Poradniki
·
11 min czytania
·
4 maja 2026
Jak zbudować system RAG krok po kroku - przewodnik dla początkujących

Źródło: Link
Źródło: Link
118 lekcji bez kodowania. ChatGPT, Claude, Gemini, automatyzacje. Notatnik AI i AI Coach w cenie.
Duże modele językowe mają jeden problem: wiedzą tylko tyle, ile zapamiętały podczas treningu. Zapytaj GPT-5 o dane z Twojej firmy - dostaniesz grzeczną odmowę. Zapytaj o dokument, który właśnie dostałeś mailem - cisza. Model nie ma dostępu do Twoich plików, baz danych ani świeżych informacji.
Retrieval Augmented Generation (RAG) rozwiązuje ten problem. Zamiast polegać wyłącznie na pamięci modelu, RAG najpierw wyszukuje potrzebne informacje z zewnętrznych źródeł, a potem przekazuje je modelowi jako kontekst. Efekt? Model odpowiada na podstawie Twoich danych, nie ogólnej wiedzy z internetu.
W tym przewodniku pokażę Ci, jak działa RAG, jakie ma praktyczne zastosowania i jak możesz zacząć z nim pracować - nawet jeśli nigdy nie napisałeś linijki kodu.

RAG to skrót od Retrieval Augmented Generation. Rozbijmy to na czynniki pierwsze.
Retrieval (wyszukiwanie) - system przeszukuje Twoje dokumenty, bazy danych lub inne źródła i znajduje fragmenty najbardziej pasujące do pytania.
Augmented (wzbogacone) - znalezione informacje trafiają do modelu jako dodatkowy kontekst, wzbogacając jego wiedzę.
Generation (generowanie) - model tworzy odpowiedź na podstawie zarówno swojej wiedzy, jak i dostarczonych danych.
Przykład z życia: masz 500 stron dokumentacji technicznej swojego produktu. Klient pyta o konkretną funkcję. Zamiast przeszukiwać ręcznie wszystkie pliki, system RAG:
Różnica między zwykłym LLM a RAG? Zwykły model odpowiada: "Nie mam dostępu do dokumentacji Twojego produktu". RAG odpowiada: "Według dokumentacji z sekcji 3.2, ta funkcja działa następująco..."
RAG nie jest uniwersalnym rozwiązaniem. Ma sens, gdy:
RAG to przesada, gdy:
Jeśli Twoje pytanie można rozwiązać prostym wyszukiwaniem Ctrl+F, RAG prawdopodobnie nie jest Ci potrzebny. Jeśli masz setki plików i potrzebujesz inteligentnej syntezy informacji - to właśnie to narzędzie.
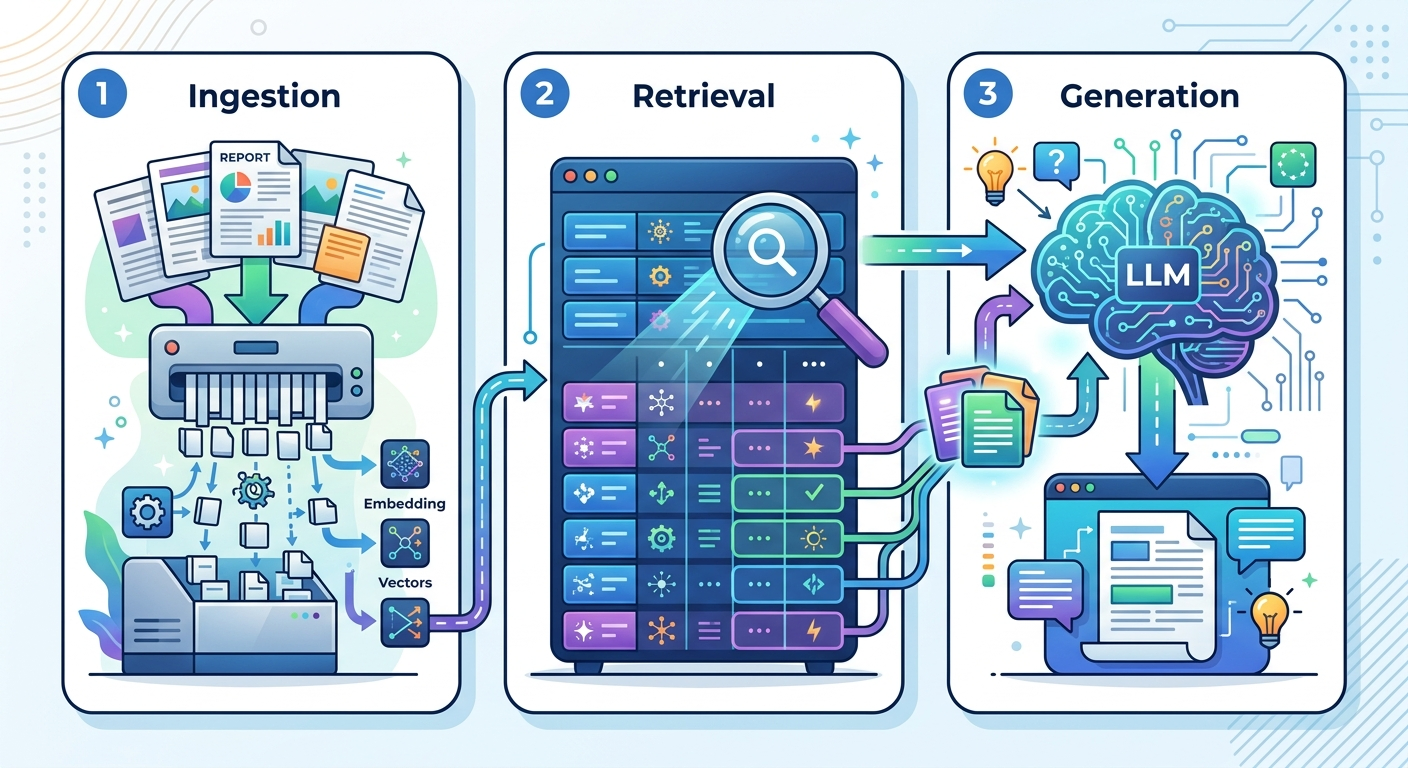
System RAG składa się z trzech głównych elementów. Nie musisz ich programować samodzielnie (istnieją gotowe narzędzia), ale warto rozumieć, co się dzieje w środku.
Zanim system zacznie odpowiadać na pytania, musisz "nakarmić" go dokumentami. To nie jest proste wrzucenie plików - dane przechodzą przez kilka etapów:
Przykład: masz instrukcję obsługi produktu. System dzieli ją na sekcje ("Instalacja", "Konfiguracja", "Rozwiązywanie problemów"), tworzy embeddingi i zapisuje w bazie. Teraz jest gotowy do wyszukiwania.
Gdy zadajesz pytanie, system:
To nie jest wyszukiwanie słów kluczowych. Jeśli zapytasz "jak naprawić błąd połączenia", system znajdzie fragmenty o "problemach z siecią" i "rozwiązywaniu awarii komunikacji" - nawet jeśli nie zawierają dokładnie tych słów.
