Poradniki
·
9 min czytania
·
25 kwietnia 2026
Jak zrozumieć transformery AI dzięki Jayowi Alammarowi

Źródło: Link
Źródło: Link
118 lekcji bez kodowania. ChatGPT, Claude, Gemini, automatyzacje. Notatnik AI i AI Coach w cenie.
Czy da się zrozumieć serce ChatGPT, Claude czy Gemini bez doktoratu z matematyki? Da się. Właśnie dlatego materiał Jay'a Alammara od lat robi taką robotę: pokazuje transformery AI bez akademickiej mgły, za to z obrazami, które wreszcie układają temat w głowie.
OK, rozbijmy to na czynniki pierwsze. Jeśli AI kojarzy Ci się z czarną skrzynką, która „po prostu coś generuje”, ten poradnik jest po to, żeby odczarować mechanizm. Bez kodu. Bez wzorów. Bez udawania, że każdy od razu chce czytać artykuł naukowy z 2017 roku do poduszki.
Ten poradnik jest dla Ciebie, jeśli znasz już narzędzia typu ChatGPT albo Gemini, ale chcesz wejść poziom głębiej i zrozumieć, na czym stoją duże modele językowe LLM. Nie potrzebujesz doświadczenia technicznego, tylko kilku prostych rzeczy:
Jeśli wcześniej czytałaś lub czytałeś nasz tekst o tym, jak duże modele językowe przechowują fakty, ten poradnik dobrze domknie Ci obraz. Tam patrzyliśmy na pamięć modelu, tutaj patrzymy na jego mechanikę.

