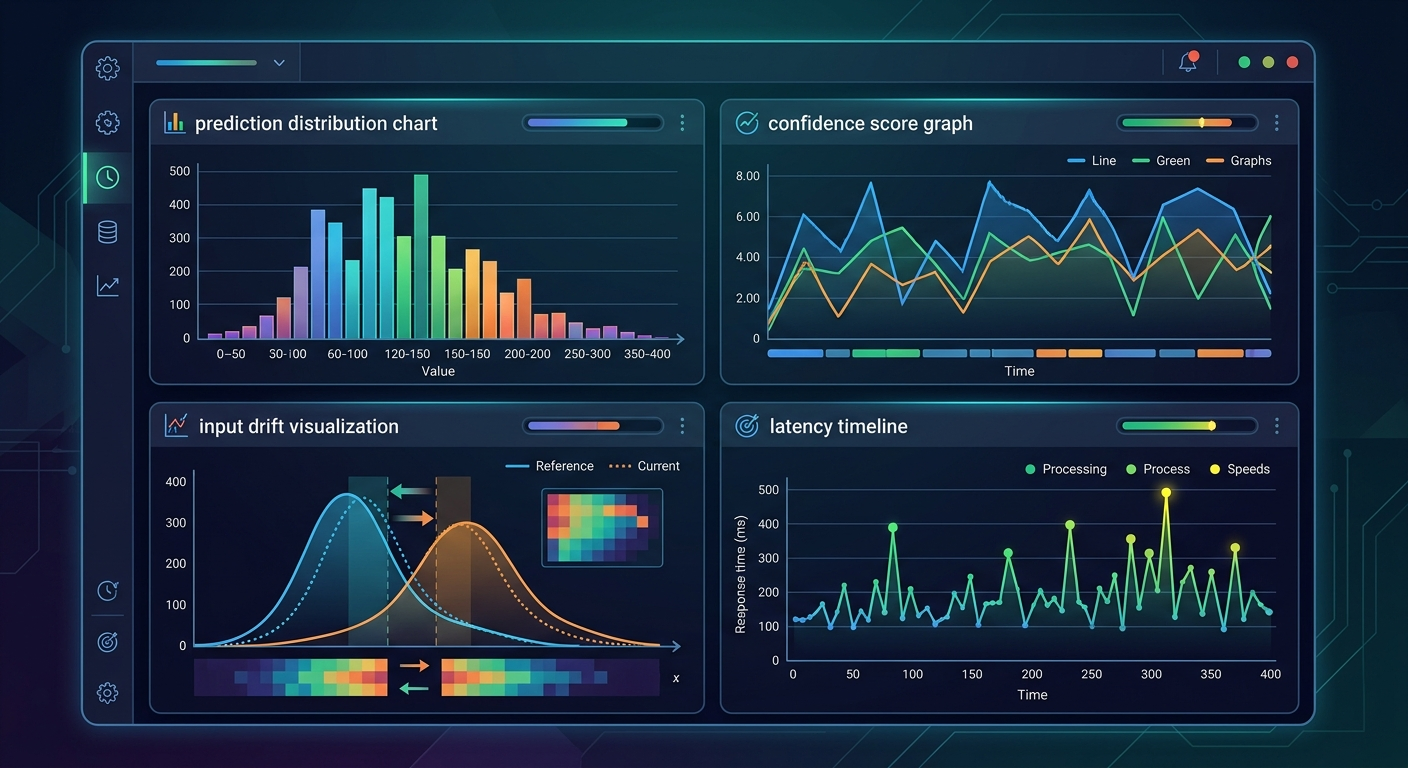
Nie ma uniwersalnego progu. Są dwa podejścia:
Kluczowe: nie czekaj, aż użytkownicy Ci powiedzą, że coś nie działa. Metryki systemowe to Twój early warning system. Jeśli chcesz dowiedzieć się więcej o tym, jak modele AI mogą się mylić, zajrzyj do artykułu o halucynacjach AI.
Teoria to jedno. Praktyka to drugie. Musisz wybrać konkretne narzędzia, które będą zbierać i wizualizować metryki.