Znalezione fragmenty trafiają do dużego modelu językowego jako kontekst. Prompt wygląda mniej więcej tak:
"Odpowiedz na pytanie użytkownika na podstawie poniższych fragmentów dokumentacji. Jeśli informacji nie ma w kontekście, powiedz to wprost. Cytuj źródła.
Kontekst: [fragment 1], [fragment 2], [fragment 3]
Pytanie: Jak naprawić błąd połączenia?"
Model analizuje kontekst i generuje odpowiedź. Jeśli system jest dobrze skonfigurowany, doda też źródła ("według sekcji 4.2...").
Teoria to jedno, ale co możesz zrobić z RAG w praktyce? Oto kilka scenariuszy, które działają już dziś.
Masz produkt SaaS i 200 stron dokumentacji. Klienci zadają te same pytania: "jak skonfigurować integrację", "gdzie znaleźć API key", "dlaczego nie działa webhook".
Zamiast płacić zespół supportu za odpowiadanie na powtarzalne pytania, budujesz chatbota RAG:
Efekt? 70% pytań obsługiwanych automatycznie, zespół supportu zajmuje się tylko skomplikowanymi przypadkami. Firmy jak Notion, Stripe czy Intercom już to robią.
Prawnik dostaje 50-stronicową umowę i musi znaleźć klauzule dotyczące odpowiedzialności. Zamiast czytać cały dokument, pyta system RAG:
System znajduje odpowiednie paragrafy i cytuje je dosłownie. Prawnik weryfikuje odpowiedzi (bo AI może się mylić), ale zamiast 2 godzin czytania, potrzebuje 20 minut przeglądu.
Podobnie działa to dla HR (przeszukiwanie CV), finansów (analiza raportów) czy compliance (sprawdzanie zgodności z regulacjami).
Twoja firma ma dokumenty rozproszone po Google Drive, Confluence, Notion, Slack i mailach. Nowy pracownik pyta: "Jak wygląda proces onboardingu klienta?"
Zamiast przeszukiwać 5 platform, używa wewnętrznego chatbota RAG, który:
Narzędzia jak Glean, Dashworks czy Hebbia robią dokładnie to. Oszczędność czasu? Nawet 5-10 godzin tygodniowo na pracownika.
Nie musisz być programistą, żeby zbudować prosty system RAG. Oto trzy ścieżki - od najprostszej do bardziej zaawansowanej.
Jeśli chcesz przetestować RAG bez pisania kodu, użyj gotowych platform:
Zacznij od ChatGPT lub Claude. Wgraj 5-10 dokumentów i zadaj kilka pytań. Zobaczysz, jak działa wyszukiwanie i generowanie odpowiedzi.
Jeśli potrzebujesz więcej kontroli, ale nadal bez kodowania:
Te narzędzia wymagają kilku godzin nauki, ale dają pełną kontrolę nad przepływem danych i konfiguracją modelu.
Jeśli znasz podstawy Pythona (lub chcesz się nauczyć), możesz zbudować RAG od zera:
Podstawowy system RAG w LangChain to ~50 linijek kodu. Nie jest to rocket science, ale wymaga zrozumienia podstaw programowania i API.
Jeśli dopiero zaczynasz, polecam naukę podstaw AI przed skokiem na głęboką wodę. RAG to zaawansowana technika - najpierw opanuj prompt engineering i automatyzację prostych zadań.
RAG brzmi prosto w teorii, ale w praktyce można się natknąć na kilka problemów. Oto najczęstsze i jak je obejść.