Większość ludzi zna efekt: wpisujesz polecenie, model odpowiada. Czasem błyskotliwie, czasem dziwnie pewny siebie mimo błędu (klasyka). Problem zaczyna się wtedy, gdy chcesz zrozumieć, dlaczego nowoczesne modele są tak dobre w języku.
Starsze podejścia do generowania tekstu, jak RNN, przetwarzały słowa bardziej sekwencyjnie - krok po kroku. To działało, miało jednak ograniczenia. Im dłuższe zdanie, tym trudniej było utrzymać sens i relacje między odległymi fragmentami. Jeśli chcesz zobaczyć, z czego AI „wyrosło”, zerknij też na nasz materiał jak nauczyć sieć neuronową pisać teksty - przewodnik RNN. Dobrze widać tam, dlaczego transformery wygrały.
Transformer, opisany w pracy Attention Is All You Need, zmienił zasady gry w bardzo konkretny sposób: model zaczął patrzeć na wiele słów naraz i oceniać, które elementy zdania są dla siebie istotne. Dzięki temu trenowanie przyspieszyło, a jakość zrozumienia kontekstu skoczyła mocno do przodu.
Jay Alammar nie próbował imponować złożonością. Zrobił coś cenniejszego: rozrysował cały proces tak, żeby człowiek spoza ML mógł śledzić przepływ informacji krok po kroku. Właśnie dlatego jego materiał trafił do kursów na Stanfordzie, MIT, Harvardzie, Princeton i CMU. Nie chodzi o to, że jest „ładny”. Dlatego, że jest użyteczny.
Jeśli wpisujesz w Google jak działa jay alammar illustratedtransformer, to zwykle szukasz jednej z dwóch rzeczy: prostego wejścia do tematu albo sposobu, żeby uporządkować chaos po obejrzeniu dziesięciu filmów o AI. Ten materiał daje oba.
W 2026 roku nadal ma sens, mimo że same modele poszły dalej. Dziś rozmawiamy o GPT-5, Claude Opus 4.7, Gemini 3.1 Pro, DeepSeek V4-Pro czy Llama 4 Scout. Architektury mają już nowsze dodatki, jak RoPE czy Multi-Query Attention, rdzeń myślenia o transformerze dalej jest jednak ten sam: uwaga, relacje między tokenami i równoległe przetwarzanie.
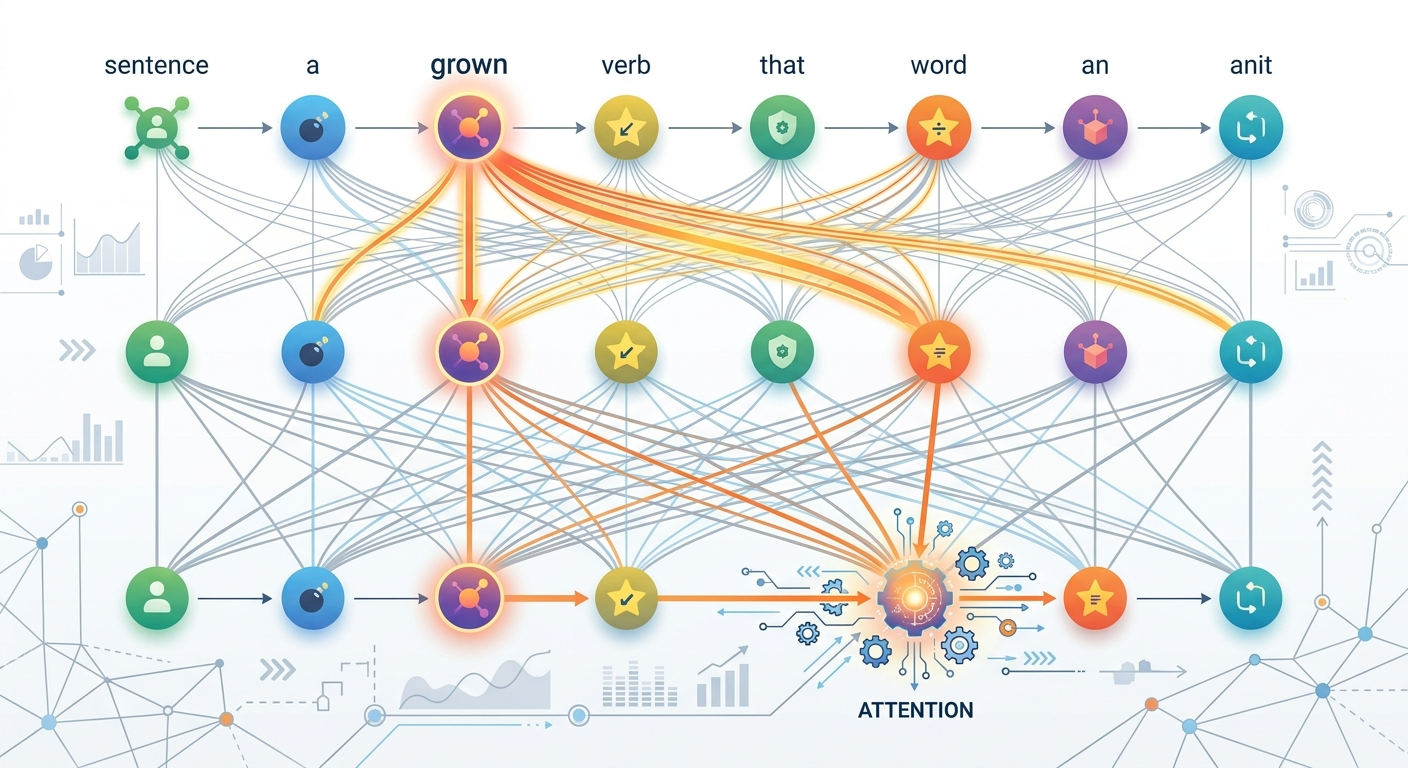
Żeby ten temat przestał być mglisty, potraktuj transformera nie jako „wielki model AI”, tylko jako sekwencję prostych operacji. Poniżej masz wersję uproszczoną, wierną logice materiału Alammara.
Weź zdanie: „Ala oddała Kindze książkę, bo już ją przeczytała.” Słowo „ją” nie jest jasne samo z siebie. Model musi ustalić, czy chodzi o Kingę, czy o książkę. Mechanizm attention pozwala mu sprawdzić, które wcześniejsze słowa są najbardziej powiązane z tym fragmentem. W tym zdaniu sens prowadzi do „książki”.
To samo dzieje się w tłumaczeniach, streszczeniach i odpowiedziach chatbotów. Model nie leci ślepo od lewej do prawej. Patrzy na zależności.
Drugi przykład: wpisujesz do modelu prośbę o mail do klienta „formalny, ale nie sztywny”. Dla człowieka to drobiazg. Dla modelu to zestaw sygnałów, które wpływają na dobór słów, tonu i struktury. Attention pomaga mu zrozumieć, że „formalny” i „nie sztywny” mają działać razem, a nie się wykluczać.
Trzeci przykład jest biznesowy. Wrzucasz dłuższy opis produktu i prosisz o reklamę na LinkedIn. Transformer analizuje, które fragmenty wejścia są kluczowe: grupa docelowa, korzyść, ograniczenia, styl wypowiedzi. Stąd nowoczesne modele są tak użyteczne w marketingu, sprzedaży czy edukacji.
Jeśli interesuje Cię, jak z tej architektury wyrastają bardziej „samodzielne” systemy, przeczytaj też jak budować agentów AI, którzy piszą i uruchamiają kod. Agent to nie magia. To zwykle model oparty na transformera plus narzędzia i reguły działania.
Sam materiał Alammara jest świetny, wiele osób odbija się od niego jednak Powodem jest to, że czyta go jak news. Tu trzeba wejść bardziej aktywnie. Poniżej masz prosty plan.