Nie ma "najlepszego" narzędzia. Wybierz to, które pasuje do Twojego stacku i umiejętności zespołu. Ważniejsze niż narzędzie jest to, żebyś faktycznie patrzył na metryki regularnie - nie raz na kwartał, tylko co tydzień.
OK, masz metryki. Widzisz, kiedy coś się zmienia. Co teraz? Musisz zdecydować, kiedy i jak retrenować model.
Na początek? Zacznij od retreningu na żądanie. Jak zobaczysz anomalię w metrykach - wytrenuj nową wersję na świeżych danych. Przetestuj offline. Jeśli jest lepsza - wdróż. Z czasem możesz przejść na harmonogram lub triggery.
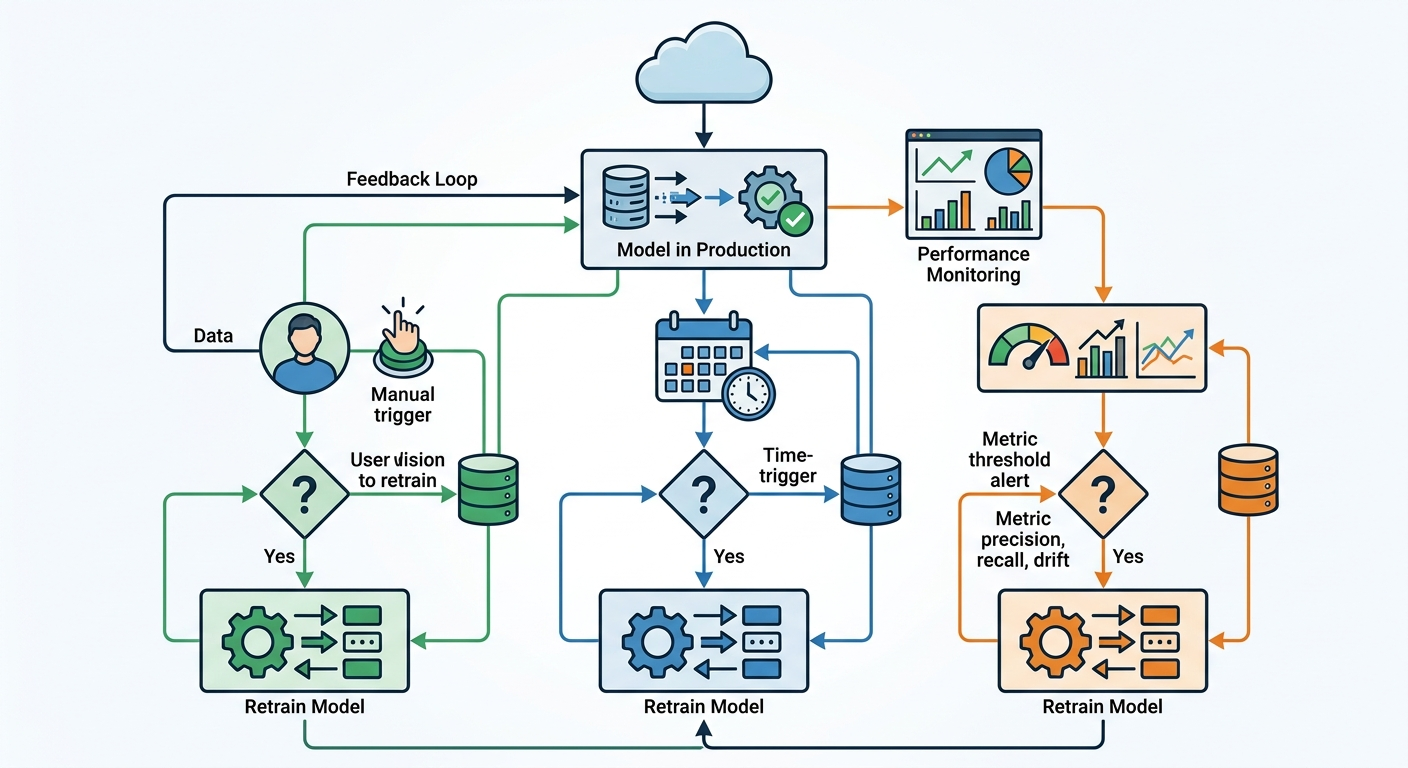
Zależy od tempa zmian w Twoich danych. Jeśli pracujesz z newsami - może codziennie. Jeśli z danymi medycznymi - może raz na kwartał. Nie ma uniwersalnej odpowiedzi. Zacznij od rzadszego retreningu (np. raz na miesiąc) i obserwuj, czy to wystarczy. Jeśli metryki spadają szybciej - zwiększ częstość.