Jeśli Twoje dokumenty są chaotyczne, nieaktualne lub pełne błędów, RAG będzie generować takie same odpowiedzi. System nie weryfikuje prawdziwości - tylko wyszukuje i cytuje.
Rozwiązanie: Zanim wgrasz dane do systemu, uporządkuj je. Usuń zduplikowane pliki, zaktualizuj przestarzałe informacje, ujednolicaj formatowanie. To nudna robota, ale krytyczna dla jakości odpowiedzi.
Jeśli podzielisz dokumenty na zbyt małe fragmenty (np. 50 słów), stracisz kontekst. Jeśli na zbyt duże (np. 2000 słów), wyszukiwanie będzie nieprecyzyjne.
Rozwiązanie: Eksperymentuj z wielkością chunków. Standardem jest 200-500 słów z 10-20% nakładaniem się (overlap). Dla dokumentów technicznych - mniejsze chunki. Dla narracyjnych tekstów - większe.
Nawet z dobrym kontekstem, model czasem wymyśla fakty. Dlaczego? Bo został wytrenowany do generowania płynnego tekstu, nie weryfikowania prawdy.
Rozwiązanie: Dodaj do promptu instrukcję: "Odpowiadaj TYLKO na podstawie dostarczonych fragmentów. Jeśli informacji nie ma w kontekście, powiedz: 'Nie znalazłem tej informacji w dokumentacji'". To nie wyeliminuje halucynacji w 100%, ale znacznie je ograniczy.
Jeśli używasz Claude Opus 4.7 lub GPT-5 do każdego zapytania, rachunki mogą być spore. Opus kosztuje ~$15/$75 za milion tokenów (input/output), GPT-5 podobnie.
Rozwiązanie: Użyj tańszych modeli do wyszukiwania (np. DeepSeek V4-Flash - $0.14/$0.28 za milion tokenów), a droższych tylko do generowania finalnej odpowiedzi. Albo przejdź na open-source embeddingi (darmowe) zamiast API OpenAI.
Zależy od skali. Prosty system RAG dla 100-1000 dokumentów możesz uruchomić na laptopie lub tanim serwerze w chmurze (~$20/miesiąc). Dla milionów dokumentów i tysięcy użytkowników potrzebujesz dedykowanej infrastruktury i zespołu technicznego. Większość małych i średnich firm spokojnie zmieści się w pierwszym scenariuszu - albo użyje gotowych narzędzi SaaS, które skalują się automatycznie.
To dwa różne podejścia do tego samego problemu. Fine-tuning uczy model nowych wzorców (np. stylu pisania, specjalistycznej terminologii), ale nie dodaje nowych faktów - model nadal nie będzie znał Twoich dokumentów. RAG nie zmienia modelu, tylko dostarcza mu kontekst w czasie rzeczywistym. Często łączy się oba - fine-tuning dla stylu i domeny, RAG dla aktualnych danych.
Tak, ale z ostrożnością. Jeśli używasz API zewnętrznych dostawców (OpenAI, Anthropic), Twoje dane przechodzą przez ich serwery. Większość firm gwarantuje, że nie trenuje modeli na danych klientów, ale jeśli masz wymogi compliance (RODO, HIPAA), sprawdź umowy i certyfikaty. Alternatywa: używaj modeli open-source (Llama 4, DeepSeek V4) na własnej infrastrukturze - wtedy dane nigdy nie opuszczają Twojego serwera.