Tu jest konkret. Gdy rozumiesz podstawy transformera, lepiej korzystasz z narzędzi AI na co dzień:
To przydaje się także w polskich firmach. Jeśli wdrażasz AI do obsługi klienta, marketingu czy edukacji, podstawowe zrozumienie działania modelu pomaga uniknąć dwóch skrajności: ślepego zachwytu i ślepej paniki. Jedno i drugie kosztuje czas oraz pieniądze.
Jeśli patrzysz na AI bardziej operacyjnie, zajrzyj też do poradnika jak wdrożyć AI w małej firmie bez budżetu na IT. Tam pokazujemy, jak przekładać wiedzę o modelach na realne procesy. Z kolei tekst jak działa uczenie ze wzmocnieniem w dużych modelach językowych pokaże Ci, co dzieje się później - już po samej architekturze, gdy model uczy się odpowiadać „bardziej po ludzku”.
Werdykt jest prosty: materiał Jay'a Alammara nadal jest jednym z najlepszych wejść do świata transformerów. Wyjaśnia to, co najważniejsze, bez robienia z czytelnika statysty w cudzym doktoracie.
Tak. Dzisiejsze modele, takie jak GPT-5, Claude Opus 4.7, Gemini 3.1 Pro czy DeepSeek V4-Pro, mają nowsze usprawnienia, podstawowa logika transformera nadal jednak pozostaje kluczowa. Ten materiał dobrze tłumaczy fundament.
Nie. Na poziomie ogólnego zrozumienia wystarczy śledzić schemat: tokeny, pozycje, attention, przewidywanie kolejnego tokena. Matematyka przydaje się dopiero wtedy, gdy chcesz budować lub trenować modele.
Dzięki temu lepiej korzystasz z narzędzi AI, lepiej oceniasz ich ograniczenia i łatwiej odróżniasz realną wartość od marketingowego dymu. To wiedza praktyczna, nie tylko „dla geeków”.
W kursie "Praktyczna AI" na sukcesai.com omawiamy ten temat szczegółowo - z ćwiczeniami, przykładami i wsparciem. Zamiast zgadywać, naucz się AI krok po kroku.
Sprawdź kurs →Jeśli do tej pory transformer był dla Ciebie mętnym hasłem z internetowych dyskusji, teraz masz już mapę. Jeden krok na start: otwórz artykuł Jay'a Alammara i przeczytaj go dziś tylko pod kątem jednego pytania - na co model zwraca uwagę, kiedy czyta zdanie? Tyle wystarczy, żeby temat wreszcie zaczął się układać.
Na podstawie: Jay Alammar - The Illustrated Transformer
Podoba Ci się ten artykuł?
Co piątek wysyłam podsumowanie najlepszych artykułów tygodnia. Zapisz się!
90 minut praktycznej wiedzy o AI. Pokaze Ci krok po kroku, jak zaczac oszczedzac 10 godzin tygodniowo dzieki sztucznej inteligencji.
Zapisz sie na webinar
Claude i ChatGPT to dwa najpopularniejsze chatboty AI. Sprawdź, który wybrać do pisania, kodowania, analizy danych i codziennej pracy - z konkretnymi przykładami użycia.

Generowanie postów, grafik i harmonogramów publikacji z pomocą AI. Konkretne narzędzia i praktyczne wskazówki dla osób, które chcą działać szybciej bez utraty jakości.

Sora, Runway Gen-3, Kling, Veo 2 - cztery narzędzia, cztery filozofie generowania wideo. Sprawdzamy, które pasuje do Twojego projektu i ile faktycznie zapłacisz.

Transformery to silnik każdego dużego modelu językowego. Wyjaśniamy prostym językiem, jak GPT-5, Claude Opus 4.7 czy DeepSeek V4-Pro rozumieją kontekst i generują odpowiedzi.

Fast tokenizery mogą przyspieszyć pipeline RAG nawet 10-krotnie. Sprawdź, jak działają, kiedy mają sens i jak je wdrożyć krok po kroku.

Konkretne zastosowania AI w content marketingu, SEO, social media, email marketingu i analityce. Praktyczny przewodnik bez buzzwordów.