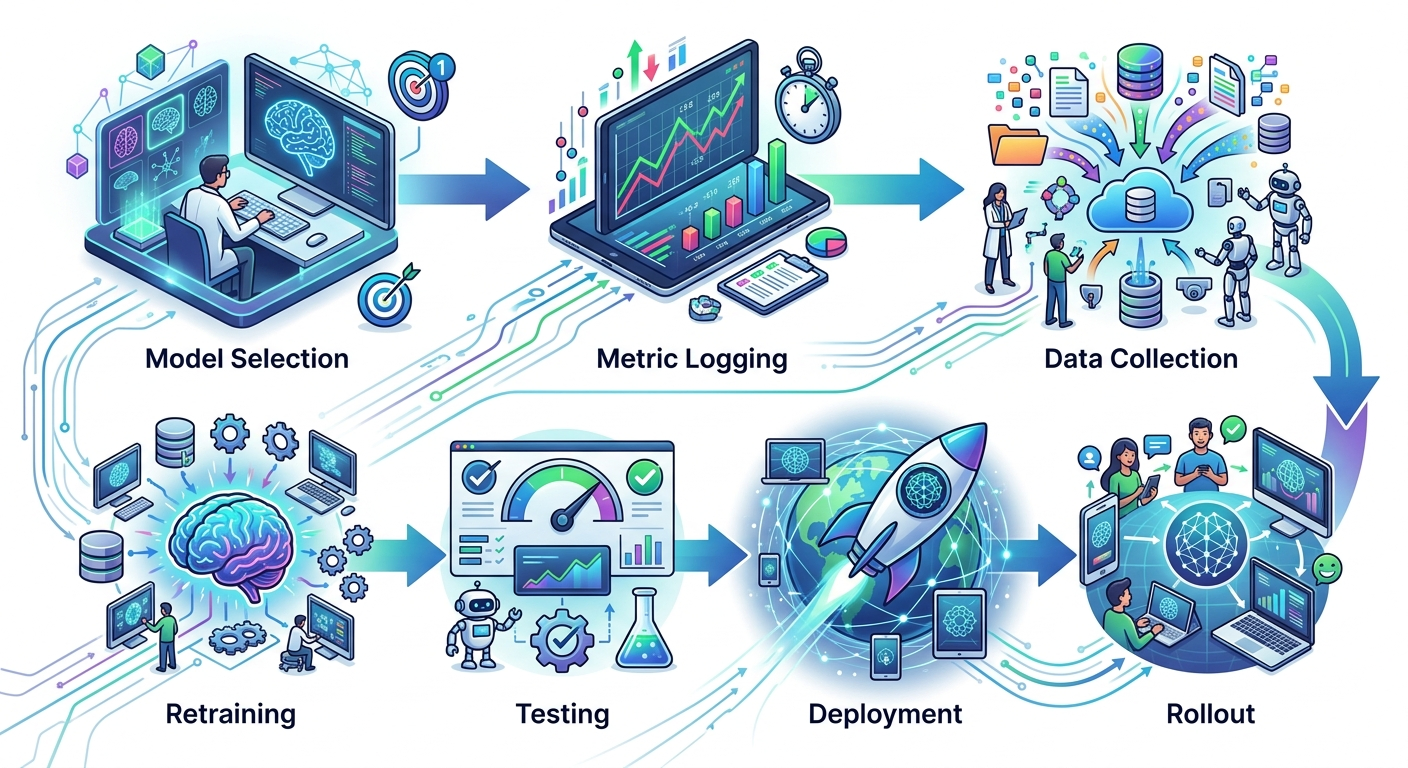
Continual learning to nie tylko retrening. To cały workflow, który łączy monitoring, zbieranie danych, trening i wdrażanie.
Ten workflow wymaga automatyzacji. Jeśli każdy krok robisz ręcznie - nie będziesz w stanie utrzymać regularnego rytmu. Zainwestuj czas w skrypty, które zautomatyzują zbieranie danych, trening i wdrażanie. To się zwróci.