Prosty proof-of-concept z gotowymi narzędziami (ChatGPT, Notion AI) - kilka godzin. System low-code (Voiceflow, Stack AI) - 1-2 tygodnie. Produkcyjny system z własnym kodem i infrastrukturą - 1-3 miesiące, zależnie od złożoności i ilości danych. Największy koszt to nie technologia, tylko przygotowanie danych - czyszczenie, kategoryzacja, testowanie jakości odpowiedzi.
Nie całkowicie. Tradycyjne wyszukiwarki (Elasticsearch, Algolia) są szybsze i tańsze dla prostych zapytań ("znajdź wszystkie faktury z marca"). RAG ma sens, gdy potrzebujesz syntezy informacji z wielu źródeł ("podsumuj kluczowe ryzyka z umów z Q1"). W praktyce firmy często łączą oba - wyszukiwarka do filtrowania, RAG do generowania odpowiedzi.
Ten poradnik to dopiero początek. W naszym kursie "Praktyczna AI" nauczysz się korzystać z ChatGPT, Claude i innych narzędzi AI w sposób systematyczny - od zera do zaawansowanego poziomu.
Sprawdź kurs →RAG to konkretna technologia łącząca wyszukiwanie z generowaniem AI. Działa świetnie dla dokumentacji, obsługi klienta, analizy danych i wewnętrznych wyszukiwarek. Ma sens tam, gdzie masz dużo dokumentów i potrzebujesz inteligentnej syntezy informacji.
Najważniejsze? RAG to narzędzie, które możesz wdrożyć już dziś - bez zespołu programistów, bez budżetu korporacyjnego. Zacznij od prostego eksperymentu z ChatGPT lub Claude, wgraj kilka dokumentów, zadaj pytania. Zobaczysz, czy to rozwiązuje Twój problem.
Otwórz ChatGPT Plus lub Claude Pro. Wgraj 3-5 dokumentów z Twojej pracy (raporty, procedury, notatki). Zadaj 10 pytań, na które normalnie musiałbyś przeszukiwać te pliki ręcznie. Sprawdź, jak system radzi sobie z wyszukiwaniem i generowaniem odpowiedzi. To zajmie Ci 15 minut i pokażesz, czy RAG ma sens w Twoim przypadku.
Na podstawie: SukcesAI Course Material Generator
Podoba Ci się ten artykuł?
Co piątek wysyłam podsumowanie najlepszych artykułów tygodnia. Zapisz się!
90 minut praktycznej wiedzy o AI. Pokaze Ci krok po kroku, jak zaczac oszczedzac 10 godzin tygodniowo dzieki sztucznej inteligencji.
Zapisz sie na webinar
Podział dokumentów na fragmenty to fundament skutecznego RAG. Dowiedz się, jak to zrobić praktycznie - od wyboru strategii po testowanie wyników.

Fine-tuning SpeechT5 to sposób, by model mowy rozumiał Twój głos, język czy akcent. Sprawdź, jak to zrobić bez kodowania i kiedy warto zainwestować czas.

Automatyczne powiadomienia Slack od agentów AI brzmią jak science fiction? Już nie. Pokazuję krok po kroku, jak połączyć workflow AI z komunikacją zespołową - bez kodowania.

Transformery to silnik każdego dużego modelu językowego. Wyjaśniamy prostym językiem, jak GPT-5, Claude Opus 4.7 czy DeepSeek V4-Pro rozumieją kontekst i generują odpowiedzi.

Platformy, integracje i najlepsze praktyki wdrożenia chatbotów AI nowej generacji. Przewodnik dla firm, które chcą zautomatyzować obsługę bez utraty jakości kontaktu.

Uczenie przez wzmacnianie sprawia, że ChatGPT rozumie kontekst, a nie tylko składa słowa. Wyjaśniamy krok po kroku, jak to działa i dlaczego ma znaczenie.