Technologia to jedno. Ludzie to drugie. Continual learning nie działa, jeśli nikt nie jest za niego odpowiedzialny.
Ustaw jasno: kto sprawdza metryki (i jak często), kto decyduje o retreningu, kto wdraża nowe wersje. Jeśli to mały zespół - może być jedna osoba. Jeśli duży - może być rotacja. Musi być ktoś konkretny, nie "wszyscy".
Jeśli dopiero zaczynasz przygodę z machine learning i chcesz zrozumieć podstawy, zanim wdrożysz continual learning, przeczytaj nasz przewodnik po nauce ML od podstaw.
Nie próbuj wdrożyć pełnego systemu continual learning od razu. Zacznij od jednego modelu, jednej metryki, jednego cyklu retrening-wdrożenie.
Ten eksperyment pokaże Ci, gdzie są bottlenecki, co wymaga automatyzacji, ile czasu to zajmuje. Dopiero wtedy rozszerzaj na więcej modeli i bardziej złożone workflow.
Wytrenowałeś nową wersję modelu na świeżych danych. Wdrażasz od razu do produkcji. I okazuje się, że jest gorsza niż poprzednia. Użytkownicy dostają złe predykcje. Biznes traci pieniądze.
Rozwiązanie: Zawsze testuj nową wersję offline, na zbiorze testowym, zanim wdrożysz. Jeśli nie jest lepsza - nie wdrażaj. Proste.
Zbierasz dane produkcyjne. Część z nich to błędne predykcje Twojego modelu. Trenujesz nową wersję na tych danych. Model uczy się swoich własnych błędów. Robi się gorszy, nie lepszy.
Rozwiązanie: Filtruj dane przed treningiem. Jeśli masz feedback od użytkowników - używaj tylko tych danych, które zostały zweryfikowane. Jeśli nie masz feedbacku - oznaczaj próbkę danych ręcznie, żeby upewnić się, że są poprawne.
Twoje metryki systemowe wyglądają OK. Rozkład inputów zmienił się dramatycznie. Model dostaje dane, których nigdy nie widział podczas treningu. Predykcje są losowe, ale Ty tego nie widzisz, bo patrzysz tylko na metryki outputów.
Rozwiązanie: Monitoruj nie tylko outputy, ale też inputy. Jeśli rozkład danych wejściowych zmienia się znacząco - to sygnał, że model może potrzebować retreningu, nawet jeśli inne metryki wyglądają dobrze.
Poza narzędziami do monitoringu, które już wymieniłem, warto znać kilka innych:
Nie musisz używać wszystkich. Jeśli planujesz skalować continual learning na wiele modeli, te narzędzia oszczędzą Ci miesięcy pracy.
Jeśli interesuje Cię, jak działają nowoczesne modele AI pod maską, sprawdź nasz przewodnik po transformerach.
Czasami retrening nie rozwiązuje problemu. Model nadal się myli, mimo że trenujesz go na świeżych danych. Co wtedy?
Continual learning to nie silver bullet. To narzędzie, które pomaga utrzymać model aktualnym. Jeśli fundamenty są słabe - żaden retrening tego nie naprawi.
Nie ma uniwersalnej odpowiedzi. Zależy od tempa zmian w Twoich danych. Jeśli pracujesz z newsami lub trendami społecznościowymi - może codziennie lub co tydzień. Jeśli z danymi medycznymi lub finansowymi, które zmieniają się wolniej - może raz na miesiąc lub kwartał. Zacznij od rzadszego retreningu i zwiększaj częstość, jeśli metryki pokazują, że model szybko się dezaktualizuje.
Zależy od rozmiaru modelu i częstości retreningu. Jeśli masz mały model i trenujesz go raz na miesiąc - koszty będą minimalne. Jeśli masz duży model (jak GPT-class) i trenujesz codziennie - koszty mogą być znaczące. Dobrą praktyką jest zacząć od mniejszego modelu i rzadszego retreningu, a skalować dopiero gdy widzisz, że to działa i przynosi wartość biznesową.
Masz kilka opcji: wykorzystaj feedback użytkowników jako etykiety (np. thumbs up/down, kliknięcia), wdróż semi-supervised learning (model uczy się częściowo z nieoznaczonych danych), oznaczaj próbkę danych ręcznie lub przez crowdsourcing (np. 10% nowych danych co tydzień), lub użyj weak supervision - automatyczne oznaczanie na podstawie heurystyk i reguł biznesowych. Najważniejsze: nie trenuj na danych, których jakości nie zweryfikowałeś - to może pogorszyć model zamiast go ulepszyć.
Tak, ale w ograniczonym zakresie. Zacznij od prostego workflow: ręczny monitoring metryk co tydzień, retrening na żądanie gdy widzisz problem, wdrażanie przez istniejący pipeline. To nie będzie w pełni zautomatyzowane, ale da Ci 80% wartości continual learning przy 20% wysiłku. Z czasem, gdy zobaczysz wartość, możesz inwestować w automatyzację i narzędzia MLOps.
Zależy od typu modelu, ale uniwersalne to: rozkład predykcji (czy model nie faworyzuje jednej klasy), pewność predykcji (confidence scores), data drift (czy rozkład inputów się zmienia), latencja i throughput (czy model działa sprawnie), oraz - jeśli masz - metryki biznesowe (conversion rate, user satisfaction). Najważniejsze: śledź metryki, które możesz mierzyć bez etykiet, bo w produkcji rzadko masz natychmiastowy feedback.
Ten poradnik to dopiero początek. W naszym kursie "Praktyczna AI" nauczysz się korzystać z ChatGPT, Claude i innych narzędzi AI w sposób systematyczny - od zera do zaawansowanego poziomu.
Sprawdź kurs →Continual learning to nie akademicka ciekawostka. To konieczność, jeśli chcesz, żeby Twój model AI działał dłużej niż miesiąc. Zacznij od małego: jeden model, jedna metryka, jeden cykl retrening-wdrożenie. Zbieraj dane, monitoruj metryki, trenuj regularnie. Z czasem zautomatyzujesz proces i rozszerzysz na więcej modeli.
Pamiętaj: continual learning to maraton, nie sprint. Nie próbuj zbudować idealnego systemu od razu. Zacznij od minimum viable workflow i iteruj. Model, który się uczy na bieżąco, to model, który przetrwa.
Otwórz narzędzie do monitoringu (Weights & Biases, MLflow, albo nawet prosty spreadsheet). Wybierz jeden model w produkcji. Zacznij logować jedną metrykę - rozkład predykcji albo confidence scores. Rób to przez tydzień. Zobaczysz, jak dane zmieniają się w czasie. To pierwszy krok do continual learning.
Na podstawie: Full Stack Deep Learning - Lecture 6: Continual Learning
Podoba Ci się ten artykuł?
Co piątek wysyłam podsumowanie najlepszych artykułów tygodnia. Zapisz się!
90 minut praktycznej wiedzy o AI. Pokaze Ci krok po kroku, jak zaczac oszczedzac 10 godzin tygodniowo dzieki sztucznej inteligencji.
Zapisz sie na webinar
Chcesz nauczyć się uczenia maszynowego, ale nie wiesz od czego zacząć? Sprawdź darmowy kurs Microsoftu z 26 lekcjami i praktycznymi projektami.

Bias i variance to fundamenty uczenia maszynowego. Zrozumiesz je w 10 minut - ale opanowanie zajmie lata. Zacznij od podstaw, które działają.

Regresja logistyczna brzmi skomplikowanie, ale to podstawa AI, która działa w Twoim telefonie. Sprawdź, jak działa i gdzie ją wykorzystasz - bez matematyki.

Regresja liniowa dobrze sprawdza się na prostych danych. Ale co zrobić, gdy zależności nie układają się w linię prostą? Poznaj dwa rozszerzenia: regresję lokalnie ważoną i logistyczną.

Fine-tuning SpeechT5 to sposób, by model mowy rozumiał Twój głos, język czy akcent. Sprawdź, jak to zrobić bez kodowania i kiedy warto zainwestować czas.

Chcesz zrozumieć, jak naprawdę działają duże modele językowe? Zbuduj swój własny - krok po kroku, bez magii. Przewodnik dla osób bez doświadczenia w programowaniu.
